Meet Astraios: An AI Model Suite Consisting of 28 Instruction-Tuned OctoCoder Across Scales and PEFT Methods
Recent research highlights the success of Large Language Models (LLMs) trained on Code, excelling at diverse software engineering tasks. These models fall into three primary paradigms: (i) Code LLMs specialized in code completion, (ii) Task-specific Code LLMs fine-tuned for individual tasks, and (iii) Instruction-tuned Code LLMs adept at adhering to human instructions and demonstrating robustness in handling new tasks. Recent instruction-tuned Code LLMs such as WizardCoder and OctoCoder have notably achieved cutting-edge performance across various tasks without requiring task-specific fine-tuning.
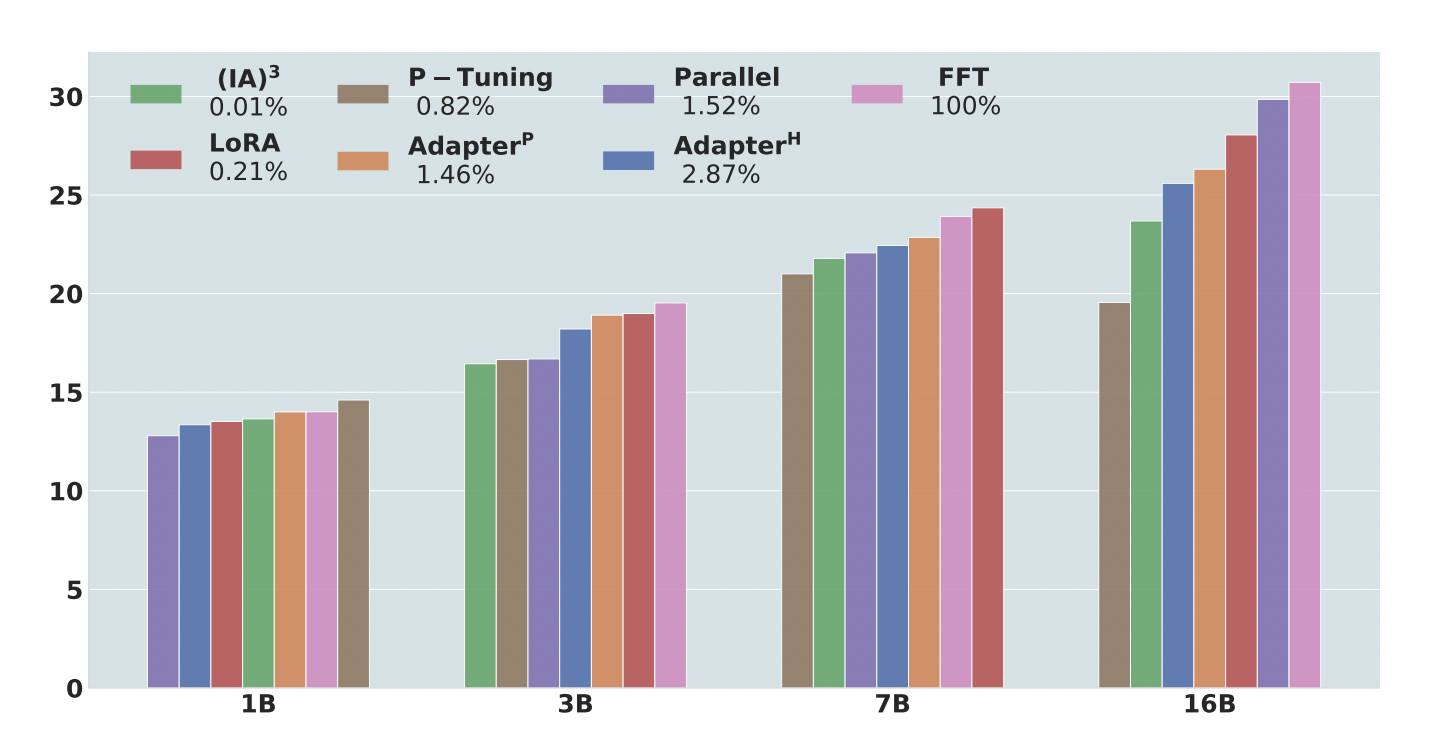
To delve deeper into the identified opportunities, Monash University and ServiceNow Research researchers introduce ASTRAIOS, a collection comprising 28 instruction-tuned Code LLMs. These models undergo fine-tuning using seven tuning methods based on the base models of StarCoder, specifically, models sized at 1B, 3B, 7B, and 16 B. They conduct instruction tuning on these models using the CommitPackFT dataset from OctoPack to ensure a balanced enhancement of their downstream capabilities.
They employ PEFT configurations aligned with Hugging Face’s recommended practices and integrate selected PEFT methods from recent frameworks. They initially scrutinize the scalability of different tuning methods by evaluating cross-entropy loss during instruction tuning. This assessment specifically focuses on assessing model size and training time scales.
Their primary evaluation revolves around five representative code-related tasks: clone detection, defect detection, code synthesis, code repair, and code explanation. Additionally, they conduct further analysis of the tuning methods, examining model robustness and code security. This evaluation involves assessing the models’ ability to generate Code based on perturbed examples and determining the potential vulnerabilities in the generated Code.
Larger PEFT Code LLMs excel in code generation tasks but do not demonstrate similar advantages in code comprehension tasks like clone detection and defect detection. As model size increases, task performance in generation improves but raises concerns regarding susceptibility to adversarial examples and a bias toward insecure Code.
Their study delves into the relationship among updated parameters, cross-entropy loss, and task performance. They ascertain that the final loss of smaller PEFT models can be used to predict that of larger ones. Moreover, a strong correlation exists between the last loss and overall performance in downstream tasks.
The correlation between model loss and updated parameters is inconsistent across different model sizes in our analysis. However, a noteworthy discovery is the uniformity in relative loss performance across various model sizes when comparing other tuning methods. This consistency implies that the enhancements attained by each tuning method are comparable, irrespective of the model’s scale. Consequently, the loss observed in smaller models tuned using different methods can serve as a valuable indicator for predicting the performance of larger models.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.