Meet AiDice: An Algorithm for Large-Scale Anomaly Detection with AIOps in Azure Cloud
Large cloud systems frequently encounter unforeseen problems due to their immense scale. Microsoft Azure makes a conscious effort to anticipate and mitigate errors as quickly as feasible to ensure that its services are dependable. In order to successfully operate a cloud system, Microsoft launched AIOps to monitor Azure’s health metrics continuously. Azure has previously benefited from using AIOps in a secure deployment environment. Further working on this front, Microsoft expanded AIOps to show how AI can be applied to anomaly detection by introducing AiDice. AiDice is a new anomaly detection algorithm created in collaboration with Microsoft Research and Microsoft Azure to detect anomalies in massive, multi-dimensional time series data. AiDice not only promptly captures incidents but also gives engineers crucial context that aids in better problem-solving and delivering the most excellent end-user experience.
Large-scale cloud environments are made up of an infinite number of cloud components, each of which contains an enormous amount of data. This data is frequently multi-dimensional time series data, which, as a result of the numerous combinations of dimensions, comprises an exponential number of individual time series. As a result, it is simply impractical to iterate through and monitor every single time series; here is where AIOps comes into play. As the data volume is too enormous to examine without AI, AIOps is required to detect anomalies.
Anomaly detection was previously restricted to a small subset of the most significant dimensions in large-scale, multi-dimensional time series data. Engineers would then be able to go more into the root cause of the problems to perform a more accurate diagnosis. Although this strategy was successful, Microsoft researchers identified two significant areas for improvement. First, engineers had to manually determine the precise pivot of anomalies using the previous method. By only allowing the engineers to input a small number of dimensions into the anomaly detection algorithms, the strategy also constrained the reach of direct monitoring.
These factors led Microsoft Research and Azure to collaborate to create AiDice, enhancing both areas. AiDice can automatically locate pivots on time series data, even for dozens of dimensions. Engineers can now incorporate even more varied features, such as hardware microcode, OS version, or networking agent version. Although the search space is now much more extensive, AiDice can search over the space more quickly than conventional methods since it has been encoded as a combinatorial optimization problem.

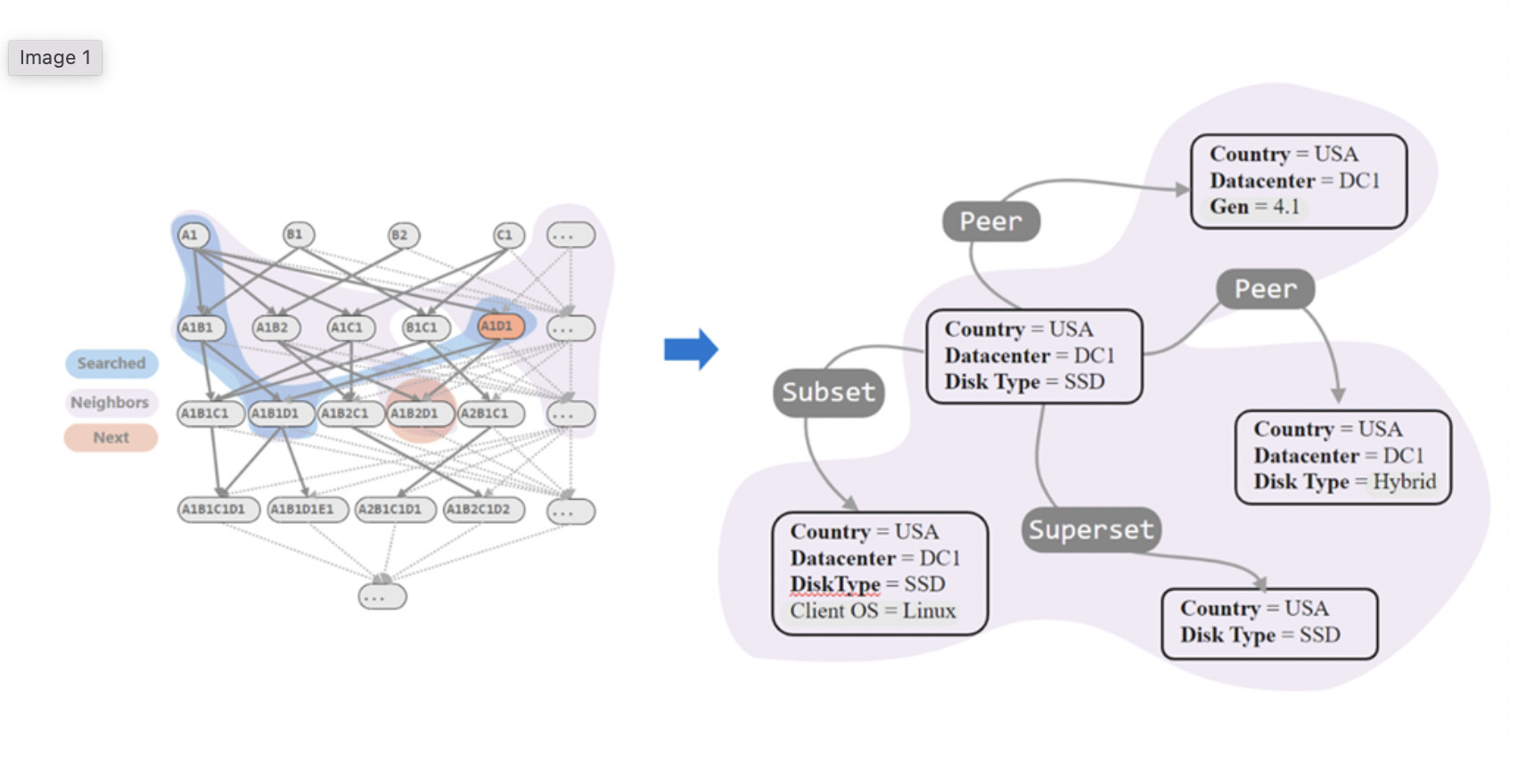
The data is initially transformed into a search problem by the AiDice algorithm. Starting at a specific pivot and expanding the relationships to the neighbors is how search nodes are created. The AiDice method then maximizes an objective function highlighting two crucial components as it intelligently traverses the search space. First, the more abrupt the change in mistakes, the more highly AiDice evaluates the goal function. Second, the objective function receives a higher AiDice score for the larger proportion of errors that occur in this pivot relative to the total number of errors. Since the current results are mathematically optimized but have not yet considered domain knowledge regarding the input data, the alerts that AiDice generates need to be filtered and modified to be less noisy and more actionable. Depending on the nature of the input data, this stage might take many different forms. As an illustration, it is possible to group a series of alerts with the same problem code to lower the overall number of notifications.
While AiDice produces impressive results, researchers are constantly making changes to Azure to make it even more robust and trustworthy. They intend to enable more Azure scenarios in the near future regarding the kinds of metrics the algorithm can work with. To fully utilize the capabilities of AiDice, the team also intends to prepare more data feeds in Azure for AiDice by working on adding supporting properties to specific data sources.
Paper | Reference Article
Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.