Meet CapPa: DeepMind’s Innovative Image Captioning Strategy Revolutionizing Vision Pre-training and Rivaling CLIP in Scalability and Learning Performance
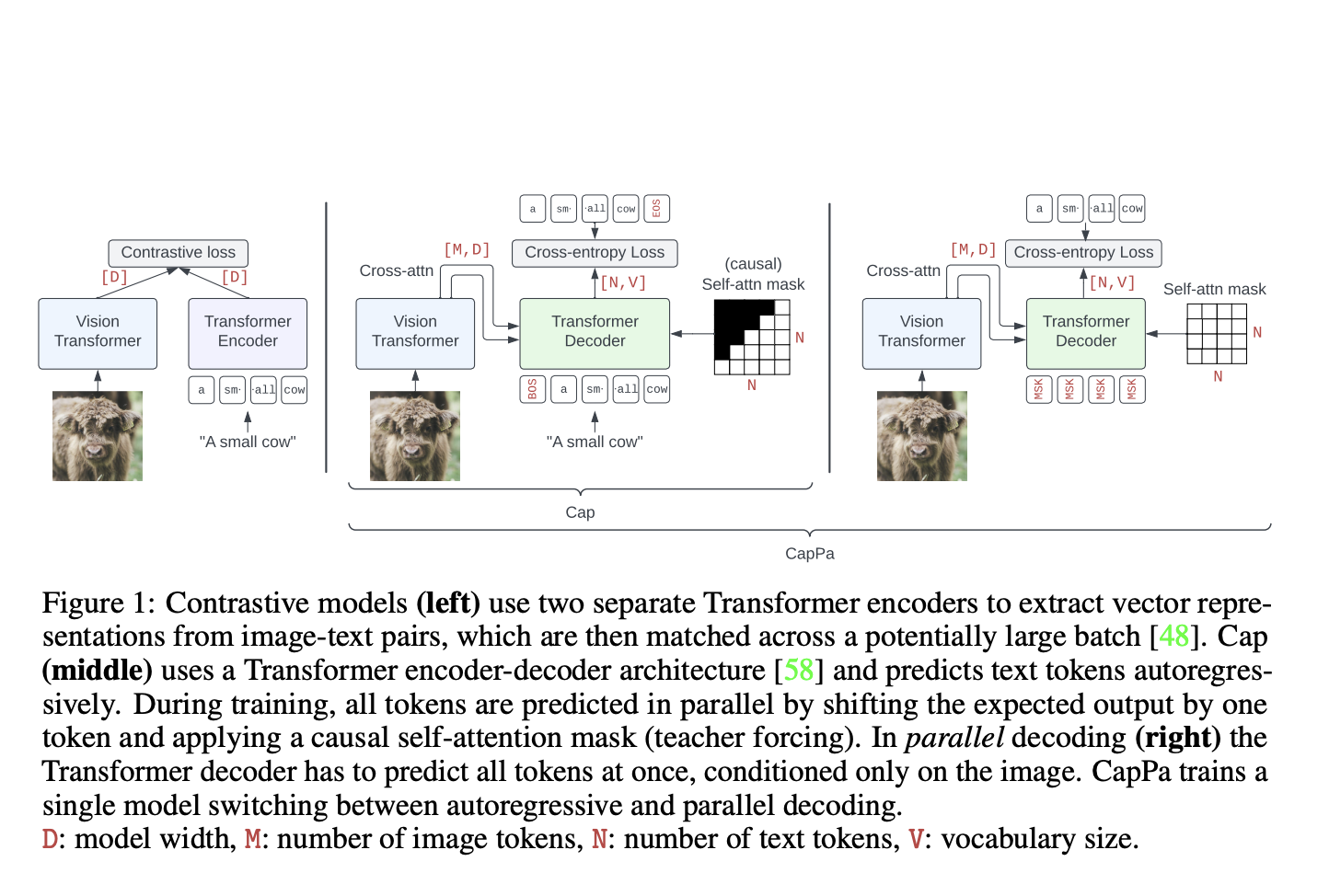
A recent paper titled “Image Captioners Are Scalable Vision Learners Too” presents an intriguing approach called CapPa, which aims to establish image captioning as a competitive pre-training strategy for vision backbones. The paper, authored by a DeepMind research team, highlights the potential of CapPa to rival the impressive performance of Contrastive Language Image Pretraining (CLIP) while offering simplicity, scalability, and efficiency.
The researchers extensively compared Cap, their image captioning strategy, and the widely popular CLIP approach. They carefully matched the pretraining compute, model capacity, and training data between the two strategies to ensure a fair evaluation. The researchers found that Cap vision backbones outperformed CLIP models across several tasks, including few-shot classification, captioning, optical character recognition (OCR), and visual question answering (VQA). Moreover, when transferring to classification tasks with large labeled training data, Cap vision backbones achieved comparable performance to CLIP, indicating their potential superiority in multimodal downstream tasks.
To further enhance the performance of Cap, the researchers introduced the CapPa pretraining procedure, which combines autoregressive prediction (Cap) with parallel prediction (Pa). They employed Vision Transformer (ViT) as the vision encoder, leveraging its strong capabilities in image understanding. For predicting image captions, the researchers utilized a standard Transformer decoder architecture, incorporating cross-attention to use the ViT-encoded sequence in the decoding process effectively.
Instead of solely training the model in an autoregressive way in the training stage, the researchers adopted a parallel prediction approach where the model predicts all caption tokens independently and simultaneously. By doing so, the decoder can heavily rely on image information to improve prediction accuracy, as it has access to the full set of tokens in parallel. This strategy allows the decoder to benefit from the rich visual context provided by the image.
The researchers conducted a study to evaluate the performance of CapPa compared to conventional Cap and the state-of-the-art CLIP approach across a wide range of downstream tasks, including image classification, captioning, OCR, and VQA. The results were highly promising, as CapPa consistently outperformed Cap on almost all tasks. Furthermore, compared to CLIP* trained with the same batch size, CapPa achieved comparable or superior performance. Additionally, CapPa showcased strong zero-shot capabilities, enabling effective generalization to unseen tasks, and exhibited promising scaling properties, indicating its potential to handle larger-scale datasets and models.
Overall, the work presented in the paper establishes image captioning as a competitive pre-training strategy for vision backbones. By showcasing the effectiveness of CapPa in achieving high-quality results across various downstream tasks, the research team hopes to inspire further exploration of captioning as a pre-training task for vision encoders. With its simplicity, scalability, and efficiency, CapPa opens up exciting possibilities for advancing vision-based models and pushing the boundaries of multimodal learning.
Check Out The Paper. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.