Meet Baichuan 2: A Series of Large-Scale Multilingual Language Models Containing 7B and 13B Parameters, Trained from Scratch, on 2.6T Tokens
Large language models have made significant and encouraging developments in recent years. Language models now have billions or even trillions of parameters, such as GPT3, PaLM, and Switch Transformers, up from millions in earlier models like ELMo and GPT-1. With greater human-like fluency and the capacity to carry out a wide variety of natural language activities, language models’ capabilities have significantly improved as a result of this growth in size. The ability of these models to produce text that sounds like human speech has gained considerable public notice with the release of ChatGPT from OpenAI. ChatGPT has great language skills in various contexts, from casual conversation to clarifying difficult ideas.
This innovation shows how huge language models may be used to automate processes requiring the creation and understanding of natural language. Even though there have been innovative developments and uses for LLMs, most of the top LLMs, like GPT-4, PaLM-2, and Claude, are still closed-source. Because developers and researchers only have partial access to the model parameters, it is challenging for the community to analyze or optimize these systems thoroughly. Research and responsible progress in this quickly developing subject might be sped up with more openness and transparency around LLMs. LLaMA, a collection of large language models created by Meta and having up to 65 billion parameters, has greatly aided the LLM research community by being completely open-source.
Along with other open-source LLMs like OPT, Bloom, MPT, and Falcon, LLaMA’s open design allows academics to freely access the models for analysis, testing, and future development. This accessibility and openness set LLaMA apart from other private LLMs. Alpaca, Vicuna, and other novel models have been made possible by the open-source LLMs’ faster research and development in the field. However, English has been the main focus of most open-source big language models. For instance, Common Crawl1 is the primary data source for LLaMA, and it contains 67% of the pre-training data but is only allowed to contain English material. Other free-source LLMs with limited capabilities in different languages, including MPT and Falcon, mostly focus on English.
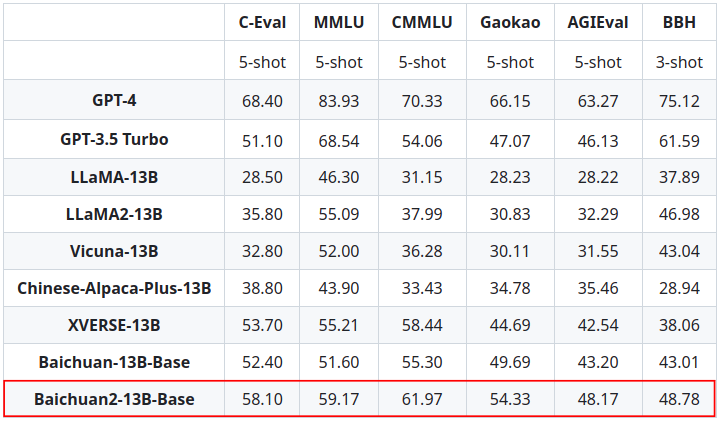
This makes it difficult for LLMs to be developed and used in certain languages, such as Chinese. Researchers from Baichuan Inc. introduce Baichuan 2, a group of extensive multilingual language models, in this technical study. Baichuan 2 features two distinct models: Baichuan 2-13B and Baichuan 2-7B, each with 13 billion parameters. Both models were tested using 2.6 trillion tokens, which is more than twice as many as Baichuan 1 and is the greatest sample size known to them. Baichuan 2 significantly outperforms Baichuan 1 with a large amount of training data. Baichuan 2-7B performs about 30% better than Baichuan 1-7B on common benchmarks, including MMLU, CMMLU, and C-Eval. Baichuan 2 is specifically optimized to enhance performance on math and coding issues.
Baichuan 2 roughly doubles the outcomes of Baichuan 1 on the GSM8K and HumanEval tests. Additionally, Baichuan 2 does well on jobs in the medical and legal domains. Baichuan 2 beats other open-source models on benchmarks like MedQA and JEC-QA, giving it a good foundation model for domain-specific optimization. They also created two chat models to obey human instructions: Baichuan 2-7B-Chat and Baichuan 2- 13B-Chat. These models are excellent at comprehending discourse and context. They will go into further detail about their strategies for enhancing Baichuan 2 safety. By making these models open-source, the community could further increase the security of large language models while encouraging greater study on the responsible creation of LLMs.
Additionally, they are releasing the checkpoints of Baichuan 2 at various training levels, from 200 billion tokens up to the entire 2.6 trillion tokens, in the spirit of research collaboration and continual progress. They discovered that performance kept improving even with the 7 billion parameter model after training on more than 2.6 trillion tokens. They intend to give the community more understanding of the training dynamics of Baichuan 2 by disseminating these interim findings. Uncovering the underlying workings of huge language models requires understanding these dynamics. The publication of these checkpoints will open up new opportunities for development in this quickly evolving area. The chat and foundation models for Baichuan 2 are accessible on GitHub for study and business purposes.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.