Meet Audiobox: A New Meta AI’s Foundation Research Model for Audio Generation
Audio plays an important role in the field of media and entertainment. It influences everything from movies and podcasts to audiobooks and video games. However, producing top-quality audio demands extensive sound libraries and profound domain expertise.
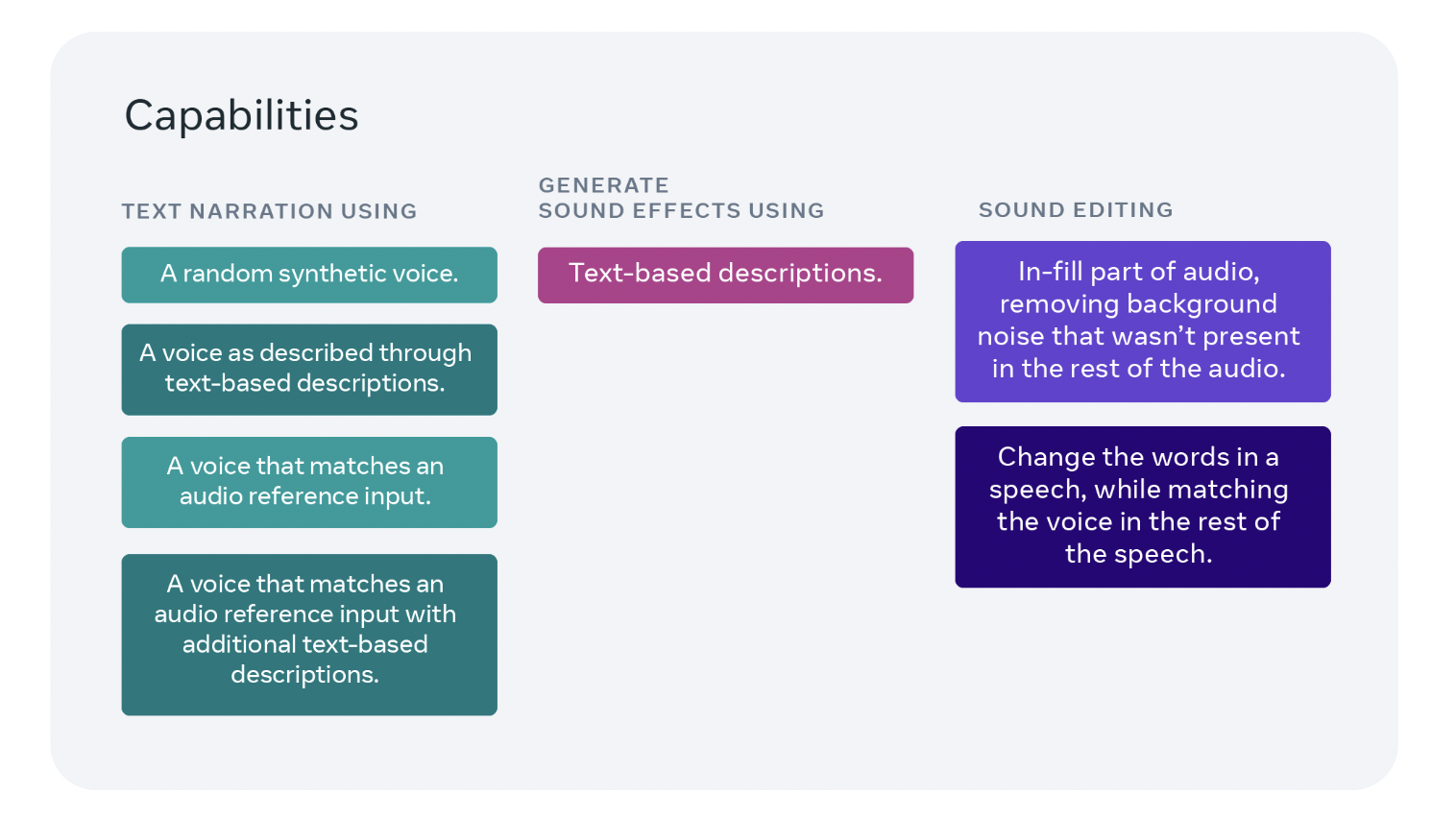
Consequently, Meta-researchers have formulated a new AI model called Audiobox that can generate voices and sound effects using a combination of voice inputs and natural language text prompts — making it easy to create custom audio for a wide range of use cases. It has unified generation and editing capabilities for speech, sound effects, and soundscapes.
Researchers have emphasized that it is a big step in combining generation and editing capabilities for various audio elements. It can generate voices and sound effects using a combination of voice inputs and natural language text prompts — making it easy to create custom audio for a wide range of use cases.
Audiobox has been made as a successor of Voicebox, and it advances the capabilities of its predecessor but also introduces a unified platform that enhances generation and editing across diverse audio elements.
The advantage of Audiobox is its capacity to produce voices and sound effects by combining voice inputs with text prompts in natural language. This method makes the process of creating unique audio for a variety of use cases easier. For example, users can text Audiobox to describe a desired sound or speech type, and Audiobox will automatically create the corresponding audio.
Also, it allows users to use natural language prompts to describe the style of speech they want. This has been an adaptability benefit of Audiobox. Audiobox also lets users customize the sound setting with text prompts. For instance, all it takes to create a serene soundscape with a flowing river and chirping birds is to enter a detailed text prompt, and Audiobox will realize the vision.
With the help of Audiobox, users can alter the voices to sound as though they are from a different setting. This is accomplished by fusing a text-style prompt with an audio voice input, allowing users to create synthesized speech to suit their preferences.
Researchers tested Audiobox on various models such as AudioLDM2, VoiceLDM, and TANGO regarding quality and relevance and found that Audiobox outperforms them. They found that it surpassed Voicebox on style similarity by more than 30 percent across various speech style.
The researchers said that Audiobox will lower the accessibility barrier for audio creation and make it easy for anyone to become an audio content creator.
The researchers want to move from building specialized audio-generative models that can only generate one type of audio to building generalized audio-generative models that can create any audio.
In conclusion, the Audiobox is a significant model in the evolution of audio technology. Its intuitive interface and powerful capabilities redefine how we approach audio creation and open up new possibilities for individuals, seasoned professionals, and enthusiasts, to shape and share their unique auditory visions.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.