Meet Chroma: An AI-Native Open-Source Vector Database For LLMs: A Faster Way to Build Python or JavaScript LLM Apps with Memory
Word embedding vector databases have become increasingly popular due to the proliferation of massive language models. Using the power of sophisticated machine learning techniques, data is stored in a vector database. It allows for very fast similarity search, essential for many AI uses such as recommendation systems, picture recognition, and NLP.
The essence of complicated data is captured in a vector database by representing each data point as a multidimensional vector. Quickly retrieving related vectors is made possible by modern indexing techniques like k-d trees and hashing. To transform big data analytics, this architecture generates highly scalable, efficient solutions for data-heavy sectors.
Let’s have a look at Chroma, a small, free, open-source vector database.
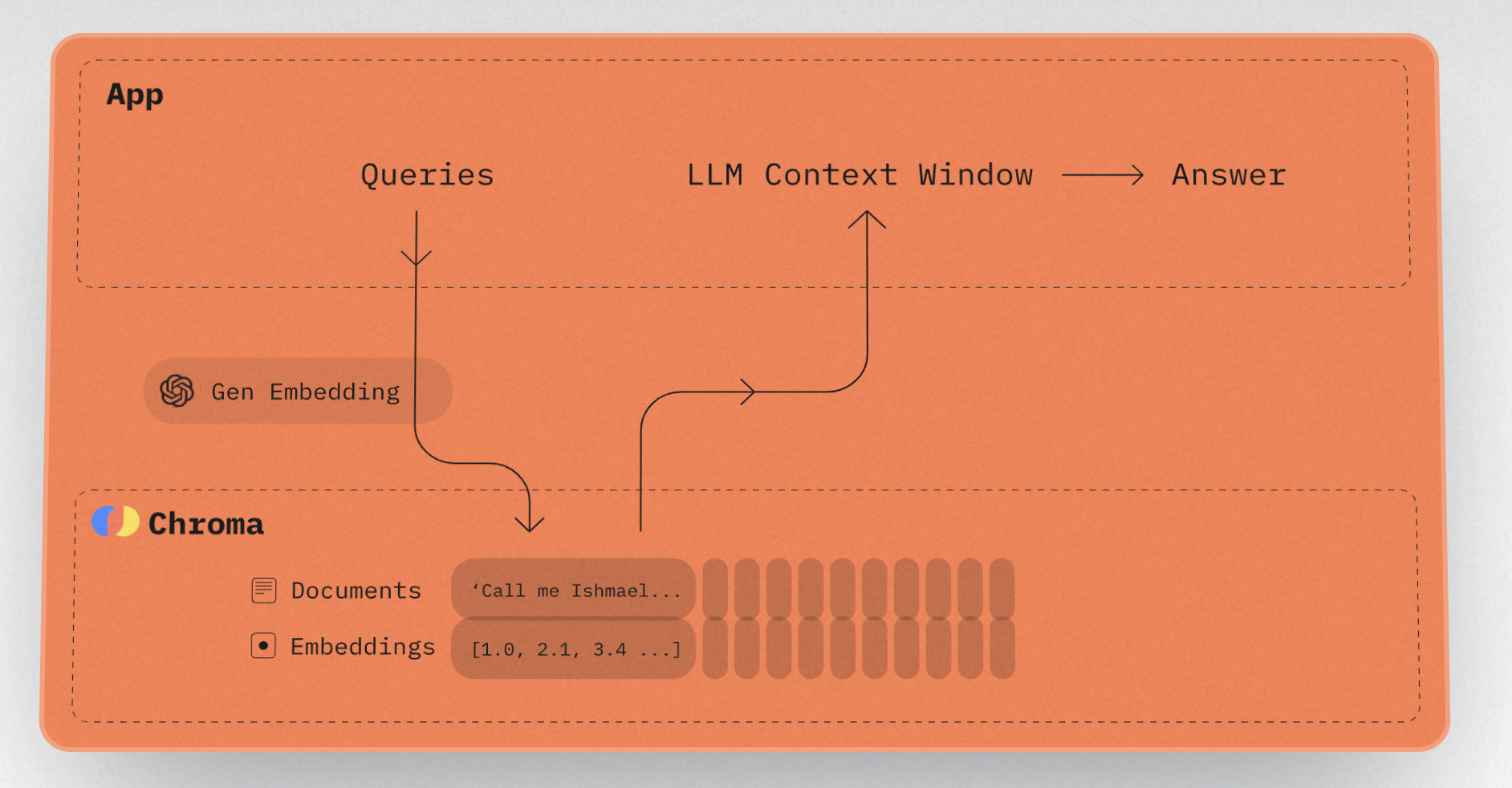
Chroma can be used to create word embeddings using Python or JavaScript programming. The database backend, whether in memory or client/server mode, can be accessed by a straightforward API. Installing Chroma and using the API in a Jupyter Notebook during prototyping allows developers to utilize the same code in a production setting, where the database may run in client/server mode.
Chroma database sets can be persisted to disk in Apache Parquet format when operating in memory. The time and resources required to generate word embeddings can be minimized by storing them to retrieve them later.
Each referenced string can have extra metadata that describes the original document. You can skip this step if you like. Researchers fabricated some metadata to use in the tutorial. Specifically, it’s organized as a collection of dictionary objects.
Chroma refers to groups of related media as collections. Each collection includes documents, which are just lists of strings, IDs, which serve as unique identifiers for the documents, and metadata (which is not required). Collections would only be complete with embeddings. They can be generated either implicitly using Chroma’s built-in word embedding model or explicitly using an external model based on OpenAI, PaLM, or Cohere. Chroma facilitates the incorporation of third-party APIs, making the generation and storage of embeddings an automated procedure.
By default, Chroma generates embeddings with an all-MiniLM-L6-v2 Sentence Transformers model. This embedding model can produce sentence and document embeddings for various applications. Depending on the situation, this embedding function may require the automatic download of model files and run locally on the PC.
Metadata (or IDs) can also be queried in the Chroma database. This makes it easy to search, depending on where the papers originated.
Key Features
- It’s easy: When everything is typed, tested, and documented.
- All three environments (development, testing, and production) can use the same API in the notebook.
- Rich in functionality: searches, filters, and density estimation.
- Apache 2.0 Licensed Open Source Software.
Check out the Try it here and Github page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.