Meet CLAMP: An New AI Tool For Molecular Activity Prediction That Can Adapt To New Experiments At Inference Time
For decades, the tasks involving predicting a molecule’s chemical, macroscopic, or biological properties based on its chemical structure have been a key scientific research problem. Many machine learning algorithms have been used in discovering correlations between the chemical structure and characteristics of such molecules due to significant technological advancements in recent years. Moreover, the onset of deep learning marked the introduction of activity prediction models, which are used to rank the remaining molecules for biological testing after removing molecules with undesirable features. These activity prediction models are the computational drug discovery industry’s major workhorses, and they can be compared to large language models in natural language processing and image classification models in computer vision. These deep learning-based activity prediction models make use of a variety of low-level chemical structure descriptions, including chemical fingerprints, descriptors, molecular graphs, the string representation SMILES, or a combination of these.
Even though these architectures have performed admirably, their advancements have not been as revolutionary as those in vision and language. Typically, pairs of molecules and activity labels from biological experimentations, or “bioassays,” are used to train activity prediction models. As the process of annotating training data (also known as bioactivities) is extremely time and labor-intensive, researchers are eagerly looking for methods that efficiently train activity prediction models on a lesser number of data points. Furthermore, current activity prediction algorithms are not yet capable of using comprehensive information about the activity prediction tasks, which is mostly given in the form of textual descriptions of the biological experiment. This is mostly due to the fact that these models need measurement data from the bioassay or activity prediction task on which they are trained or fine-tuned. Because of this, current activity prediction models cannot perform zero-shot activity prediction and have poor predictive accuracy for few-shot scenarios.
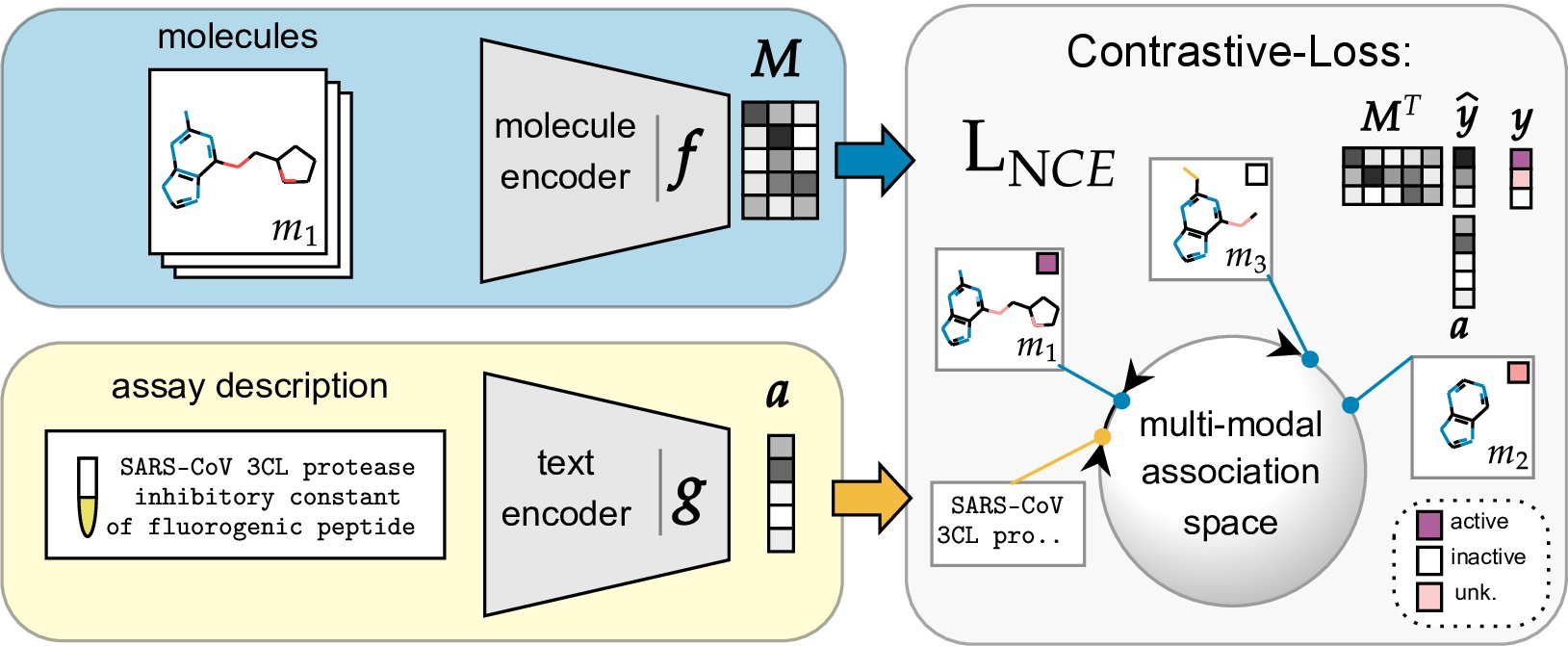
Because of its reported zero- and few-shot capabilities, researchers have turned to various scientific language models for low-data tasks. But these models significantly lack predictive quality when it comes to activity prediction. Working on this problem statement, a group of eminent researchers from the Machine Learning Department at the Johannes Kepler University Linz, Austria, discovered that using chemical databases as training or pre-training data and selecting an efficient molecule encoder can result in better activity prediction. In order to address this, they suggest Contrastive Language-Assay-Molecule Pre-training (or CLAMP), a novel architecture for activity prediction that can be conditioned on the textual description of the prediction task. This modularized architecture consists of a separate molecule and language encoder that are contrastively pre-trained across these two data modalities. The researchers also propose a contrastive pre-training objective on information contained in chemical databases as training data. This data contains orders of magnitudes more chemical structures than those contained in biomedical texts.
As previously indicated, CLAMP uses a trainable text encoder to create bioassay embeddings and a trainable molecule encoder to create molecule embeddings. These embeddings are assumed to be layer-normalized. The method put forth by Austrian researchers includes a scoring function as well, which provides high values when a molecule is active on a certain bioassay and low values when it is not. Additionally, the contrastive learning strategy gives the model the capability for zero-shot transfer learning, which, put simply, produces insightful predictions for unseen bioassays. According to several experimental evaluations conducted by the researchers, it was revealed that their methodology significantly improves predictive performance on few-shot learning benchmarks and zero-shot problems in drug discovery and yields transferable representations. The researchers believe that the modular architecture and pre-training objective of their model were the main reason behind its remarkable performance.
It is important to remember that although CLAMP performs admirably, there is still room for improvement. Many elements that affect the results of the bioassay, such as chemical dosage, are not taken into account. Moreover, there may be certain cases of incorrect predictions may be brought on by grammatical inconsistencies and negations. Nonetheless, the contrastive learning method CLAMP exhibits the best performance at zero-shot prediction drug discovery tasks on several large datasets.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.