Meet AudioLDM 2: A Unique AI Framework For Audio Generation That Blends Speech, Music, And Sound Effects
In a world increasingly reliant on the concepts of Artificial Intelligence and Deep Learning, the realm of audio generation is experiencing a groundbreaking transformation with the introduction of AudioLDM 2. This innovative framework has paved the way for an integrated method of audio synthesis, revolutionizing the way we produce and perceive sound in a variety of contexts, including speech, music, and sound effects. Producing audio information depending on particular variables, such as text, phonemes, or visuals, is known as audio generation. This includes a number of subdomains, including voice, music, sound effects, and even particular sounds like violin or footstep sounds.
Each sub-domain comes with its own challenges, and previous works have often used specialized models tailored to those challenges. Inductive biases, which are predetermined limitations that direct the learning process toward addressing a certain problem, are task-specific biases in these models. These limitations prevent the use of audio generation in complicated situations where many forms of sounds coexist, such as movie sequences, despite great advancements in specialized models. A unified strategy that can provide a variety of audio signals is required.
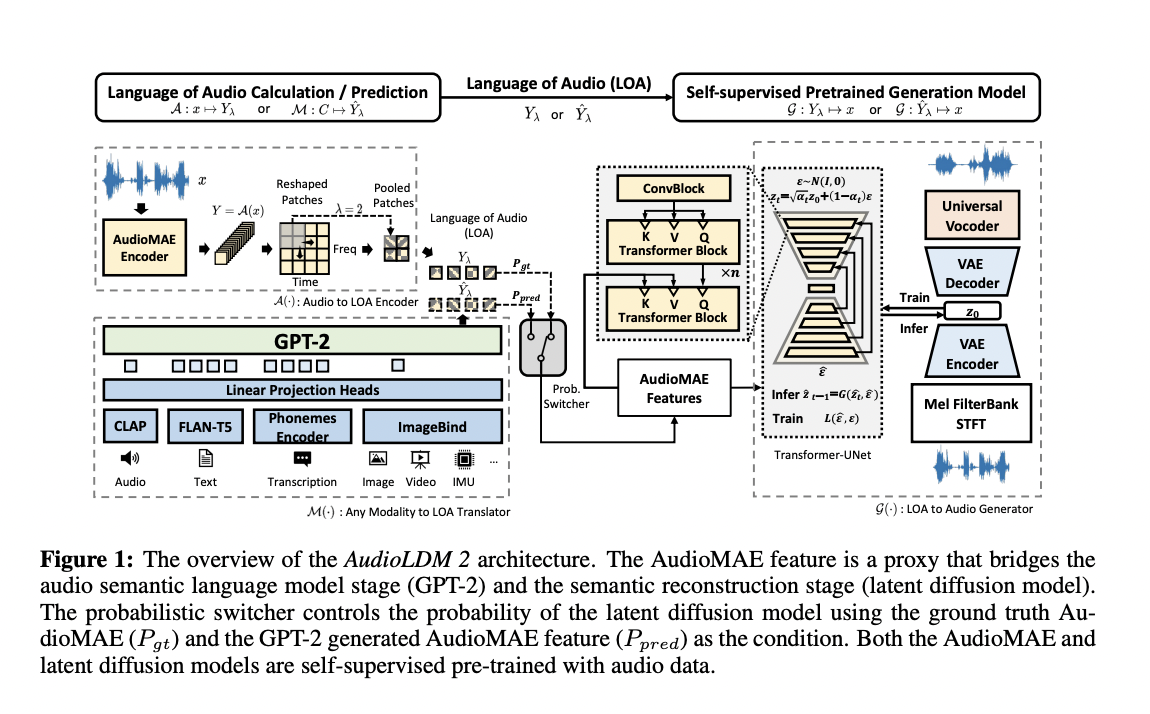
To address these issues, a team of researchers has introduced AudioLDM 2, a unique framework with adjustable conditions that attempt to generate any type of audio without relying on domain-specific biases. The team has introduced the “language of audio” (LOA), which is a sequence of vectors representing the semantic information of an audio clip. This LOA enables the conversion of information that humans understand into a format suited for producing audio dependent on LOA, thereby capturing both fine-grained auditory features and coarse-grained semantic information.
The team has suggested building on an Audio Mask Autoencoder (AudioMAE) that has been pre-trained on a variety of audio sources to do this. The optimum audio representation for generative tasks is produced by the pre-training framework, which includes reconstructive and generative activities. Then conditioning information like text, audio, and graphics is converted into the AudioMAE feature using a GPT-based language model. Depending on the AudioMAE characteristic, audio is synthesized using a latent diffusion model, and this model is amenable to self-supervised optimization, allowing for pre-training on unlabeled audio data. While addressing difficulties with computing costs and error accumulation present in earlier audio models, the language-modeling technique takes advantage of recent developments in language models.
Upon evaluation, experiments have shown that AudioLDM 2 performs at the cutting edge in tasks requiring text-to-audio and text-to-music production. It outperforms powerful baseline models in tasks requiring text-to-speech, and for activities like producing images to sounds, the framework can additionally include criteria for visual modality. In-context learning for audio, music, and voice are also researched as ancillary features. In comparison, AudioLDM 2 outperforms AudioLDM in terms of quality, adaptability, and the production of understandable speech.
The key contributions have been summarized by the team as follows.
- An innovative and adaptable audio generation model has been introduced, which is capable of generating audio, music, and understandable speech with conditions.
- The approach has been built upon a universal audio representation, allowing extensive self-supervised pre-training of the core latent diffusion model without needing annotated audio data. This integration combines the strengths of auto-regressive and latent diffusion models.
- Through experiments, AudioLDM 2 has been validated as it attains state-of-the-art performance in text-to-audio and text-to-music generation. It has achieved competitive outcomes in text-to-speech generation comparable to the current state-of-the-art methods.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.