Meet 3D-VisTA: A Pre-Trained Transformer for 3D Vision and Text Alignment that can be Easily Adapted to Various Downstream Tasks
In the dynamic landscape of Artificial Intelligence, advancements are reshaping the boundaries of possibility. The fusion of three-dimensional visual understanding and the intricacies of Natural Language Processing (NLP) has emerged as a captivating frontier. This evolution can lead to understanding and carrying out human commands in the real world. The rise of 3D vision-language (3D-VL) problems has drawn significant attention to the contemporary push to combine the physical environment and language.
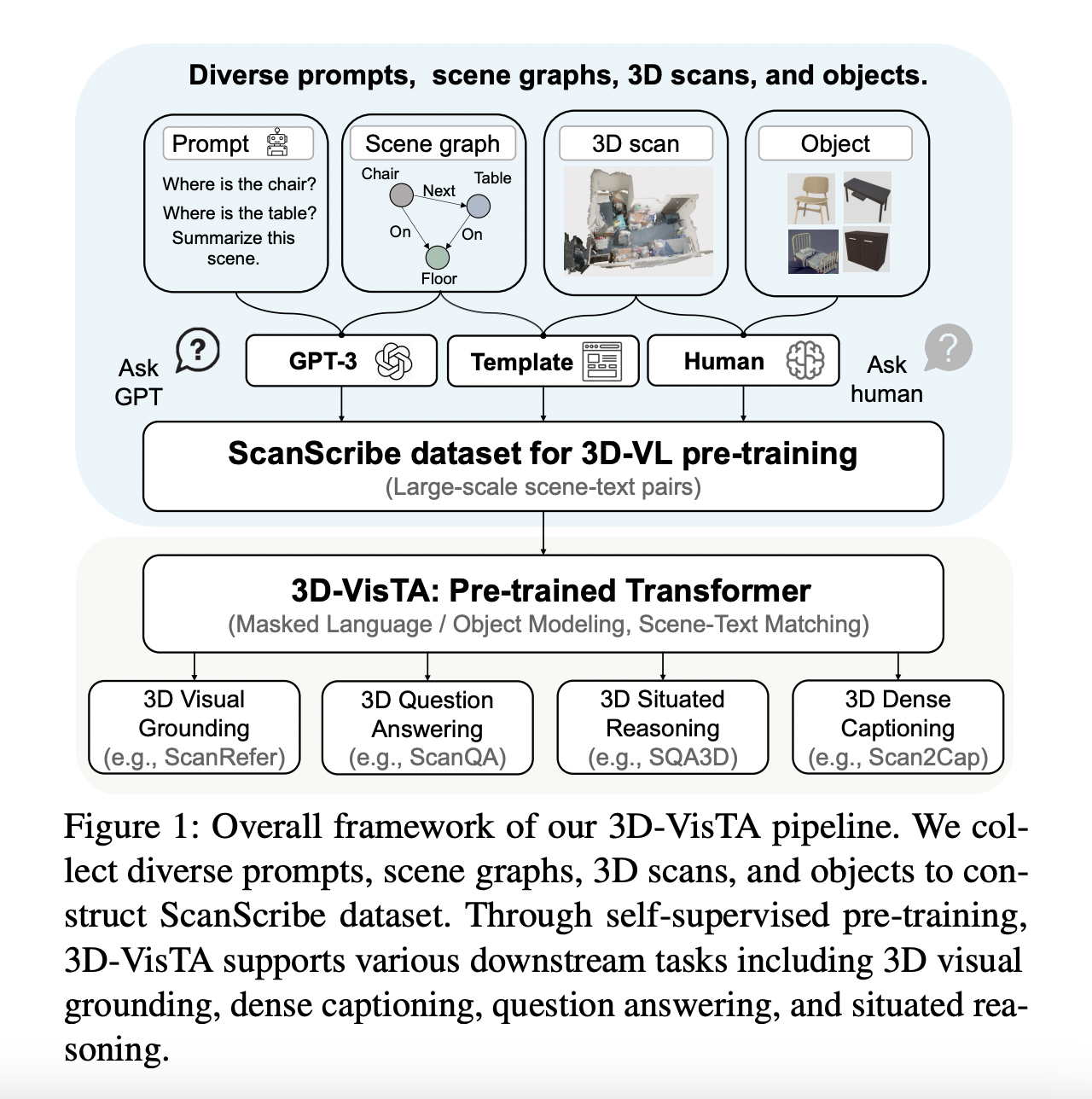
In the latest research by The Tsinghua University and National Key Laboratory of General Artificial Intelligence, BIGAI, China, the team of researchers has introduced 3D-VisTA, which stands for 3D Vision and Text Alignment. 3D-VisTA has been developed in a way that it uses a pre-trained Transformer architecture to combine 3D vision and text understanding in a seamless way. Using self-attention layers, 3D-VisTA embraces simplicity in contrast to current models, which combine complex and specialized modules for various activities. These self-attention layers have two functions: they permit multi-modal fusion to combine the many pieces of information from the visual and textual domains and single-modal modeling to capture information inside individual modalities.
This is achieved without the need for complex task-specific designs. The team has created a sizable dataset called ScanScribe to help the model better handle the difficulties of 3D-VL jobs. By being the first to do so on a broad scale, this dataset represents a significant advancement as it combines 3D scene data with accompanying written descriptions. A diversified collection of 2,995 RGB-D scans, known as ScanScribe, have been taken from 1,185 different indoor scenes in well-known datasets including ScanNet and 3R-Scan. These scans come with a substantial archive of 278,000 associated scene descriptions, and the textual descriptions are derived from different sources, such as the sophisticated GPT-3 language model, templates, and current 3D-VL projects.
