LLM2LLM: UC Berkeley, ICSI and LBNL Researchers’ Innovative Approach to Boosting Large Language Model Performance in Low-Data Regimes with Synthetic Data
Large language models (LLMs) are at the forefront of technological advancements in natural language processing, marking a significant leap in the ability of machines to understand, interpret, and generate human-like text. However, the full potential of LLMs often remains untapped due to the limitations imposed by the scarcity of specialized, task-specific training data. This bottleneck restricts the applicability of LLMs across various domains, particularly those that are data-constrained.
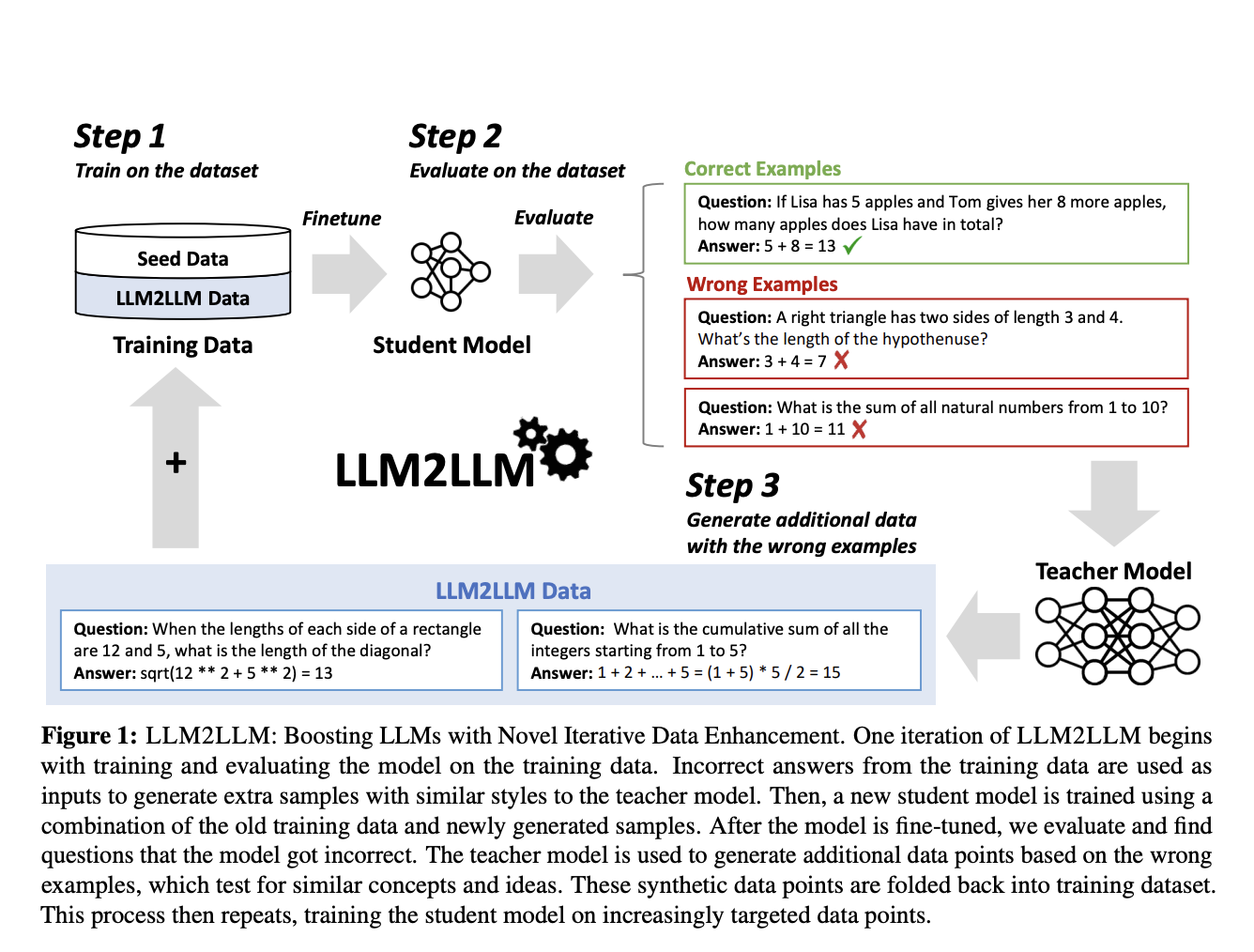
LLM2LLM is proposed by a research team at UC Berkeley, ICSI, and LBNL as a groundbreaking method to amplify the capabilities of LLMs in the low-data regime. This approach diverges from traditional data augmentation techniques, which generally involve straightforward manipulations such as synonym replacement or text rephrasing. While these methods may expand the dataset, they seldom enhance the model’s understanding of complex, specialized tasks. Instead, LLM2LLM utilizes a more sophisticated, iterative process that directly targets the weaknesses of a model, creating a feedback loop that progressively refines its performance.
