Meet CMMMU: A New Chinese Massive Multi-Discipline Multimodal Understanding Benchmark Designed to Evaluate Large Multimodal Models LMMs
In the realm of artificial intelligence, Large Multimodal Models (LMMs) have exhibited remarkable problem-solving capabilities across diverse tasks, such as zero-shot image/video classification, zero-shot image/video-text retrieval, and multimodal question answering (QA). However, recent studies highlight a substantial gap between powerful LMMs and expert-level artificial intelligence, particularly in tasks involving complex perception and reasoning with domain-specific knowledge. This paper aims to bridge this gap by introducing CMMMU, a pioneering Chinese benchmark meticulously designed to evaluate LMMs’ performance on an extensive array of multi-discipline tasks, guiding the development of bilingual LMMs towards achieving expert-level artificial intelligence.
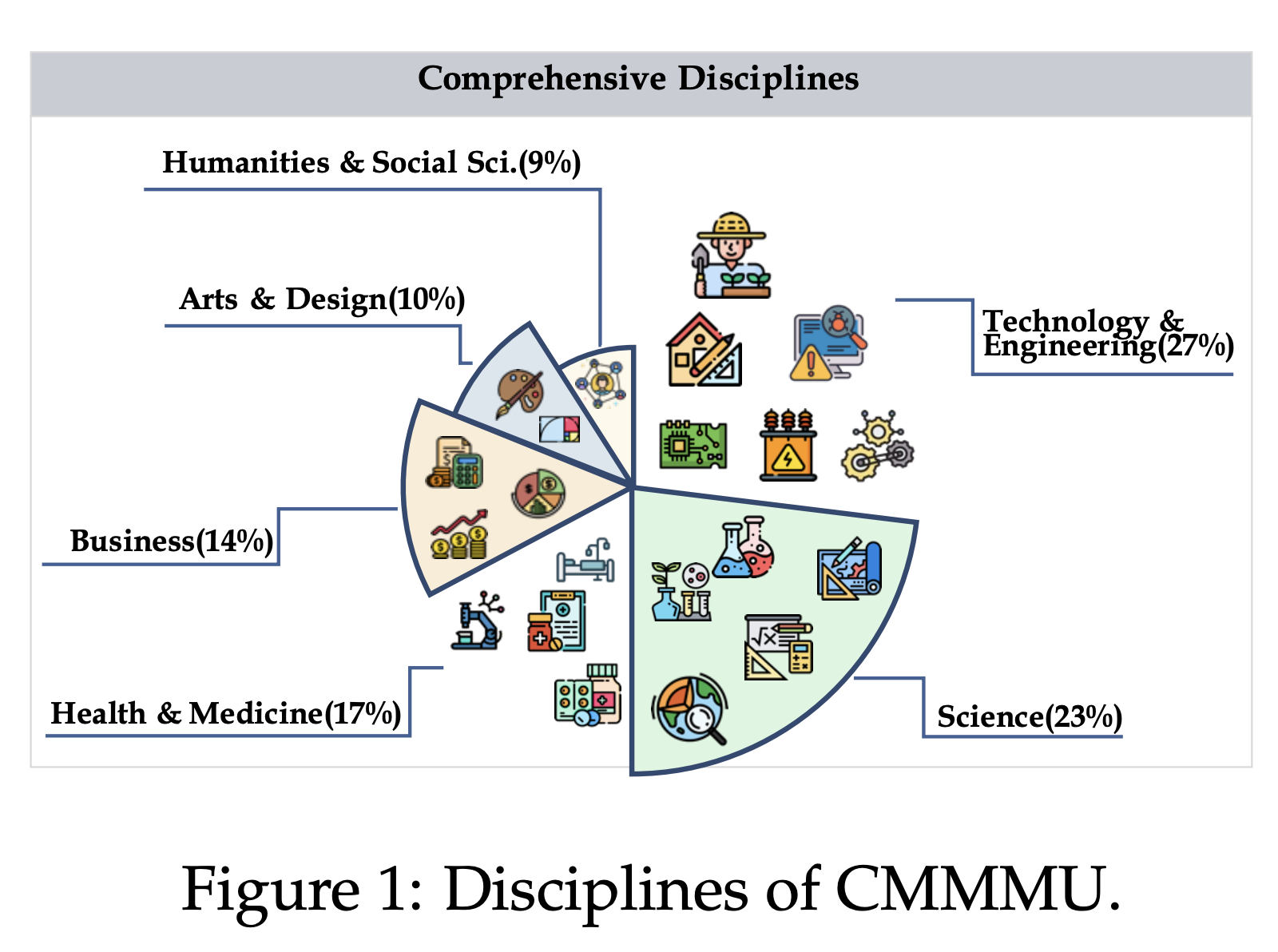
CMMMU (Chinese Massive Multi-discipline Multimodal Understanding) stands out as one of the most comprehensive benchmarks (some examples are shown in Figure 2), comprising 12,000 manually collected Chinese multimodal questions sourced from college exams, quizzes, and textbooks. These questions span six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. Other statistics are shown in Table 2. The benchmark not only evaluates LMMs on complex reasoning and perception tasks but also annotates each question with detailed subfields and image types, providing valuable insights into the types of questions that pose challenges for LMMs.
