LinkedIn Open-Sources ‘Feathr’, It’s Feature Store To Simplify Machine Learning (ML) Feature Management And Improve Developer Productivity
This article summary is based on the LinkedIn's research article: 'Open sourcing Feathr – LinkedIn’s feature store for productive machine learning' Please don't forget to join our ML Subreddit
LinkedIn research team has recently open-sourced feature store, Feathr, created to simplify machine learning (ML) feature management and increase developer productivity. Feathr is used by dozens of LinkedIn applications to define features, compute them for training, deploy them in production, and share them across consumers. Compared to previous application-specific feature pipeline solutions, Feathr users reported significantly reduced time required to add new features to model training and improved runtime performance.
Hundreds of ML models run on LinkedIn in Search, Feed, and Ads applications. Thousands of features about entities in the Economic Graph, such as companies, job postings, and LinkedIn members, power the models. The most time-consuming aspects of handling the ML applications at scale have been preparing and managing features.

Because each team had its own pipeline, the cost of building and maintaining feature pipelines was shared by many groups. And as new features and capabilities were added over time, pipeline complexity increased. Team-specific pipelines also made reusing features across projects impractical. There is no uniform way to name parts across models, no consistent type system for features, and no consistent way to deploy and serve features in production without a common abstraction. Custom pipeline architectures made work-sharing prohibitively tricky.
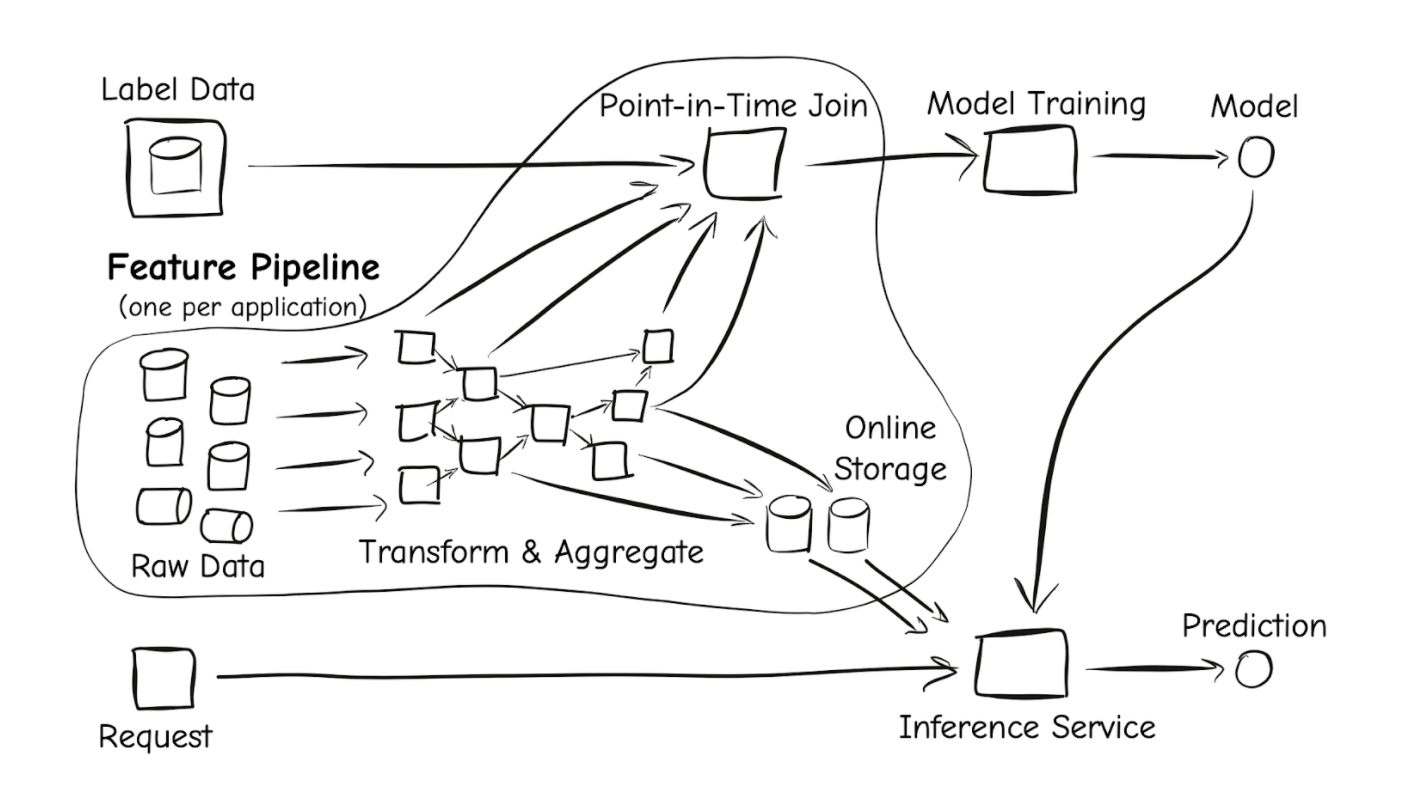
Teams were becoming overburdened with the rising costs of maintaining their feature preparation pipelines, which was hampering their productivity in innovating and improving their applications. Feature preparation pipelines, which are the systems and workflows that convert raw data into features for model training and inference, are complex. They must collect time-sensitive data from multiple sources, join the features to training labels in a point-in-time manner, and persist the features in store for low-latency online serving. They must also ensure that features are prepared consistently for the training and inferencing contexts to avoid training-serving skew.

