Make ChatGPT a Better Software Developer: SoTaNa is an Open-Source AI Assistant for Software Development
How we do what we do has changed rapidly in recent years. We have started to use virtual assistants for most of the tasks we have and found ourselves in a position where we feel the need to keep delegating our tasks to an AI agent.
There is a key that unlocks the power to push all these advancements: Software. In an increasingly technology-driven world, software development is key to innovations across various sectors, from healthcare to entertainment. However, the journey of software development is often riddled with complexities and challenges, demanding swift problem-solving and creative thinking from developers.
That’s why AI applications have found themselves a place quite rapidly in the software development space. They ease the process, providing developers with timely answers to their coding queries and supporting them in their endeavors. I mean, you probably use it as well. When was the last time you went to StackOverflow instead of ChatGPT? Or how many times do you press Tab when you have your GitHub copilot installed?
ChatGPT and Copilot are nice, but they still need to be instructed well to work better in software development. Today, we meet with a new player; SoTaNa.
SoTaNa is a software development assistant that harnesses the capabilities of LLMs to enhance the efficiency of software development. LLMs like ChatGPT and GPT4 have demonstrated their prowess in understanding human intent and generating human-like responses. They’ve become valuable across various domains, including text summarization and code generation. However, their accessibility has been limited due to certain constraints, which SoTaNa aims to address.
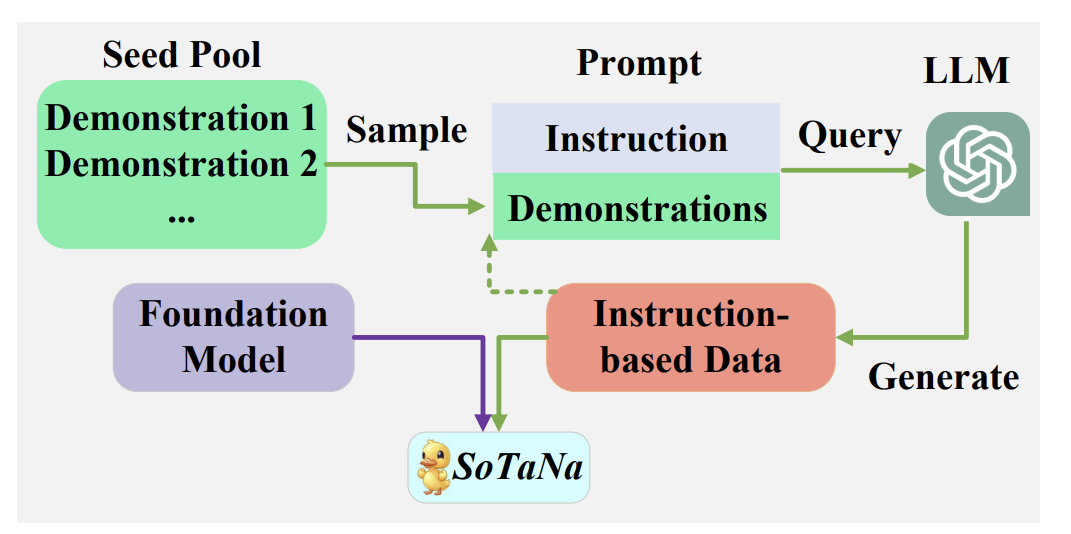
SoTaNa takes center stage as an open-source software development assistant that stands to bridge the gap between developers and the vast potential of LLMs. The primary objective of this initiative is to empower foundation LLMs to understand developer intent while operating with limited computational resources. The research takes a multi-step approach to achieve this, leveraging ChatGPT to generate high-quality instruction-based data for software engineering tasks.
The process begins by guiding ChatGPT through specific prompts that detail the requirements for generating new instances. To ensure accuracy and alignment with the desired output, a manually annotated seed pool of software engineering-related instances serves as a reference. This pool encompasses various software engineering tasks, forming the foundation for generating new data. Through a clever sampling technique, this approach effectively diversifies the demonstration instances and ensures the creation of high-quality data that meets the stipulated requirements.
To better improve the model’s understanding of human intent, SoTaNa employs Lora, a parameter-efficient fine-tuning method, to enhance open-source foundation models, specifically LLaMA, using limited computational resources. This fine-tuning process refines the model’s understanding of human intent within the software engineering domain.
SoTaNa’s capabilities are evaluated using a Stack Overflow question-answering dataset, and the outcomes, including human evaluations, underscore the model’s effectiveness in assisting developers.
SoTaNa introduces the world to an open-source software development assistant built upon the shoulders of LLMs, capable of comprehending developers’ intentions and generating pertinent responses. Additionally, it makes a vital contribution to the community by releasing model weights and a high-quality instruction-based dataset designed exclusively for software engineering. These resources hold the promise of accelerating future research and innovation in the field.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.