Meet CoMoSpeech: A Consistency Model-Based Method For Speech Synthesis That Achieves Fast And High-Quality Audio Generation
With the growing human-machine interaction and entertainment applications, text-to-speech (TTS) and singing voice synthesis (SVS) tasks have been widely included in speech synthesis, which strives to generate realistic audio of people. Deep neural network (DNN)-based methods have largely taken over the field of speech synthesis. Typically, a two-stage pipeline is used, with the acoustic model converting text and other controlling information into acoustic features (such as mel-spectrograms) before the vocoder further converts the acoustic features into audible waveforms.
The two-stage pipeline has succeeded because it acts as a “relay” to solve the dimension-exploding issue of translating short texts to long audios with a high sampling frequency. Frames describe acoustic characteristics. The acoustic characteristic that the acoustic model produces, often a mel-spectrogram, significantly impacts the quality of the synthesized talks. Convolutional neural networks (CNN) and Transformers are frequently employed in industry-standard methods like Tacotron, DurIAN, and FastSpeech to forecast the mel-spectrogram from the governing component. The ability of diffusion model approaches to generate high-quality samples has gained a lot of interest. The two processes that make up a diffusion model, also known as a score-based model, are a diffusion process that gradually perturbs data into noise and a reverse process that slowly transforms noise back to data. The diffusion model’s need for several iterations for generation is a serious flaw. Several techniques based on the diffusion model have been suggested for acoustic modeling in voice synthesis. The sluggish generating speed issue still exists in most of these works.
Grad-TTS developed a stochastic differential equation (SDE) to solve the reverse SDE, which is utilized to solve the noise to mel-spectrogram transformation. Despite producing great audio quality, the inference speed is slow since the reverse method requires a lot of iterations (10–1000). Progressive distillation was added to Prodiff when it was being developed further to minimize the sample processes. DiffGAN-TTS used an adversarially-trained model in Liu et al. to roughly represent the denoising function for effective voice synthesis. The ResGrad in Chen et al. estimates the prediction residual from pre-trained FastSpeech2 and ground truth using the diffusion model.
From the description above, it is clear that speech synthesis has three goals:
• Excellent audio quality: The generative model should faithfully capture the subtleties of the speaking voice that add to the expressiveness and naturalness of the synthesized audio. Recent research has focused on voices with more intricate changes in pitch, timing, and emotion in addition to the distinctive speaking voice. Diffsinger, for instance, demonstrates how a well-designed diffusion model may provide a synthesized singing voice of good quality after 100 iterations. Additionally, it’s important to prevent artifacts and distortions in the created audio.
• Quick inference: Quick audio synthesis is necessary for real-time applications, including communication, interactive speech, and music systems. Simply being quicker than real-time for voice synthesis is insufficient when making time for other algorithms in an integrated system.
• Beyond speaking: More intricate voice modeling, such as singing voice, is needed in place of the distinctive speaking voice in terms of pitch, emotion, rhythm, breath control, and timbre.
Although numerous attempts have been made, the trade-off issue between the synthesized audio quality, model capability, and inference speed persists in TTS. It is more obvious in SVS due to the mechanism of the denoising diffusion process when performing the sampling. Existing approaches often aim to mitigate rather than completely resolve the slow inference problem. Despite this, they must be faster than traditional approaches without using diffusion models like FastSpeech2.
The consistency model has recently been developed, producing high-quality images with just one sampling step by expressing the stochastic differential equation (SDE), describing the sampling process as an ordinary differential equation (ODE), and further enforcing the consistency property of the model on the ODE trajectory. Despite this accomplishment in picture synthesis, there currently needs to be a known voice synthesis model based on the consistency model. This suggests that it is possible to develop a consistent model-based voice synthesis technique that combines high-quality synthesis with quick inference speed.
In this study, researchers from Hong Kong Baptist University, Hong Kong University of Science and Technology, Microsoft Research Asia and Hong Kong Institute of Science & Innovation offer CoMoSpeech, a swift and high-quality speech synthesis approach based on consistency models. Their CoMoSpeech is derived from an instructor who has already received training. More specifically, their teacher model uses the SDE to learn the matching scoring function and smoothly translate the mel-spectrogram into the Gaussian noise distribution. After training, they build the teacher denoiser function using the associated numerical ODE solvers, which is then utilized for further consistency distillation. Their CoMoSpeech with consistent characteristics is produced by distillation. Ultimately, their CoMoSpeech can generate high-quality audio with a single sample step.
