Meet AudioSR: A Plug & Play and One-for-All AI Solution for Upsampling Audio to Incredible 48kHz Quality
A key challenge in the field of digital audio processing is audio super-resolution. It aims to enhance the quality of audio signals by anticipating and incorporating missing high-frequency components into low-resolution audio data. The primary goal is to deliver a more immersive and superior listening experience, i.e., high fidelity. Audio super-resolution is a crucial technology with numerous uses, such as the restoration of old recordings. However, past approaches in this field have several drawbacks, such as their restriction to a narrow range of bandwidth settings, which is usually limited to 4 kHz to 8 kHz, and their narrow concentration on particular audio genres, such as music or speech.
To overcome the challenges, a team of researchers has recently proposed an innovative method called AudioSR (Audio Super Resolution), which is based on diffusion-based generative models. AudioSR provides strong audio super-resolution capabilities for a range of sounds, including speech, music, and sound effects. The adaptability of AudioSR in handling various audio formats is one of its noteworthy qualities. It can process super-resolution to provide high-quality audio output with a consistent 24 kHz bandwidth and a 48 kHz sampling rate from a variety of sources that produce audio signals with bandwidths ranging from 2 kHz to 16 kHz as input.
Since AudioSR can efficiently upscale audio signals across various audio formats and bandwidth settings, it is highly adaptable to various real-world scenarios and applications. AudioSR builds on earlier research that shows neural vocoders have useful prior knowledge for reconstructing higher frequency components in audio SR tasks. It applies audio SR on the mel-spectrogram and creates the audio signal using a neural vocoder. A latent diffusion model is trained to learn the conditional creation of high-resolution mel-spectrograms from low-resolution counterparts in order for AudioSR to estimate the high-resolution mel-spectrogram.
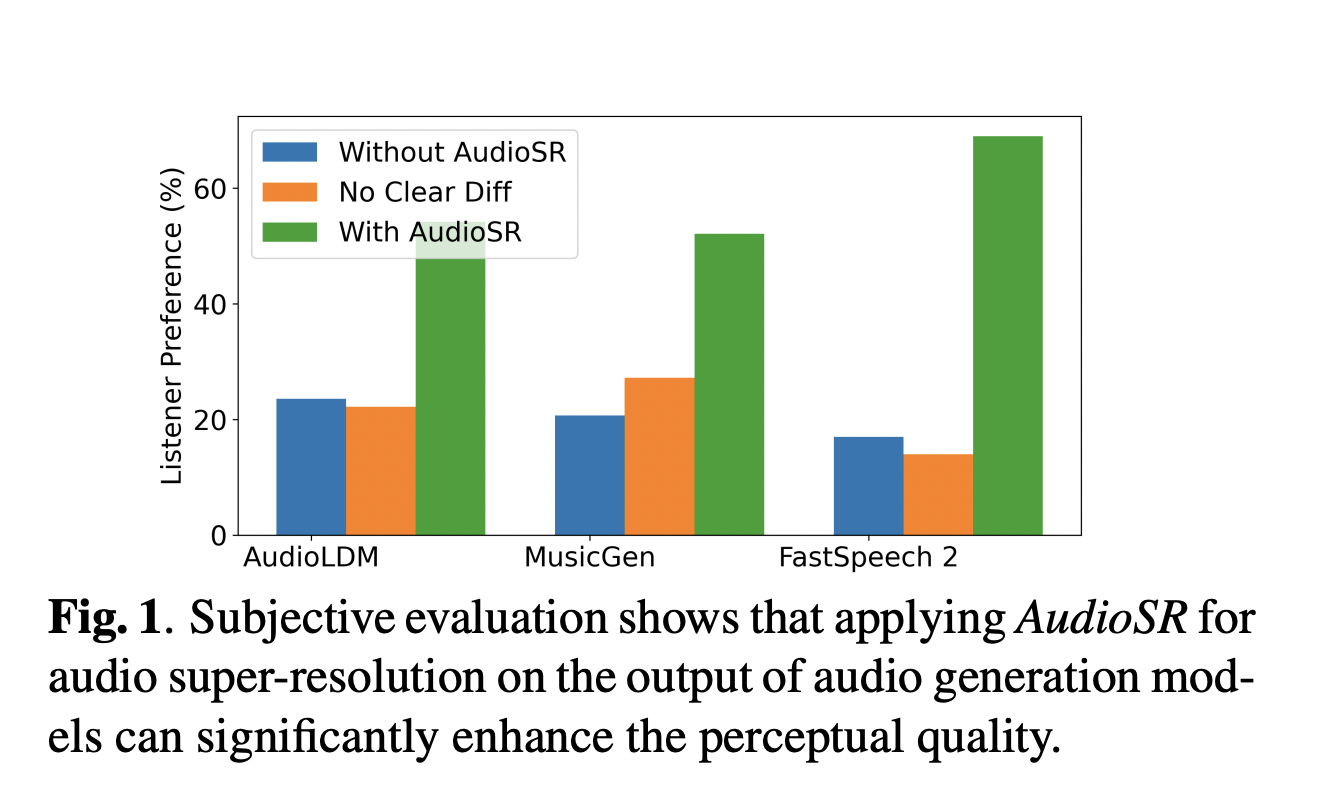
The results of the experiments have shown that AudioSR, while supporting diverse input sample rate settings, provides promising SR outcomes for a variety of audio formats, including speech, music, and sound effects. Subjective analyses have shown that the output of text-to-audio models like AudioLDM, text-to-music models like MusicGen, and text-to-speech models like Fastspeech2 has been greatly improved by the use of AudioSR. This means that AudioSR can be easily included as a plug-and-play module in most audio-generating models, improving listening quality for various applications.
The team has summarized their contributions as follows –
- General Audible Audio Super-Resolution: The team has introduced AudioSR, which achieves audio super-resolution in the domain of all audible sounds. Contrary to earlier approaches, which were frequently specialized to particular audio categories, AudioSR offers a more flexible and all-encompassing solution for enhancing audio quality.
- Flexible Audio Bandwidth Handling: AudioSR provides incredible versatility as it can efficiently process audio signals with a bandwidth spectrum spanning from 2 kHz to 16 kHz. It can even retain a high-quality 48 kHz sampling rate while extending this bandwidth to a reliable 24 kHz.
- Plug-and-Play Integration with Audio Generation Models: AudioSR has shown its value as a plug-and-play module for improving the audio quality of multiple audio generation models and its talents in audio super-resolution. Adding AudioSR to models like AudioLDM, MusicGen, and FastSpeech2 enhances the audio output quality.
Check out the Paper, Project, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.