Meet CancerGPT: A Proposed Model that Uses a Large Language Model to Predict Synergies of Drug Pairs on Particular Tissues in a Few-Shot Setting
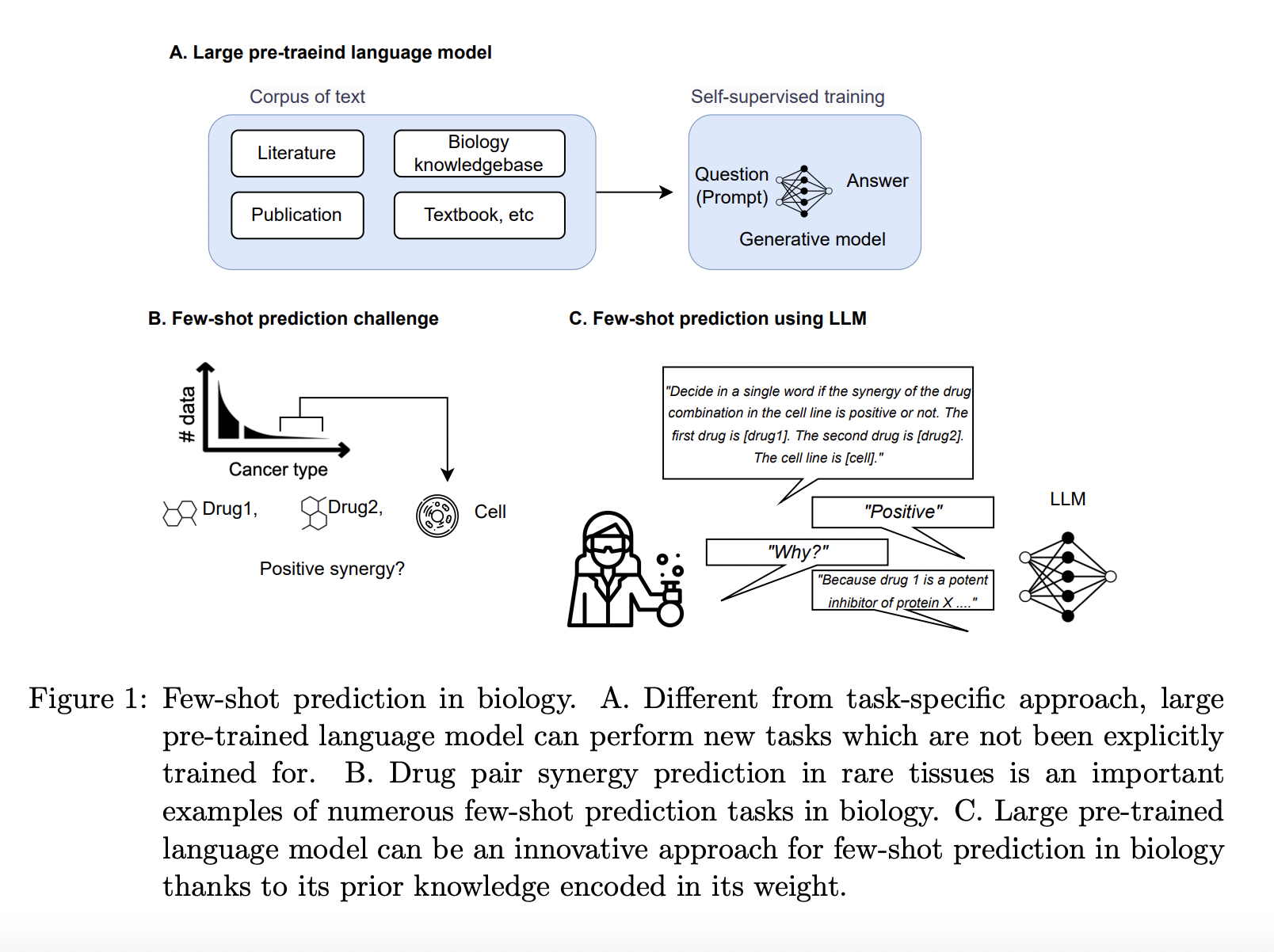
The most recent iteration of artificial intelligence uses foundation models. Such foundation models or “generalist” models may be used for numerous downstream tasks without particular training instead of building AI models that tackle specific tasks one at a time. For instance, the massive pre-trained language models GPT-3 and GPT-4 have revolutionized the basic AI model. LLM may use few-shot or zero-shot learning to apply its knowledge to new tasks for which it has yet to be taught. Multitask learning, which enables LLM to learn from implicit tasks in its training corpus accidentally, is partly to blame for this.
Although LLM has demonstrated proficiency in few-shot learning in several disciplines, including computer vision, robotics, and natural language processing, its generalizability to problems that cannot be observed in more complex fields like biology has yet to be thoroughly examined. Understanding the involved parties and underlying biological systems is necessary to infer unobserved biological reactions. Most of this information is in free-text literature, which might be used to train LLMs, whereas structured databases only encapsulate a small amount. Researchers from the University of Texas, the University of Massachusetts Amherst, and the University of Texas Health Science Center believe that LLMs, which extract previous knowledge from unstructured literature, might be a creative method for biological prediction challenges where there is a lack of structured data and small sample sizes.
A crucial problem in such a few-shot biological prediction is the prediction of medication pair synergy in cancer types that have not been well explored. Drug combinations in therapy are now a common practice for managing difficult-to-treat conditions, including cancer, infectious infections, and neurological disorders. Combination therapy frequently offers superior therapeutic results over single-drug treatment. Medication discovery and development research has increasingly focused on predicting the synergy of medication pairs. Drug pair synergy describes how using two medications together has a greater therapeutic impact than using each separately. Due to the numerous potential combinations and complexity of the underlying biological systems, forecasting medication pair synergy cannot be easy.
Several computational techniques have been created to anticipate medication pair synergy, notably employing machine learning. Large datasets of in vitro experiment results for drug combinations may be used to train machine learning algorithms to find trends and forecast the likelihood of synergy for a novel medication pair. A relatively small amount of experiment data is accessible for some tissues, such as bone and soft tissues. In contrast, most data pertains to common cancer forms in select tissues, like breast and lung cancer. The volume of training data available for medication pair synergy prediction is constrained by the physically demanding and expensive nature of obtaining cell lines from these tissues. Large dataset-dependent machine learning models may need help to train.
Early research ignored these tissues’ biological and cellular variations and extrapolated the synergy score to cell lines in other tissues based on relational or contextual information. By utilizing various and high-dimensional data, such as genomic or chemical profiles, another line of research has attempted to reduce the disparity across tissues. Despite the promising findings in some tissues, these techniques must be used on tissues with sufficient data to modify their model with the many parameters for those high-dimensional properties. They want to address the aforementioned problem faced by LLMs in this work. They assert that the scientific literature still contains useful information on cancer kinds with sparse organized data and inconsistent characteristics.
It isn’t easy to manually gather prognostic data about such biological things from literature. Utilizing past information from scientific literature stored in LLMs is their novel strategy. They created a model that converts the prediction job into a natural language inference challenge and generates responses based on knowledge embodied in LLMs, called the few-shot drug pair synergy prediction model. Their experimental findings show that their LLM-based few-shot prediction model beat strong tabular prediction models in most scenarios and attained considerable accuracy even in zero-shot settings. Because it demonstrates a high potential in the “generalist” biomedical artificial intelligence, this extraordinary few-shot prediction performance in one of the most difficult biological prediction tasks has a vital and timely relevance to a large community of biomedicine.
Check out the Paper. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.