Meet AttentionViz: An Interactive Visualisation Tool to Examine the Concepts of Attention in Both Language and Vision Transformers
NLP and computer vision are two areas where the transformer neural network design significantly influences. Transformers are currently utilized in sizable, actual systems accessed by hundreds of millions of users (e.g., Stable Diffusion, ChatGPT, Microsoft Copilot). The reasons underlying this accomplishment are still partly a mystery, especially given the rapid development of new tools and the size and complexity of models. By better grasping transformer models, one can create more dependable systems, solve issues, and recommend ways to improve things.
In this paper, researchers from Harvard University discuss a novel visualization method to understand transformer operation better. The process of the characteristic transformer self-attention that enables these models to learn and exploit a wide range of interactions between input elements is the subject of their investigation. Although attention patterns have been thoroughly examined, prior methods typically only displayed data associated with a single input sequence (such as a single sentence or image) at a time. Typical methods show attention weights for a particular input sequence as a bipartite graph or heatmap.
With this approach, they may simultaneously observe the self-attention patterns of several input sequences from a higher degree of perspective. The success of tools like the Activation Atlas, which enables a researcher to “zoom out” to get an overview of a neural network and then dive down for specifics, served as inspiration for this strategy. They want to create an “attention atlas” that will provide academics with a thorough understanding of how a transformer’s many attention heads function. The main innovation is visualizing a combined embedding of the query and key vectors employed by transformers, which yields a distinctive visual mark for each attention head.
To demonstrate their methodology, they employ AttentionViz, an interactive visualization tool that enables users to investigate attention in both language and vision transformers. They concentrate on what the visualization can show about the BERT, GPT-2, and ViT transformers to provide concreteness. With a global view to observe all attention heads at once and the option to zoom in on specifics in a particular attention head or input sequence, AttentionViz enables exploration via several levels of detail (Fig. 1). They use a variety of application situations, including AttentionViz and interviews with subject matter experts, to show the effectiveness of their method.

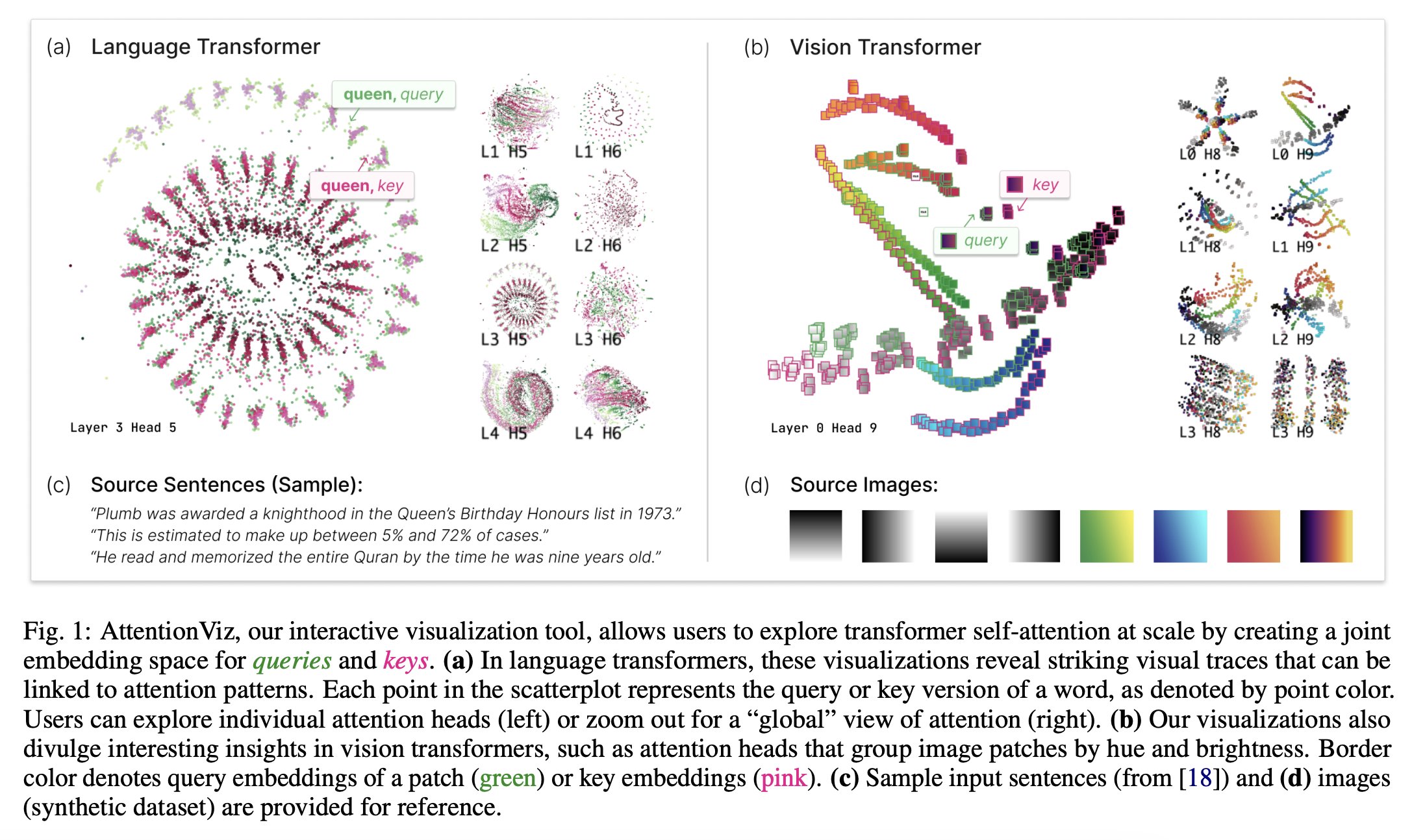
Figure. 1: By generating a shared embedding space for queries and keys, AttentionViz, their interactive visualisation tool, enables users to investigate transformer self-attention at scale. These visualisations in language transformers (a) show impressive visual traces that are connected to attentional patterns. As shown by point colour, each point in the scatterplot indicates the query or key version of a word.
Users can zoom out for a “global” view of attention (right) or investigate individual attention heads (left). (b) Interesting information on vision transformers, such as attention heads that classify picture patches according to hue and brightness, is also shown by their visualisations. Key embeddings are indicated by pink borders, whereas patch embeddings are indicated by green borders. For reference, statements from a synthetic dataset in (c) and photos (d) are presented.
They identify several recognizable “visual traces” connected to attention patterns in BERT, identify unique hue/frequency behavior in the visual attention mechanism of ViT, and locate perhaps anomalous behavior in GPT-2. User comments also support the greater applicability of their technique in visualizing various embeddings at scale. In conclusion, this study makes the following contributions:
• A visualization method based on joint query-key embeddings for examining attention patterns in transformer models.
• Application scenarios and expert input demonstrating how AttentionViz may offer insights regarding transformer attention patterns
• AttentionViz, an interactive tool that applies their approach for researching self-attention in vision and language transformers at numerous scales.
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.