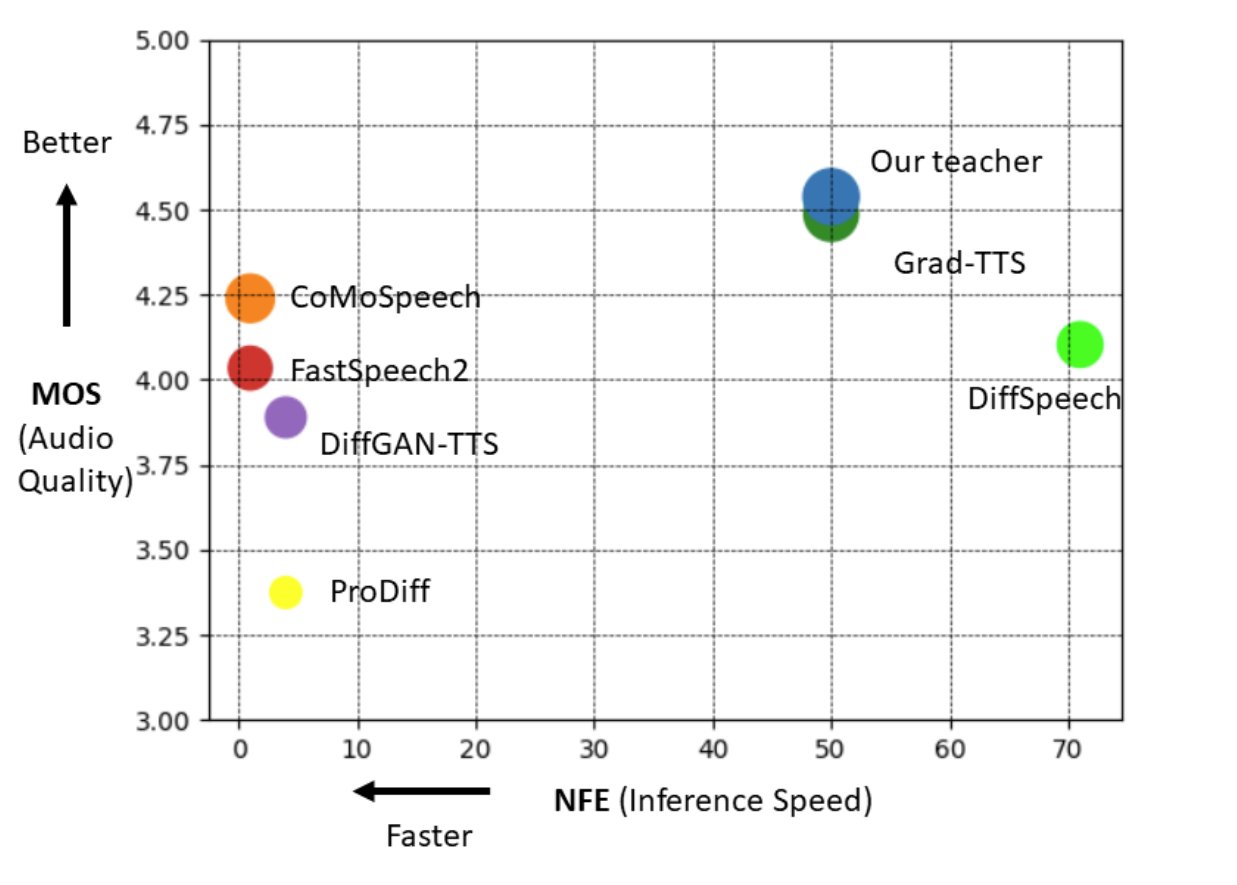
The findings of their TTS and SVS trials demonstrate that the CoMoSpeech can produce monologues with a single sample step, which is more than 150 times quicker than in real-time. The study of audio quality also reveals that CoMoSpeech provides audio quality that is superior to or on par with other diffusion model techniques that need tens to hundreds of iterations. The diffusion model-based speech synthesis is now practicable for the first time. Several audio examples are given on their project website.
Check out the Paper and Project. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.