LinkedIn Researchers Open-Source ‘FastTreeSHAP’: A Python Package That Enables An Efficient Interpretation of Tree-Based Machine Learning Models

Researchers from LinkedIn open-source the FastTreeSHAP package which is a Python module based on the paper ‘Fast TreeSHAP: Accelerating SHAP Value Computation for Trees.’ Implementing the widely-used TreeSHAP algorithm in the SHAP package allows for the efficient interpretation of tree-based machine learning models by estimating sample-level feature significance values. Its package includes two new algorithms: FastTreeSHAP v1 and FastTreeSHAP v2, both of which improve TreeSHAP’s computational efficiency by taking a different approach.
The empirical benchmarking tests show that FastTreeSHAP v1 is 1.5x faster than TreeSHAP while keeping memory costs the same, and FastTreeSHAP v2 is 2.5x faster while using slightly more memory. The FastTreeSHAP package fully supports parallel multi-core computing to speed up its computation.
In today’s sector, predictive machine learning models are widely used. Predictive models to improve the member experience across various member-facing products, including People You May Know (PYMK), newsfeed ranking, search, job suggestions, and customer-facing products, particularly sales and marketing, are constructed. Complex models, such as gradient boosted trees, random forest, and deep neural networks, are extensively utilized among these models because of their high prediction accuracy. One of the most essential aspects is figuring out how these models function (a.k.a. model interpretation), which is problematic given how opaque these models are.
Understanding input contributions to model output (i.e., feature reasoning) is one of the critical approaches in constructing transparent and explainable AI systems. Often, the interpretations at the individual sample level are of particular relevance. The following are a few examples of sample-level model interpretation:
- Sample-level feature reasoning is critical for model end-users (such as sales and marketing teams) in the predictive business models, such as customer acquisition and churn models, to ensure trust in prediction results. It allows them to create meaningful insights and actionable items, which leads to improvements in our key business metrics.
- The recruiter search models can use sample-level feature reasoning to answer why candidate 1 is higher than candidate 2. It can also assist model developers in debugging and improving the model’s performance.
This feature is not enabled on the LinkedIn website but is on the to-do list. Sample-level feature reasoning is critical for achieving job search models’ legal and regulatory compliance goals. It may also help ensure that the job recommendation algorithms are fair to LinkedIn members.
SHAP, LIME, and Integrated Gradient are examples of state-of-the-art sample-level model interpretation techniques. SHAP (Shapley Additive exPlanation) is one of them. It uses concepts from game theory and local explanations to produce SHAP values, which quantify the contribution of each feature. SHAP evaluates the average effect of adding an element to the model by considering all potential subsets of the other components.
SHAP has been justified as the only constant feature attribution strategy with multiple unique qualities (local accuracy, missingness, and consistency) that fit human intuition, in contrast to other approaches. Due to its solid theoretical assurances, it has become a top model interpretation approach. Please see this paper for further technical information on SHAP.

