Max Plank Researchers Propose A Metrical Face Shape Predictor Called MICA (MetrIC fAce)
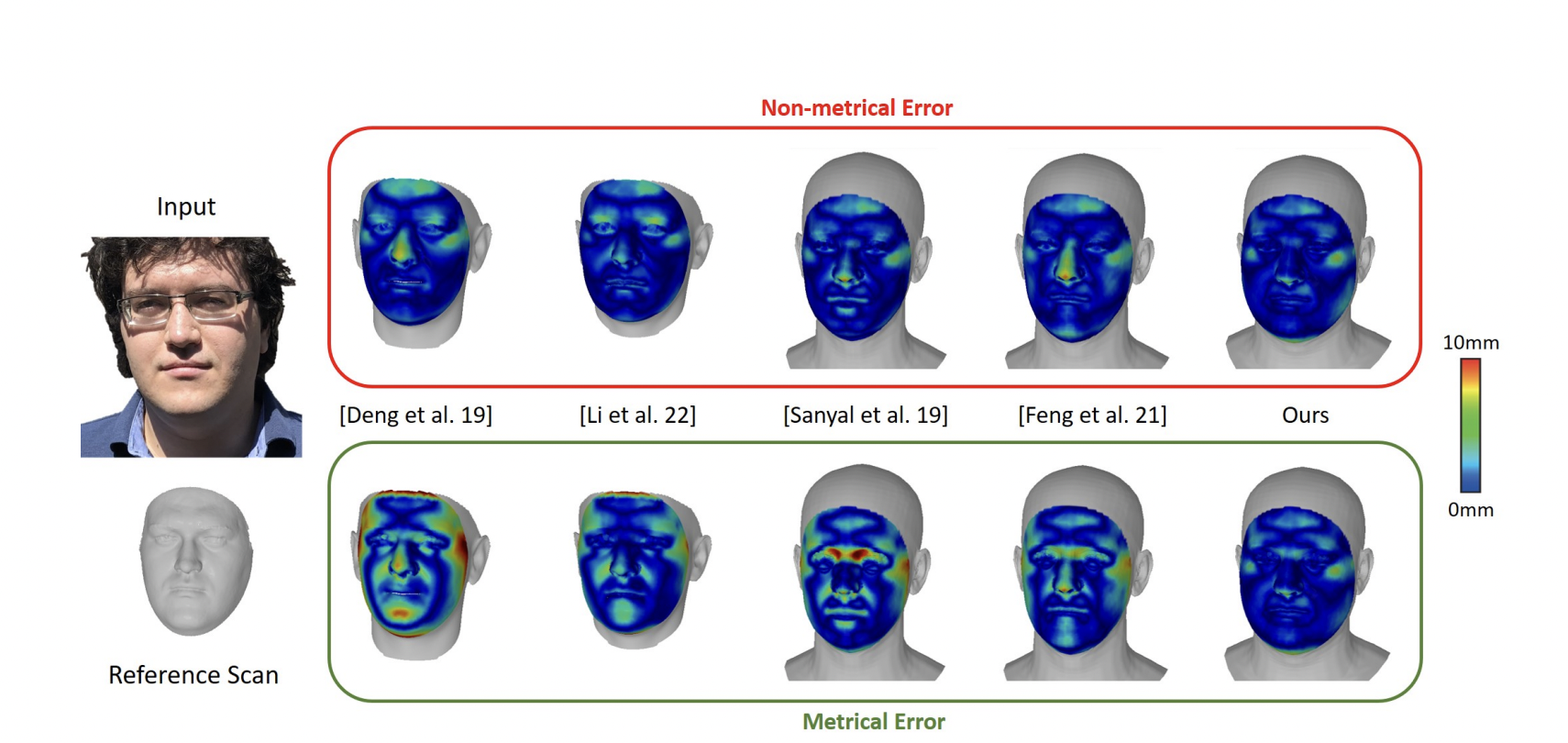
The 3D reconstruction of human faces is an essential building block of several Augmented Reality (AR) and Virtual Reality (VR) applications. Most of the state-of-the-art methods for facial reconstruction from a single RGB image are trained in a self-supervised manner on large 2D image datasets. However, when the face is in a metric context (i.e., when there is a reference object of known size, typical of VR/AR applications), existing solutions cannot reproduce the correct scale and shape of the human face. This happens since, when assuming a perspective camera, the scale of a face is ambiguous. Indeed, a large face can be modeled through a huge face far from the camera or through a small face that is very close to the camera.
