Meet BITE: A New Method That Reconstructs 3D Dog Shape And Poses From One Image Even With Challenging Poses Like Sitting And Lying
Numerous fields, including biology and conservation, as well as entertainment and the development of virtual content, can benefit from capturing and modeling 3D animal shapes and attitudes. Because they don’t need the animal to stay motionless, maintain a particular posture, make physical contact with the observer, or do anything else cooperative, cameras are a natural sensor for observing animals. There is a long history of utilizing photos to study animals, such as Muybridge’s well-known “Horse in Motion” chronophotographs. However, unlike earlier work on 3D human shape and stance, expressive 3D models that can change to an animal’s unique shape and position have recently been developed. Here, they focus on the challenge of 3D dog reconstruction from a single photograph.
They concentrate on dogs as a model species because of their strong quadruped-like articulated deformations and wide shape variation among breeds. Dogs are regularly captured on camera. Thus, various stances, shapes, and settings are easily accessible. Modeling people and dogs may have comparable difficulties at first look, yet they pose extremely distinct technological hurdles. A vast quantity of 3D scan and motion capture data is already available to people. Learning robust, articulated models like SMPL or GHUM has been made possible by the data’s coverage of proper posture and form variables.
Contrarily, it is challenging to gather 3D observations of animals, and there currently needs to be more of them available to train similarly expressive 3D statistical models that account for all conceivable forms and positions. It is now feasible to recreate animals in 3D from photographs, including dogs, thanks to the development of SMAL, a parametric quadruped model learned from toy figurines. Conversely, SMAL is a general model for many species, from cats to hippos. While it can depict the many body types of various animals, it cannot depict the distinctive and minute details of dog breeds, such as the huge range of ears. To solve this issue, researchers from ETH Zurich, Max Planck Institute for Intelligent Systems, Germany and IMATI-CNR, Italy provide the first D-SMAL parametric model, which correctly represents dogs.
Another problem is that, in contrast to people, dogs have relatively little motion capture data, and of that data that does exist, sitting and reclining stances are rarely captured. Due to this, it is challenging for current algorithms to infer dogs in certain stances. For instance, learning a prior over 3D poses from historical data will bias it towards standing and walking positions. By utilizing generic constraints, one may weaken this prior, but the posture estimation would become severely underconstrained. To solve this issue, they use information regarding physical touch that has yet to be overlooked when modeling (land) animals, such as the fact that they are subject to gravity and consequently stand, sit, or lie on the ground.
In tough situations with extensive self-occlusion, they demonstrate how they may use ground contact information to estimate complicated dog positions. Although ground plane restrictions have been used in human posture estimation, the potential advantage is greater for quadrupeds. Four legs suggest more ground contact points, more body portions obscured when sitting or laying down, and bigger non-rigid deformations. Another drawback of earlier research is that the reconstruction pipelines are often trained on 2D pictures since gathering 3D data (with matched 2D images) is challenging. As a result, they frequently forecast positions and forms that, when re-projected, closely match the visual evidence but are warped along the viewing direction.
The 3D reconstruction could be erroneous when seen from a different angle because, in the absence of paired data, there is insufficient information to determine where to place farther away or even obscured body components along the depth direction. Once more, they discover that simulating ground contact is beneficial. Instead of manually reconstructing (or synthesizing) coupled 2D and 3D data, they switch to a more lax 3D supervision method and acquire ground contact labels. They ask annotators to indicate whether the ground surface under the dog is flat and, if so, to additionally annotate the ground contact points on the 3D animal. They achieve this by presenting genuine photos to the annotators.