The LLM2LLM methodology is an interactive dynamic between two LLMs: a teacher model and a student model. Initially, the student model is fine-tuned on a limited dataset. It is then evaluated to identify instances where it fails to predict accurately. These instances are crucial as they highlight the model’s specific areas of weakness. The teacher model steps in at this juncture, generating new, synthetic data points that mimic these challenging instances. This newly created data is then used to retrain the student model, effectively focusing the training process on overcoming its previously identified shortcomings.
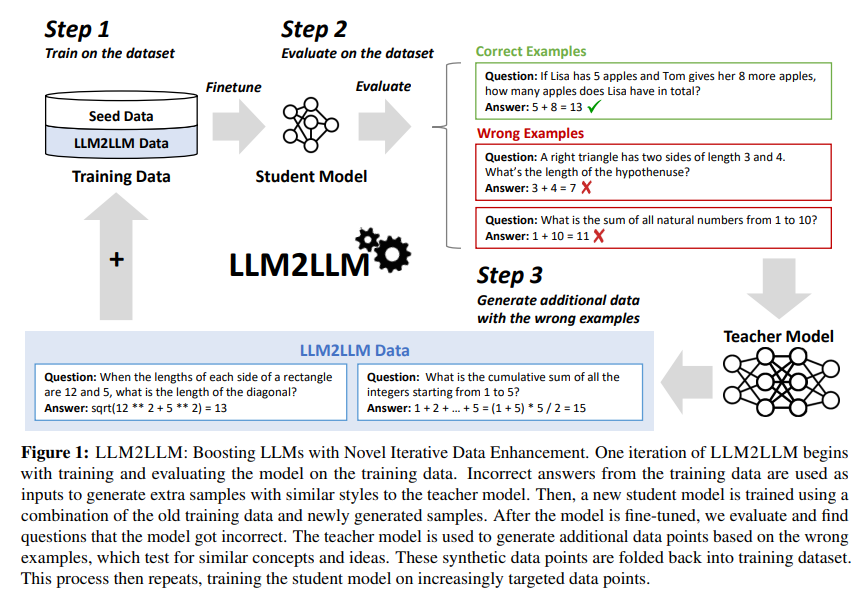
What sets LLM2LLM apart is its targeted, iterative approach to data augmentation. Instead of indiscriminately enlarging the dataset, it smartly generates new data designed to improve the model’s performance on tasks it previously struggled with. In testing with the GSM8K dataset, the LLM2LLM method achieved up to 24.2% improvement in model performance. Similarly, on the CaseHOLD dataset, there was a 32.6% enhancement, and on SNIPS, a 32.0% increase was observed.

In conclusion, the LLM2LLM framework offers a robust solution to the critical challenge of data scarcity. By harnessing the power of one LLM to improve another, it demonstrates a novel, efficient pathway to fine-tune models for specific tasks with limited initial data. The iterative, targeted nature of LLM2LLM significantly outperforms traditional data augmentation and fine-tuning methods, showcasing its potential to revolutionize how LLMs are trained and applied.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.