Meet CodeMind: A Machine Learning Framework Designed to Gauge the Code Reasoning Abilities of LLMs

Large Language Models (LLMs) have significantly shifted the paradigm of how machines interpret and generate human language. These models have demonstrated unparalleled prowess in converting natural language instructions into executable code, marking a monumental leap in machine learning capabilities. The conventional metrics for evaluating these models, primarily focused on code synthesis, barely scratch the surface of their potential. They need to sufficiently challenge the models to showcase their understanding of the intricacies of programming logic and functionality.

A team of researchers from the University of Illinois at Urbana-Champaign introduced CodeMind, a groundbreaking framework meticulously designed to evaluate the code reasoning abilities of LLMs. CodeMind diverges from the traditional test-passing rate benchmarks, offering a nuanced approach to assess models’ proficiency in understanding complex code structures, debugging, and optimization. This framework heralds a new era in the computational assessment of LLMs, emphasizing the importance of reasoning in programming tasks beyond mere code generation.
CodeMind presents three innovative code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). These tasks collectively aim to push the boundaries of LLM evaluation by testing models on their ability to generate code based on specifications and to understand deeply and reason about the code’s execution, behavior, and adherence to given specifications. IER and DER focus on the model’s capacity to predict execution outcomes of arbitrary and self-generated code, while SR assesses their ability to implement specified behavior accurately.
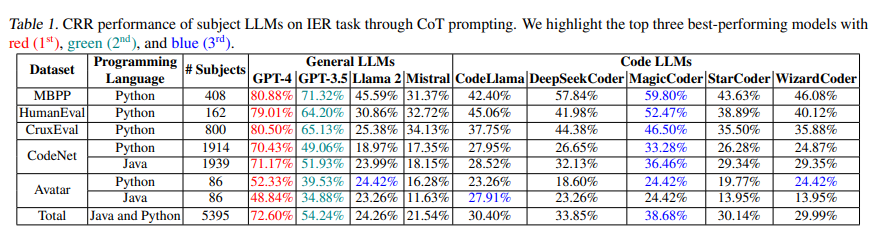
A rigorous evaluation of nine leading LLMs using the CodeMind framework has unveiled insightful findings about their code reasoning capabilities. The study meticulously analyzed the models’ performance across various programming benchmarks, revealing a notable proficiency in handling basic code constructs and simple execution paths. However, as the complexity of the tasks escalated, marked differences in performance emerged, particularly in scenarios involving intricate logic, arithmetic operations, and API calls. This variance highlights the existing challenges LLMs face in achieving a comprehensive understanding and reasoning about code, especially when navigating complex programming landscapes.
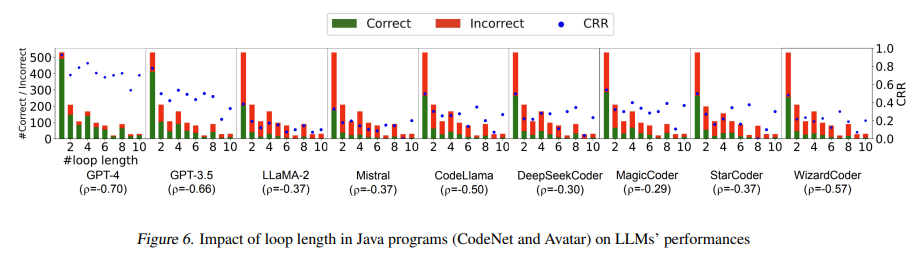
In conclusion, introducing CodeMind as an evaluation tool is critical to understanding and enhancing LLMs’ programming capabilities. This framework provides a more holistic view of models’ strengths and weaknesses in software development tasks by shifting the focus from code generation to code reasoning. The insights gained from this study contribute valuable knowledge to the field of artificial intelligence and pave the way for future advancements in developing LLMs with improved code reasoning skills.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.