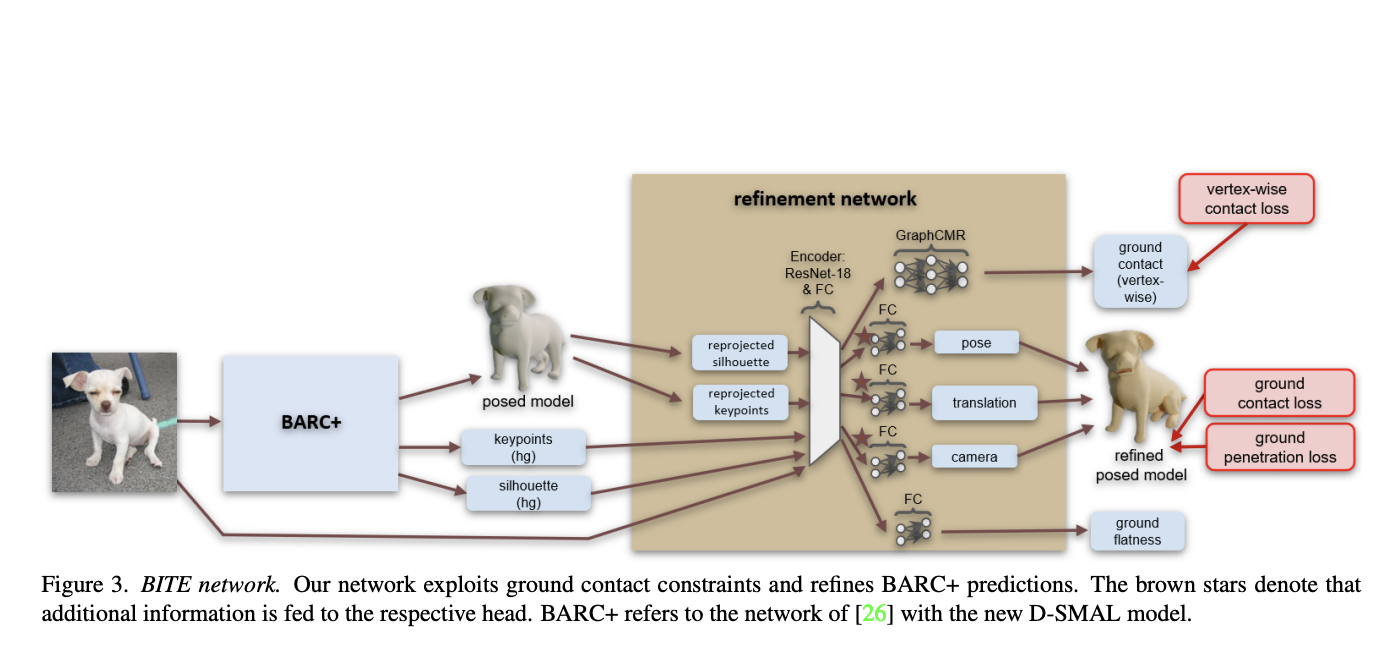
They discovered that the network could be taught to classify the surface and detect the contact points quite accurately from a single image, such that they can also be employed at test time. These labels are utilized not just for training. Based on the most recent cutting-edge model, BARC, their reconstruction system is known as BITE. They retrain BARC using their novel D-SMAL dog model as an initial, coarse-fitting step. Following that, they send the resulting predictions to their recently created refinement network, which they train using ground contact losses to improve both the camera’s settings and the dog’s stance. They may also use the ground contact loss at test time to fully autonomously optimize the fit to the test picture.
This greatly raises the quality of the reconstruction. Even if the training set for the BARC pose prior does not contain such poses, they can get dogs using BITE that correctly stand on the (locally planar) ground or are rebuilt realistically in sitting and reclining positions (see Fig. 1). Prior work on 3D dog reconstruction is assessed either by subjective visual assessments or by back-projecting to the picture and evaluating 2D residuals, thus projecting away depth-related inaccuracies. They have developed a unique, semi-synthetic dataset with 3D ground truth by producing 3D scans of actual canines from various viewing angles to overcome the absence of objective 3D assessments. They assess BITE and its primary rivals using this new dataset, demonstrating that BITE establishes a new standard for the field.
The following summary of their contributions:
1. They provide D-SMAL, a brand-new, canine-specific 3D posture and form model developed from SMAL.
2. They create BITE, a neural model to enhance 3D dog postures while simultaneously assessing the local ground plane. BITE encourages convincing ground contact.
3. They demonstrate how it is feasible to recover dog positions that are very different from those encoded in a (necessarily small) prior to using that model.
4. Using the complex StanfordExtra dataset, they improve state of the art for monocular 3D posture estimation.
5. To promote the transition to true 3D evaluation, they present a new, semi-synthetic 3D test collection based on scans of actual canines.
Check Out The Paper and Project Page. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.