Master Key to Audio Source Separation: Introducing AudioSep to Separate Anything You Describe
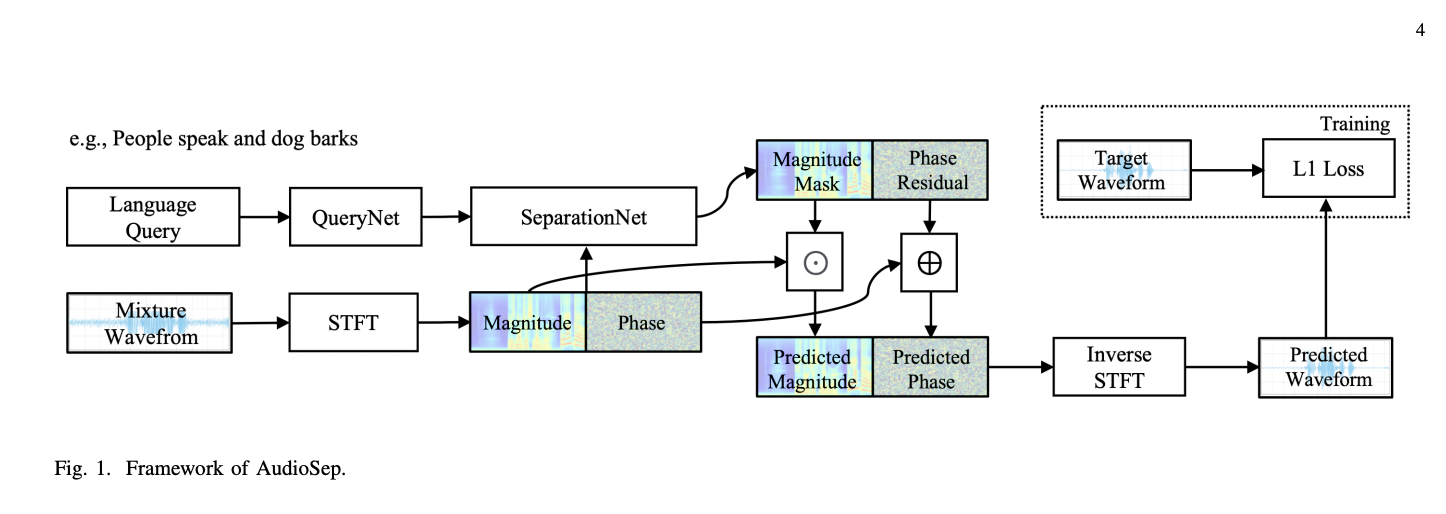
Computational Auditory Scene Analysis (CASA) is a field within audio signal processing that focuses on separating and understanding individual sound sources in complex auditory environments. A new approach to CASA is language-queried audio source separation (LASS), introduced in InterSpeech 2022. The purpose of LASS is to separate a target sound from an audio mixture based on a natural language query, resulting in a natural and scalable interface for digital audio applications. Despite achieving excellent separation performance on sources (such as musical instruments and a small class of audio events), recent efforts on LASS are yet to be able to separate audio concepts in the open domain settings.
To combat those challenges, researchers have developed AudioSep – separate anything audio model, a foundation model showcasing impressive zero-shot generalization across tasks and strong separation capabilities in speech augmentation, audio event separation, and musical instrument separation.
AudioSep has two key components: a text encoder and a separation model. A text encoder of CLIP, or CLAP, is used to extract text embedding. Next, a 30-layer ResUNet consisting of 6 encoders and six decoder blocks on universal sound separation is utilized. Each encoder block consists of two convolutional layers with kernel sizes of 3 × 3. The AudioSep model is trained for 1M steps on 8 Tesla V100 GPU cards.
AudioSep is extensively evaluated over its capabilities on tasks such as audio event separation, musical instrument separation, and speech enhancement. It demonstrated strong separation performance and impressive zero-shot generalization ability using audio captions or text labels as queries, substantially outperforming previous audio-queried and language-queried sound separation models.
Researchers used the AudioSep-CLAP model to visualize spectrograms for audio mixtures and ground-truth target audio sources, as well as separate sources using text queries of varied sound sources (e.g., audio event, voice). The spectrogram pattern of the separated source was found to be similar to that of the ground truth source, which was consistent with the objective experimental results.
They found that using the “original caption” as text queries instead of the “text label” significantly improved performance. This was due to the fact that human-annotated captions provide more detailed and precise descriptions of the source of interest than audio event labels. Despite the personalized nature and variable word distribution of re-annotated captions, the results achieved using the “re-annotated caption” were somewhat poorer than those obtained using the “original caption” while still beating the results obtained with the “text label.” These findings proved the robustness and promising nature of AudioSep with respect to real-world scenarios and have become the tool to separate anything we describe to it.
The next step in the journey of AudioSep is separation via unsupervised learning techniques and extension of the current work to vision-queried separation, audio-queried separation, and speaker separation tasks.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.