Meet AUDIT: An Instruction-Guided Audio Editing Model Based on Latent Diffusion Models
Diffusion models are rapidly advancing and making lives easier. From Natural Language Processing and Natural Language Understanding to Computer Vision, diffusion models have shown promising results in almost every domain. These models are a recent development in generative AI and are a type of deep generative model that can be used to generate realistic samples from complex distributions.
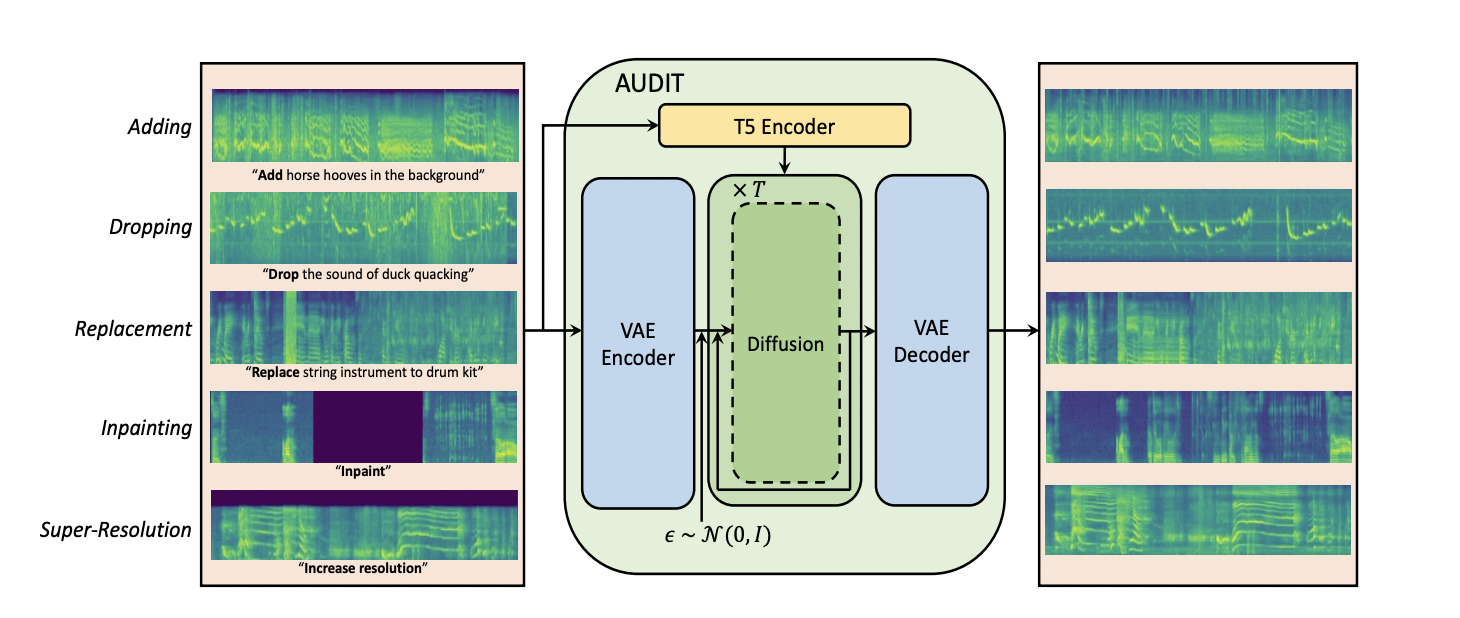
A new diffusion model has been recently introduced by researchers that can easily edit audio clips. Called AUDIT, this latent diffusion model is an instruction-guided audio editing model. Audio editing mainly involves changing an input audio signal to produce an edited audio output. This includes tasks such as adding background sound effects, replacing background music, repairing incomplete audio, or enhancing low-quality audio. AUDIT takes both the input audio and human instructions as conditions and generates the edited audio output.
The researchers have used triplet data to train the audio editing diffusion model in a supervised manner. The triplet data used is instruction, input audio, and output audio. The input audio has been directly used as a conditional input to ensure consistency in the audio segments without editing. The editing instructions have also been directly used as text guidance to make the model more flexible and suitable for real-world scenarios.
The team of researchers behind AUDIT has summarized their contributions as follows –
- AUDIT is the first development in which a diffusion model has been trained for audio editing, which takes human text instructions as the condition.
- A data construction framework has been designed to train AUDIT in a supervised manner.
- AUDIT is capable of maximizing the preservation of audio segments that do not require editing.
- AUDIT works well with simple instructions as text guidance without the need for a detailed description of the editing target.
- AUDIT has achieved noteworthy results in both objective and subjective metrics for a number of audio editing tasks.
The team has shared a few examples where AUDIT has performed greatly and edited audios precisely. Those include adding the sound of car honks in the audio, replacing the sound of laughter with the sound of a trumpet, removing the sound of a woman talking from the audio of someone whistling, and so on. AUDIT performed extremely well in audio editing tasks and showed great results in objective and subjective metrics, including the following tasks.
- Adding a sound to an audio clip.
- Dropping or removing a sound from an audio clip
- Substituting a sound event in the input audio with another sound.
- Audio inpainting: Completing a masked segment of audio based on the context or provided textual prompt.
- Super-resolution task with which low-sampled input audio can be converted into high-sampled output audio.
In conclusion, AUDIT seems like a promising approach for the future that can simplify flexible and effective audio editing by following human instructions.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.