A three-stage data collection process ensures the richness and diversity of CMMMU. In the first stage, annotator organizers, mainly the authors, collect sources adhering to license requirements. In the second stage, crowdsourcing annotators, consisting of undergraduate students and individuals with higher degrees, further annotate the collected sources, strictly following key principles to filter out unqualified questions with images. The third stage involves supplementing questions to subjects needing more representation, ensuring a balanced dataset across disciplines.
A rigorous data quality control protocol is implemented to enhance data quality further. At least one of the paper’s authors manually verifies each question, filtering out questions with answers that are too challenging for LMMs to extract. Furthermore, questions not meeting college-level examination standards are meticulously removed. To address data contamination concerns, questions that can be correctly solved by multiple advanced LMMs simultaneously without OCR assistance are filtered out.
The evaluation includes large language models (LLMs) and large multimodal models (LMMs), considering both closed-source and open-source implementations. The zero-shot evaluation settings are used instead of fine-tuning or few-shot settings because it provides a raw assessment of the model’s ability to generate accurate answers on multimodal tasks. A systematic and rule-based evaluation pipeline, incorporating robust regular expressions and specific rules for different question types, ensures a comprehensive evaluation. Finally, they have adopted micro-average accuracy as the evaluation metric.
In addition, the paper also presents a thorough error analysis of 300 samples, showcasing instances where even top-performing LMMs, such as QwenVL-Plus and GPT-4V, answer incorrectly. The analysis, distributed among 30 subjects, highlights challenges leading advanced LMMs astray and underscores the long journey ahead toward achieving expert-level bilingual LMMs. Even the most advanced closed-source LMMs, GPT-4V and Qwen-VL-Plus, achieve only 42% and 36% accuracy, respectively, indicating significant room for improvement.
Interestingly, the study reveals a smaller performance gap between open-source and closed-source LMMs in a Chinese context compared to English. While the most powerful open-source LMM, Qwen-VL-Chat, achieves an accuracy of 28%, with a 14% gap compared to GPT-4V, the gap in English is 21%. Notably, Yi-VL-6B1, Yi-VL-34B2, and Qwen-VL-Chat outperform other open-source LMMs on CMMMU, emphasizing their potential in the Chinese language domain. Yi-VL-34B even narrows the performance gap between open-source LMMs and GPT-4V on CMMMU to 7%.
In conclusion, the CMMMU benchmark represents a significant advancement in the quest for Advanced General Intelligence (AGI). It serves as a meticulous evaluator of the latest Large Multimodal Models (LMMs), gauging their elementary perceptual skills, intricate logical reasoning, and profound domain-specific expertise. By comparing LMMs’ performance on CMMMU and MMMU, this research provides insights into the reasoning capacity of bilingual LMMs in Chinese and English contexts, paving the way for AGI that rivals seasoned professionals across diverse fields.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.