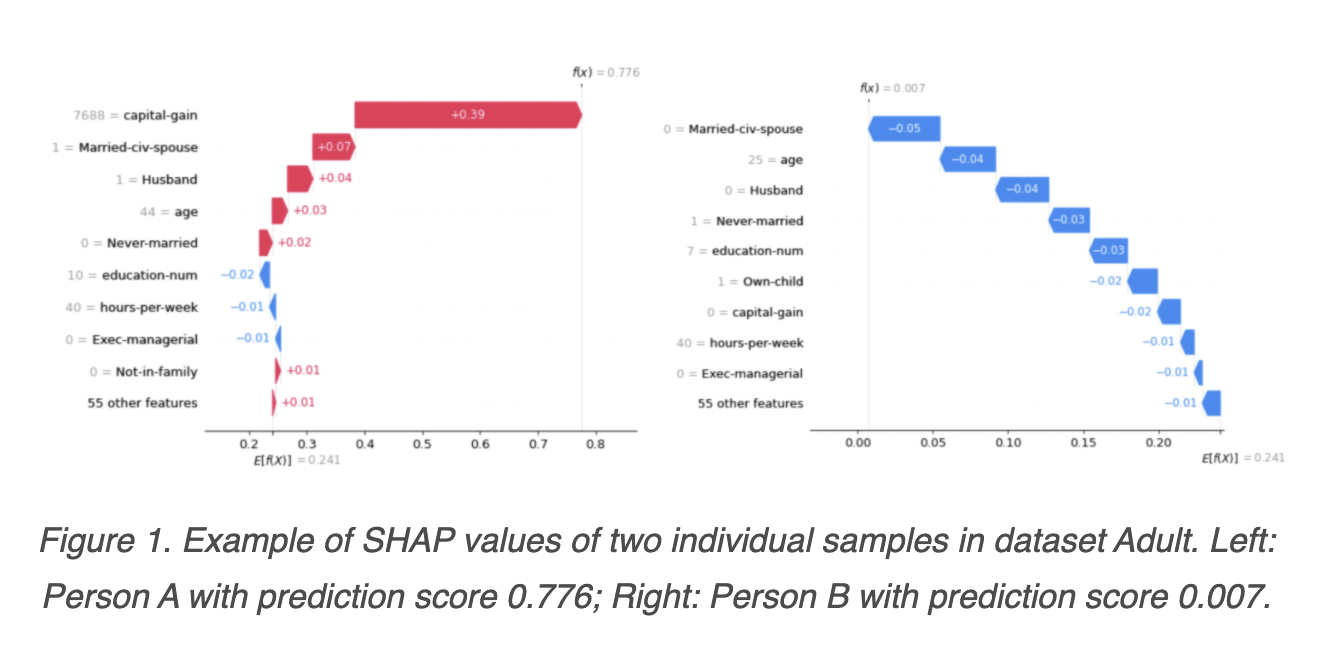
Figure 1 depicts a typical example of SHAP values from two individual samples in the public dataset Adult. The prediction job is to assess whether a person earns more than $50K per year based on marital status, educational status, capital gain and loss, and age.
Person A has a prediction score of 0.776, significantly higher than the average prediction score of 0.241, indicating a strong possibility of earning more than $50,000 per year. The top driving features are shown in order of absolute SHAP values, with the red bar representing a positive value and the blue bar representing a negative value. The high financial gain and marital status (married with a civilian spouse) contribute the most to Person A’s high prediction score, as seen on the left plot.
Similarly, a prediction score of 0.007 for Person B in the right plot suggests a very low possibility of earning more than $50K per year, mainly influenced by this person’s marital status (single) and young age.
Despite solid theoretical assurances and a wide range of use cases for SHAP values, one of the primary challenges in SHAP implementation is computation time—the exact SHAP values computation time grows exponentially with the features in the model. TreeSHAP is optimized for tree-based models (e.g., decision trees, random forests, and gradient boosted trees) when computing the exact SHAP values takes polynomial time. Only the root-to-leaf paths in the trees that include the target feature and all subsets within these paths are considered for the polynomial-time complexity. Please see this paper for further technical information on TreeSHAP.
Despite its algorithmic complexity increase, computing SHAP values for significant sample size or a large model size (e.g., tree depth >= 8) remains a computational worry in reality, according to the research. Experiments have shown, for example, that explaining 20 million data can take up to 30 hours, even on a 50-core server. This is a concern since user-level prediction models in business, such as feed ranking models, job search models, and subscription propensity models, frequently require the explanation of (at least) tens of millions of data.
Spending tens of hours on model interpretation in specific modeling processes represents a substantial bottleneck. It’s likely to cause significant delays in post-hoc model diagnosis via crucial feature analysis, increasing the chances of inaccurate model implementations and model revisions. It can result in extended wait periods for model end-users (e.g., a marketing team using a subscription propensity model) to prepare actionable items based on feature reasoning. As a result, end-users may not take necessary actions promptly, negatively impacting a company’s income.
Here comes the FastTreeSHAP package to the rescue.
The time and space complexities of all variants of the TreeSHAP algorithm are summarised in Table 1.
M – number of samples to be explained
T – number of trees
L – maximum number of leaves in any tree
N – number of features
D – full depth of any tree

Although the temporal complexity of FastTreeSHAP v1 appears to be the same as that of TreeSHAP, the theoretical mean running time of FastTreeSHAP v1 is just 25% that of TreeSHAP.