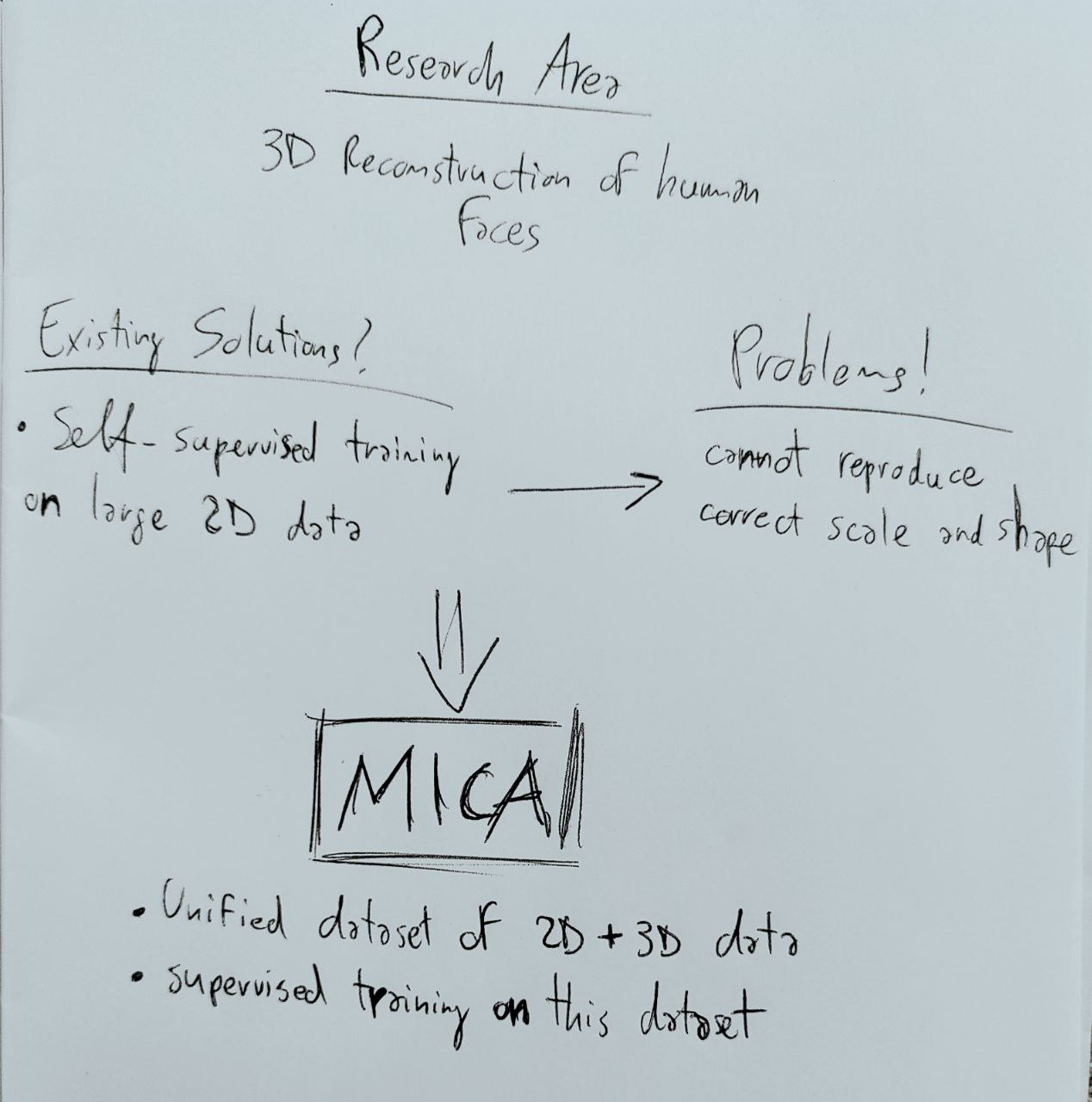
For the above-mentioned reasons, a group of researchers from the Max Planck Institute for Intelligent Systems of Tübingen (Germany) proposed to use supervised machine learning to better learn the actual shape of human faces. At the same time, since there is no large-scale 3D dataset to accomplish this task, the authors also unified a set of small- and medium-scale existing datasets. This unified dataset contains RGB images and the corresponding 3D reconstructed faces.
As shown in Figure 1, given a single RGB image of a person, MICA (MetrIC fAce), the method proposed in this paper, generates a head geometry with a neutral expression. In the next part of the article, we will see how this process is achieved.
The upper part of Figure 2 (i.e., Generalized Metrical Shape Estimation) shows how MICA works. To predict the metrical shape of a human face in a neutral expression, MICA relies on both in-the-wild 2D and metric 3D data to train a deep neural network. The authors used a state-of-the-art face recognition network called ArcFace, which is pre-trained on a large-scale 2D image dataset to obtain highly discriminative features for face recognition. This pre-trained network is robust to facial expression, illumination, and camera changes. The ArcFace architecture has been extended through a mapping network whose purpose is to map the ArcFace features to a latent space that a geometry decoder can subsequently interpret. Indeed, the final step of the process involves a 3D Morphable Model (3DMM) called FLAME that generates the geometry shape based on the ArcFace features.
The described network has been trained on 2D and 3D data in a supervised fashion. During the training process, only the last 3 ResNet blocks of the ArcFace network have been refined and updated to avoid overfitting and improve the generalization capabilities of MICA.
Finally, in the lower part of Figure 2 is depicted an Expression Tracking process implemented by the authors, based on RGB input sequences and the learned metrical reconstruction of the face shape. To implement this face tracker, the authors implemented the Analysis-by-Synthesis principle: given a model that reproduces the appearance of a subject, the model parameters are updated and corrected so that synthesized images fit the input images as well as possible. This model is initialized with the parameters of the 3DMM component of MICA. Then, it is adjusted to learn the deviation of an input image from a neutral pose. In this way, it is possible to obtain a 3D motion tracker.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Towards Metrical Reconstruction of Human Faces'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, project and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Luca is Ph.D. student at the Department of Computer Science of the University of Milan. His interests are Machine Learning, Data Analysis, IoT, Mobile Programming, and Indoor Positioning. His research currently focuses on Pervasive Computing, Context-awareness, Explainable AI, and Human Activity Recognition in smart environments.
Credit: Source link
Comments are closed.