Meet BiTA: An Innovative AI Method Expediting LLMs via Streamlined Semi-Autoregressive Generation and Draft Verification
Large language models (LLMs) based on transformer architectures have emerged in recent years. Models such as Chat-GPT and LLaMA-2 demonstrate how the parameters of LLMs have rapidly increased, ranging from several billion to tens of trillions. Although LLMs are very good generators, they have trouble with inference delay since there is a lot of computing load from all the parameters. Consequently, there has been a lot of push to speed up LLM inference, especially for contexts with constrained resources like edge devices and real-time apps like chatbots.
Recent papers show that most decoder-only LLMs follow a token-by-token generation pattern. Due to the autoregressive (AR) nature of token generation, each token must undergo its inference execution, resulting in many transformer calls. Reduced computational efficiency and longer wall-clock periods are common outcomes of these calls running against memory bandwidth restrictions.
By simultaneously synthesizing several tokens with a single step of model inference, semi-autoregressive (SAR) decoding reduces the high need for inference executions. The problem is that most LLMs can only generate AR models, not SARs. Because the SAR goals and AR pretraining aren’t in sync, re-training the SAR model seems daunting.
Researchers at Intellifusion Inc. and Harbin Institute of Technology hope to achieve lossless SAR decoding for AR language models with their new acceleration approach, Bi-directional Tuning for lossless Acceleration (BiTA) by learning a small number of additional trainable parameters—as little as 0.01%.
The two main parts of BiTA are the suggested bi-directional tuning and the simplified verification of the SAR draft candidates. To enable the prediction of future tokens, bi-directional tuning for an AR model incorporates both prompt and mask tokens, going beyond the next token. Learnable prefix and suffix embeddings in token sequence are a metaphor for this approach. In the transformed AR model, generation and verification happen in tandem in a single forward pass, made possible by an intricate tree-based attention mechanism. Due to its universal architecture, additional validation procedures or third-party verification models are not required. The suggested approach, which uses quick tuning, can be used as a plug-and-play module to speed up any publically accessible transformer-based LLMs, especially those well-instructed chatbots, without weakening their outstanding generating powers.
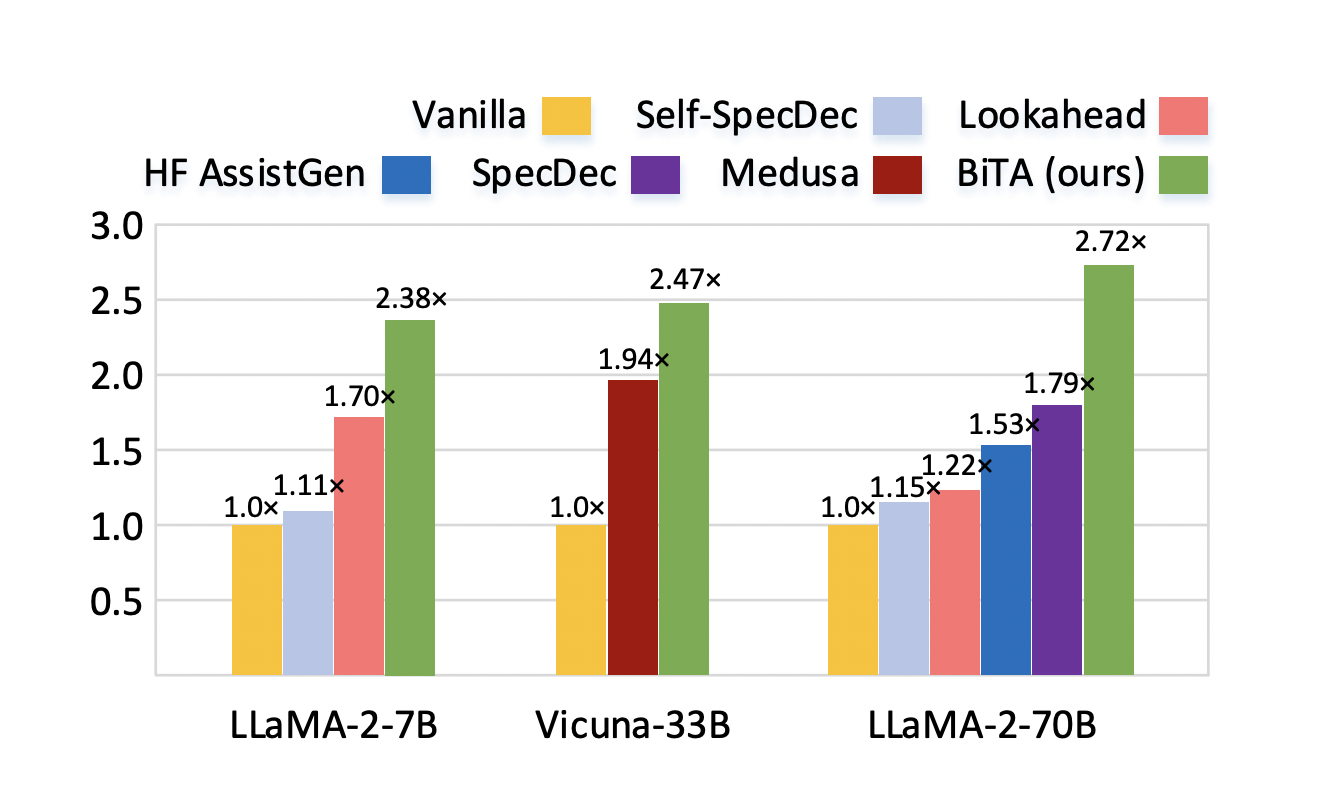
The model performs efficient creation and verification in parallel using a tree-based decoding technique. Both of these aspects of BiTA work together to speed up LLMs while keeping the original outputs intact. In numerous generating jobs with LLMs of different sizes, extensive testing findings show an impressive speedup ranging from 2.1× to 3.3×. Moreover, when resources are restricted, or real-time applications are required, BiTA’s adaptable prompting design makes it a plug-and-play method that can be used to accelerate any publicly available LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.