Meet ChatLLaMA: The First Open-Source Implementation of LLaMA Based on Reinforcement Learning from Human Feedback (RLHF)
Meta has recently released LLaMA, a collection of foundational large language models ranging from 7 to 65 billion parameters.
LLaMA is creating a lot of excitement because it is smaller than GPT-3 but has better performance. For example, LLaMA’s 13B architecture outperforms GPT-3 despite being 10 times smaller. This new collection of fundamental models opens the door to faster inference performance and chatGPT-like real-time assistants while being cost-effective and running on a single GPU.
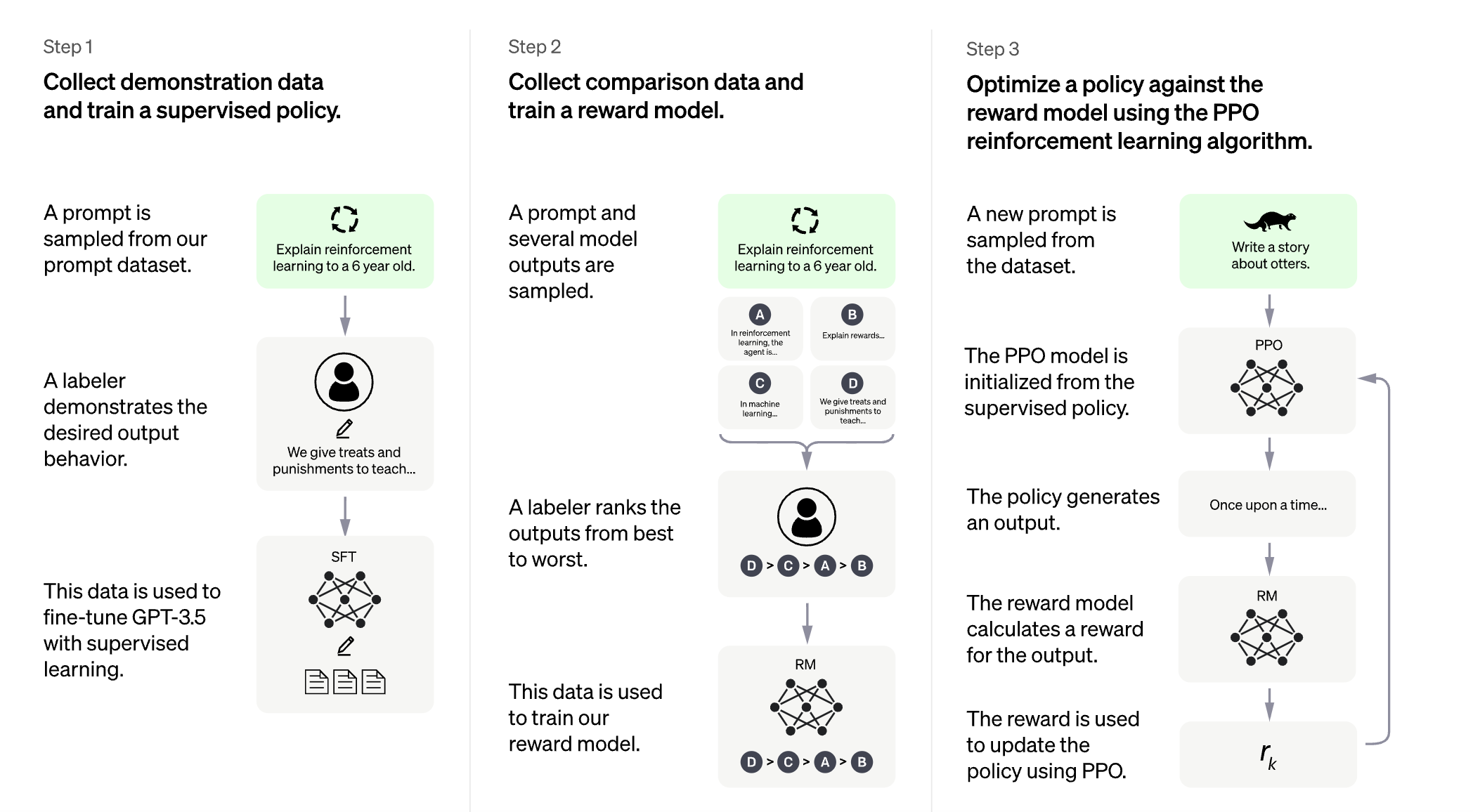
However, LLaMA was not fine-tuned for instruction tasks with a Reinforcement Learning from Human Feedback (RLHF) training process.
The good news is that today Nebuly has introduced ChatLLaMA, the first open-source implementation of LLaMA based on RLHF:
- A complete open-source implementation that enables you to build a ChatGPT-style service based on pre-trained LLaMA models.
- Compared to the original ChatGPT, the training process and single-GPU inference are much faster and cheaper by taking advantage of the smaller size of LLaMA architectures.
- ChatLLaMA has built-in support for DeepSpeed ZERO to speed up the fine-tuning process.
- The library also supports all LLaMA model architectures (7B, 13B, 33B, 65B), so that you can fine-tune the model according to your preferences for training time and inference performance.
If you like the project, please consider leaving a star on the GitHub repository
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
ChatLLaMA allows you to easily train LLaMA-based architectures in a similar way to ChatGPT using RLHF. For example, below is the code to start the training in the case of ChatLLaMA 7B.
from chatllama.rlhf.trainer import RLTrainer
from chatllama.rlhf.config import Config
path = "path_to_config_file.yaml"
config = Config(path=path)
trainer = RLTrainer(config.trainer)
trainer.distillate()
trainer.train()
trainer.training_stats.plot()
Note that you should provide Meta’s original weights and your custom dataset before starting the fine-tuning process. Alternatively, you can generate your own dataset using LangChain’s agents.
python generate_dataset.py
Nebuly has open-sourced the complete code to replicate the ChatLLaMA implementation, opening up the possibility for every user to fine-tune their own personalized ChatLLaMA assistants. The library can be further extended with the following additions:
- Checkpoints with fine-tuned weights
- Optimization techniques for faster inference
- Support for packaging the model into an efficient deployment framework
All developers are invited to join Nebuly’s efforts toward more efficient and open ChatGPT-like assistants.
You can participate in the following ways:
- Submit an issue or PR on GitHub
- Join their Discord group to chat
Note: Thanks to Nebuly’s team for the thought leadership/ Educational article above.
![]()
Asif Razzaq is the CEO of Marktechpost, LLC. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over a million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.