Meet ControlVideo: A Novel AI Method For Text-Driven Video Editing
Text-driven video editing aims to create new videos out of text prompts and existing video material without any manual labor. This technology has the potential to substantially impact various industries, including social media content, marketing, and advertising. The modified films must accurately reflect the content of the original video, retain temporal coherence between created frames, and line up with the target prompts to be successful in this process. Nevertheless, it can be challenging to meet all these demands simultaneously. It takes a lot of computing power to train a text-to-video model using just large amounts of text-video data.
The zero-shot and one-shot text-driven video editing approaches have used recent developments in large-scale text-to-image diffusion models and programmable picture editing. With no extra video data needed, these advancements have demonstrated a good ability to alter films in response to a range of textual commands. Nevertheless, empirical data reveals that current techniques still fail to properly and appropriately manage the output while maintaining temporal consistency, despite the tremendous advancements in aligning work with text cues. Researchers from Tsinghua University, Renmin University of China, ShengShu, and Pazhou Laboratory introduce ControlVideo, a cutting-edge method based on a pretrained text-to-image diffusion model for faithful and reliable text-driven video editing.
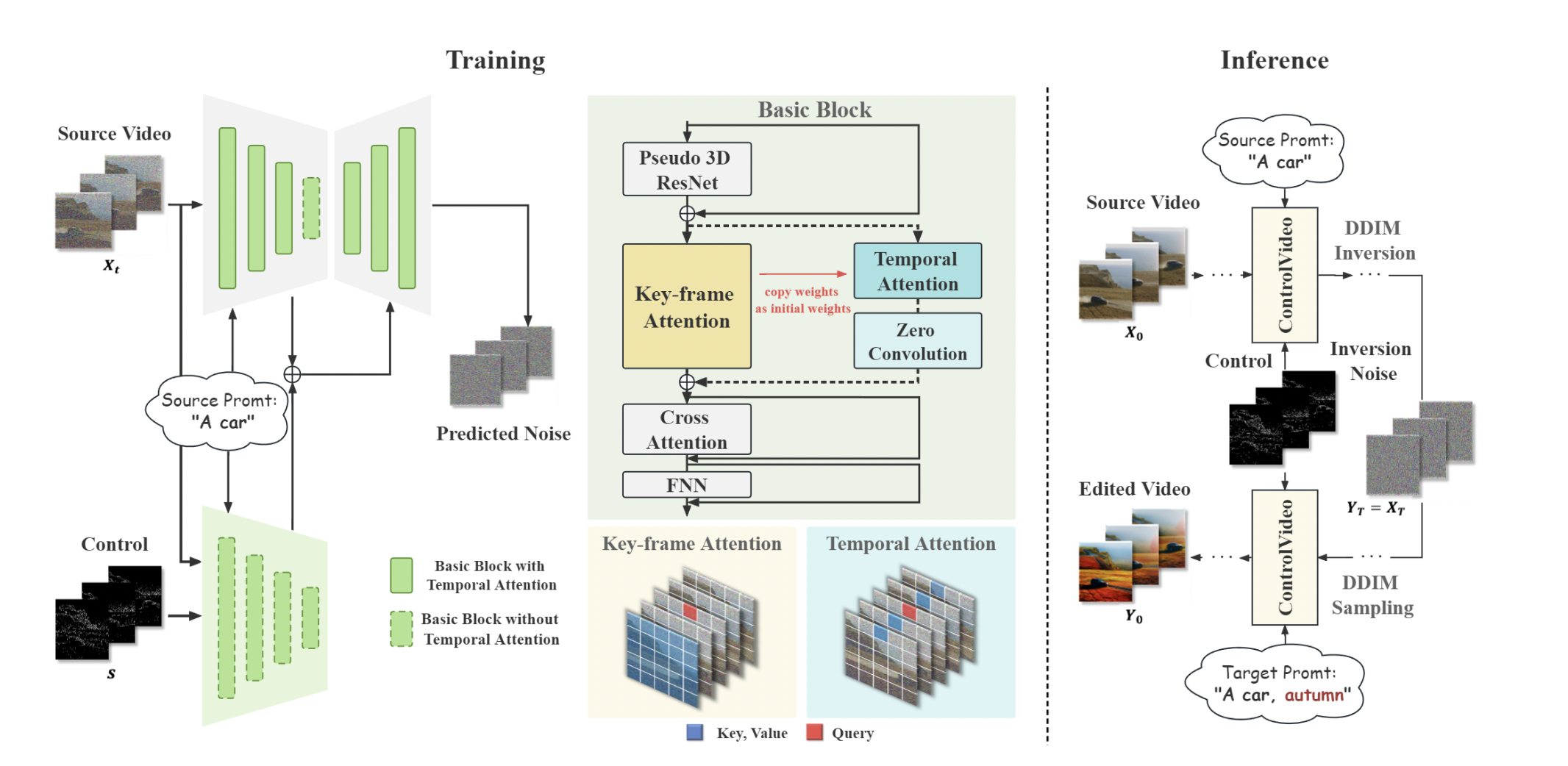
Drawing inspiration from ControlNet, ControlVideo amplifies the source video’s direction by including visual conditions such as Canny edge maps, HED borders, and depth maps for all frames as extra inputs. A ControlNet pretrained on the diffusion model handles these visual circumstances. Comparing such circumstances to the text and attention-based tactics now utilized in text-driven video editing approaches, it is noteworthy that they offer a more precise and adaptable manner of video control. Additionally, to improve fidelity and temporal consistency while avoiding overfitting, the attention modules in both the diffusion model and ControlNet have been painstakingly built and fine-tuned.
