Meet CelebV-Text: A Large-Scale Facial Text-Video Dataset Comprising 70,000 in-the-wild Face Video Clips with Diverse Visual Content

The disciplines of computer vision and computer graphics have recently paid a lot of attention to text-driven video production. Video material may be created and managed using text as an input, which has many uses in academics and business. Text-to-video production is still fraught with difficulties, particularly in the face-centric situation where the quality or relevancy of the video frames could be better. One of the main problems is the lack of a facial text-video dataset suitable for facial recognition and containing high-quality video samples and text descriptions of various attributes crucial for video recognition.
There are various difficulties in creating a high-quality face text-video collection in three areas. 1) Gathering of data: The amount and quality of video samples substantially influence the final videos’ quality. It isn’t easy to acquire a dataset of this size with high-quality samples while preserving a normal distribution and fluid video motion.
2) Annotation of data: Text-video pairings must be verified to be relevant. This calls for thorough text coverage to describe the information and motion seen in the video, such as the lighting and head movements.
3) Production of text: The creation of varied and authentic texts is complex. The production of manual text is costly and needs to be more scalable. Auto-text production can be readily expanded, but its naturalness is constrained.
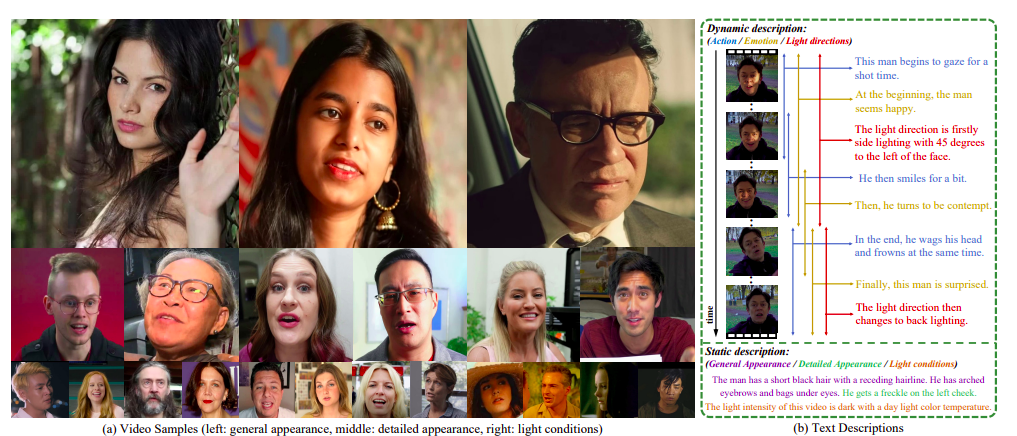
They meticulously plan a thorough data creation pipeline comprising data collecting and processing, data annotation, and semi-automatic text production to overcome the abovementioned issues. They start using CelebV-data HQ’s collecting procedures, which have successfully gotten raw footage. They make a small tweak to the processing stage to further enhance the smoothness of the video.
Then, they examine videos from both temporal dynamics and static material to ensure highly relevant text-video pairings. They construct a set of qualities that may or may not vary over time. Lastly, they suggest a semi-automatic template-based approach to producing varied and organic writing. Their strategy uses the benefits of both automatic and manual text techniques. To parse annotation and manual writings, they specifically build a vast range of grammar templates that can be dynamically mixed and adjusted to achieve great diversity, complexity, and naturalness.
Using the suggested pipeline, researchers from University of Sydney, SenseTime Research, NTU and Shanghai AI lab produce CelebV-Text, a Large-Scale Facial Text-Video Dataset, consisting of 1,400,000 word descriptions and 70,000 video clips from the wild, each with a minimum resolution of 512512. CelebV-Text combines high-quality video samples with text descriptions to create realistic face videos, as seen in Figure 1. Three categories of static attributes (40 general appearances, five detailed appearances, and six lighting conditions) and three categories of dynamic attributes are annotated for each video (37 actions, 8 emotions, and 6 light directions). Although manual texts are offered for labels that cannot be discretized, all dynamic attributes are extensively annotated with start and end timestamps.
They have also created three templates for each sort of characteristic, for 18 templates that may be combined in various ways. The produced texts for all properties and manuals are naturally described. Existing face video datasets can’t compete with CelebV-better Text’s resolution (over 2 times), greater sample size, and more varied distribution. Moreover, compared to text-video datasets, CelebV-Text sentences had greater diversity, richness, and naturalness. According to CelebVText’s text-video retrieval experiments, text-video pairs are highly relevant.
They assess CelebV-Text against a typical baseline for facial text-to-video generation to further investigate its efficacy and potential. Compared to a cutting-edge large-scale pretrained model, their findings demonstrate more relevance between produced face videos and words. In addition, they show how a specific change to using text interpolation may greatly enhance temporal coherence. To standardize the face text-to-video generation job, they provide a new creation benchmark comprising representative models on three text-video datasets.
The following is a summary of this work’s key contributions: 1) To aid in research on facial text-to-video production, they suggest CelebV-Text, the first large-scale facial text-video dataset featuring high-quality videos as rich and highly relevant words. 2) CelebV-Text is superior by thorough statistical analyses that look at video/text quality, diversity, and text-video relevance. 3) To show the efficiency and potential of CelebV-Text, many self-evaluations are conducted. 4) A new benchmark for the process is created to encourage the standardization of the facial text-to-video generation task.
Check out the Paper, Project and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.