Feathr addressed these issues. Feathr is a layer that provides a unified feature namespace for defining features and a unified platform for serving, computing, and accessing them “by the name” from within ML workflows. Feathr eliminates the need for individual teams to manage customized feature pipelines and allows features to be easily shared across projects, increasing ML productivity. Feathr is a feature store, a term that has recently emerged to describe systems that manage and serve ML feature data. While many industry solutions are primarily concerned with feature data management and serving, Feathr also provides advanced support for feature transformations, allowing users to experiment with new features based on raw data sets.
Feathr’s abstraction generates feature producer and consumer personas. Producers create features and register them in Feathr, while consumers access/import feature groups into their ML model workflows. The same engineer frequently plays both roles, producing and consuming features for their own project.
Feathr can be thought of as a software package management tool for ML features from the consumer’s perspective. Engineers in modern software development rarely consider how dependency library artifacts are fetched, transitive dependencies are resolved, or dependency libraries are linked to the code for compilation or execution. Instead, engineers simply provide a list of the names of the dependency modules they want to include, include, or import into the code, and the build system handles the rest. Similarly, Feathr allows feature consumers to specify the names of the features they want to “import” into the model, abstracting the nontrivial details of how they are sourced and computed.
Feathr figures out how to provide the asked feature data in the required format for model training and production inferencing under the hood. Features are computed and correctly joined to input labels for model training. Features are pre-materialized and deployed to online data stores for low-latency online serving for model inferencing. Attributes defined by different teams and projects can be easily combined, allowing for collaboration and reuse.
On the producer side, Feathr allows defining and registering features based on raw data sources (including time-series data) or other Feathr features using simple expressions. For more complex use cases, user-defined functions are supported. Aggregations, transformations, time windowing, and a rich set of types, including vectors and tensors, are all backed by Feathr, making it simple to define many different types of features based on the underlying data. Feathr materializes feature datasets and deploys them to online data stores for quick access to model inference.
Some of the largest ML projects of LinkedIn removed significant amounts of code by replacing application-specific feature preparation pipelines with Feathr — this reduced the engineering time required for adding and experimenting with new features from weeks to days.
Feathr outperformed the custom feature processing pipelines it replaced by up to 50%, effectively amortizing investments in Feathr runtime optimization. Feathr also allows similar applications to share features. LinkedIn, for example, has several search and recommendation systems that deal with data about job postings. Previously, these projects had difficulty communicating features due to application-specific pipeline architectures, but with Feathr, they could share features easily, resulting in significant improvements in business metrics.
Feathr can handle petabytes of feature data in large-scale applications. Feathr has laid the groundwork for feature registration, computation, and deployment. One of the favorite examples is enabling next-level CI/CD for feature engineering, which will allow users to create upgraded versions of widely-shared ML features, which will then be automatically tested against existing models that rely on that feature.
The most-used core components of Feathr are open-source now. Check out the GitHub page for examples of using Feathr to define features based on raw data, compute feature values for training, and deploy components to production for online inference.
Github: https://github.com/linkedin/feathr
Reference: https://engineering.linkedin.com/blog/2022/open-sourcing-feathr—linkedin-s-feature-store-for-productive-m
Credit: Source link
Comments are closed.