Also, the time complexity of FastTreeSHAP v2 may be decomposed into two parts, the second of which is only relevant to the number of samples M and reduces the time complexity by a factor of D of TreeSHAP and FastTreeSHAP v1.
v1 of FastTreeSHAP
The main improvement in FastTreeSHAP v1 is that the computation scope of the set of features has been reduced. FastTreeSHAP v1 only considers features that satisfy the split rules along the path, whereas TreeSHAP analyses all features in each root-to-leaf path. The characteristics along the path and their accompanying thresholds define the split rules.
Half of the features along each root-to-leaf path must fulfill the split rules on average for a particular sample to be explained. This reduces the constant associated with tree depth D by 50%, reducing the temporal complexity endless of FastTreeSHAP v1 O(MTLD2) by 25%.
v2 of FastTreeSHAP
FastTreeSHAP v2’s general concept is to trade space complexity for temporal complexity. It is inspired by the fact that the most expensive TreeSHAP step, calculating the weighted sum of the proportions of all feature subsets, yields consistent results across samples (more details in the original paper). Part I, FastTreeSHAP-Prep, calculates all possible outcomes of this time-consuming TreeSHAP step in advance and saves them in an L x 2D matrix. Part II, FastTreeSHAP-Score, then uses the pre-computed matrix to determine SHAP values for incoming samples.
FastTreeSHAP v2’s space complexity is dominated by the pre-computed matrix, which is O(1) (L2D).
In conclusion, FastTreeSHAP v1 outperforms TreeSHAP. When you have a very large number of samples, which is frequent in a moderate-sized dataset, for example, M > 57 when D = 8, M > 630 when D = 12, and M > 7710 when D = 16 (most tree-based models output trees with depth 16), FastTreeSHAP v2 outperforms FastTreeSHAP v1.
Furthermore, FastTreeSHAP v2 has a tougher memory limitation: O(L2D) memory tolerance; however, this constraint is pretty flexible. The SHAP values produced by FastTreeSHAP v1 and FastTreeSHAP v2 are identical to those produced by TreeSHAP.
The user interface of the FastTreeSHAP package is versatile and intuitive, and it is based on the SHAP package. A basic illustration of how FastTreeSHAP works are shown in the following snippet:
FastTreeSHAP’s user interface is identical to that of SHAP, except for three new arguments in the class “TreeExplainer”: “algorithm,” “n jobs,” and “shortcut.” If users are already familiar with SHAP, they should have no trouble utilizing FastTreeSHAP.
The “treeSHAP algorithm” specifies which TreeSHAP algorithm to apply.
It can be “v0,” “v1,” “v2,” or “auto,” with the first three corresponding to original TreeSHAP, FastTreeSHAP v1, and FastTreeSHAP v2. Its default option is “auto,” which automatically selects from “v0,” “v1,” and “v2” algorithms based on the samples to be explained and the allotted memory constraint. “v1” is always preferred over “v0” in all use cases. “v2” is selected over “v1” when the number of samples to be explained is large enough (M > 2D+1/D). The memory restriction is met (min(MN + L2D) C, TL2D 8B 0.25Total Memory). The addition of the “auto” option makes the FastTreeSHAP package more accessible.
The number of parallel threads is specified by “n jobs.” The default value is “-1,” which signifies that all available cores are used.
Conclusion
Because of its excellent theoretical features and polynomial computational complexity, TreeSHAP has been widely utilized to explain tree-based models. The FastTreeSHAP package includes FastTreeSHAP v1 and FastTreeSHAP v2, two novel methods for improving TreeSHAP’s computational efficiency, focusing on presenting big data. Furthermore, the FastTreeSHAP package allows parallel computing to boost computational speed while providing a customizable and user-friendly user interface.
Some preliminary results of assessment trials in the FastTreeSHAP article demonstrate that FastTreeSHAP v2 can achieve as much as >3x quicker explanation in multi-time usage settings. Implementing the FastTreeSHAP package in Spark to further scale TreeSHAP computations by leveraging distributed computing capabilities is another potential direction.
Paper: https://arxiv.org/pdf/2109.09847.pdf
Github: https://github.com/linkedin/fasttreeshap
Reference: https://engineering.linkedin.com/blog/2022/fasttreeshap–accelerating-shap-value-computation-for-trees
Suggested
Credit: Source link
Comments are closed.