To be more precise, they change the initial spatial self-attention in both models into keyframe attention, lining up all frames with a chosen one. The diffusion model also includes temporal attention modules as additional branches, followed by a zero convolutional layer to preserve the output before fine-tuning. They use the original spatial self-attention weights as initialization for both keyframe and temporal attention in the corresponding network because it has been observed that different attention mechanisms model the relationships between different positions but consistently model the relationships between image features.
To guide future research on video diffusion model backbones for one-shot tuning, they perform a comprehensive empirical investigation of ControlVideo’s essential elements. This work investigates key and value designs, parameters for self-attention fine-tuning, initialization techniques, and including local and global locations for introducing temporal attention. According to their findings, the main UNet, except the middle block, may be trained to operate at its best by choosing a keyframe as both key and value, fine-tuning WO, and combining temporal attention with self-attention (keyframe attention in this study).
They also carefully examine each component’s contributions as well as the overall impact. Following the work, they gather 40 video-text pairs for examination, including the Davis dataset and others from the internet. Under many measures, they compare with frame-wise Stable Diffusion and SOTA text-driven video editing techniques. In particular, they employ the SSIM score to gauge fidelity and the CLIP to assess text alignment and temporal consistency. They also conduct user research comparing ControlVideo to all baselines.
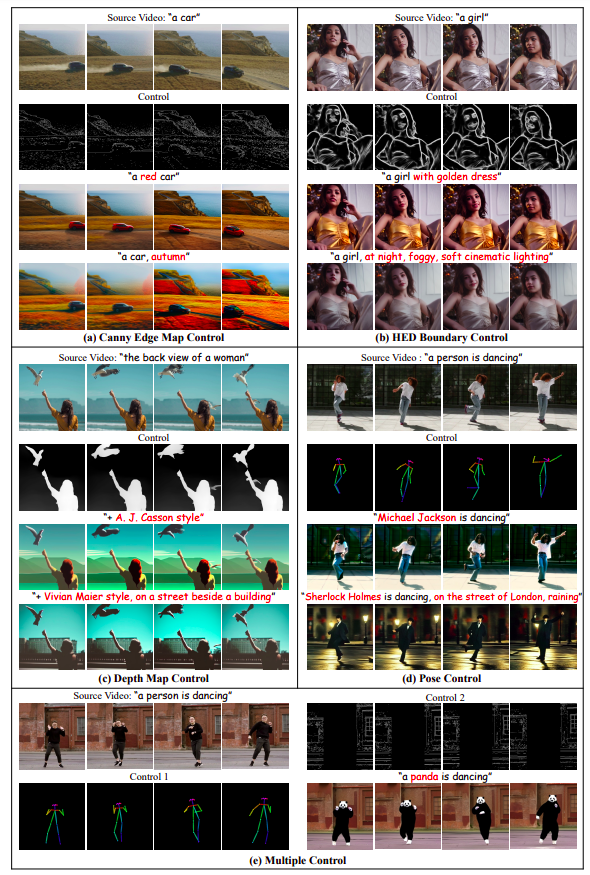
Numerous findings show that ControlVideo performs comparably to text alignment while significantly outperforming all of these baselines regarding fidelity and temporal consistency. Their empirical results, in particular, highlight ControlVideo’s alluring capacity to create films with incredibly lifelike visual quality and to maintain source material while adhering to written instructions reliably. For instance, ControlVideo succeeds where all other technologies fail in cosmetics while preserving a person’s distinctive facial features.
Additionally, ControlVideo allows for a customizable trade-off between the fidelity and editability of the video by utilizing a variety of control types that incorporate different amounts of information from the original video (see Figure 1). HED boundary, for instance, offers precise boundary details of the original video and is appropriate for tight control like face video editing. Pose includes the motion data from the original video, giving the user more freedom to modify the subject and backdrop while preserving motion transfer. Additionally, they show how it is possible to mix several controls to benefit from the advantages of various control kinds.
Check Out The Paper and Project. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com.
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.