This combination makes it easier to receive thorough training by exposing the model to a variety of language and 3D scene situations. Three crucial tasks have been involved in the training process of 3D-VisTA on the ScanScribe dataset: masked language modeling, masked object modeling, and scene-text matching. Together, these tasks strengthen the model’s textual and three-dimensional scene alignment capacity. This pre-training technique eliminates the need for additional auxiliary learning objectives or difficult optimization procedures during the next fine-tuning stages by giving 3D-VisTA a comprehensive understanding of 3D-VL.
The remarkable performance of 3D-VisTA in a variety of 3D-VL tasks serves as further evidence of its efficacy. These tasks cover a wide range of difficulties, such as situated reasoning, which is reasoning within the spatial context of 3D environments; dense captioning, i.e., explicit textual descriptions of 3D scenes; visual grounding, which includes connecting objects with textual descriptions, and question answering which provides accurate answers to inquiries about 3D scenes. 3D-VisTA performs well on these challenges, demonstrating its skill at successfully fusing the fields of 3D vision and language understanding.
3D-VisTA also has outstanding data efficiency, and even when faced with a small amount of annotated data during the fine-tuning step for downstream tasks, it achieves significant performance. This feature highlights the model’s flexibility and potential for use in real-world situations where obtaining a lot of labeled data could be difficult. The project details can be accessed at https://3d-vista.github.io/.
The contributions can be summarized as follows –
- 3D-VisTA has been introduced, which is a combined Transformer model for text and three-dimensional (3D) vision alignment. It uses self-attention rather than intricate designs tailored to certain tasks.
- ScanScribe, a sizable 3D-VL pre-training dataset with 278K scene-text pairs over 2,995 RGB-D scans and 1,185 indoor scenes, has been developed.
- For 3D-VL, a self-supervised pre-training method that incorporates masked language modeling and scene-text matching has been provided. This method efficiently learns the alignment between text and 3D point clouds, making subsequent job fine-tuning easier.
- The method has achieved state-of-the-art performance on a variety of 3D-VL tasks, including visual grounding, dense captioning, question-answering, and contextual reasoning.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.