Meet ConvNeXt V2: An AI Model That Improves the Performance and Scaling Capability of ConvNets Using Masked Autoencoders
The computer vision domain has seen significant advancement in the last decade, and this advancement can be mainly attributed to the emergence of convolutional neural networks (CNNs). CNNs’ impeccable abilities to process 2D data, thanks to their hierarchical feature extraction mechanism, was a key factor behind their success.
Modern CNNs have come a long way since their introduction. Updated training mechanisms, data augmentations, enhanced network design paradigms, and more. The literature is full of successful examples of these proposals that made CNNs much more powerful and efficient.
On the other hand, the open-source aspect of the computer vision domain has contributed to significant improvements. Thanks to wide-available pre-trained large-scale visual models, feature learning became much more efficient; thus, starting from scratch was not the case for the majority of vision models.
Nowadays, the performance of a vision model is mainly determined by three factors: the chosen neural network architecture, the training method, and the training data. The advancement in any of these trio results in a significant boost in overall performance.
Out of these three, the innovations in network architecture have played the utmost importance in the advancement. CNNs removed the need for manual feature engineering by allowing the use of generic feature learning methods. Not so long ago, we had the breakthrough of transformer architectures in the natural language processing domain, and they were transferred to the vision domain. Transformers were quite successful thanks to their strong scaling capability in both data and model size. Then finally, in recent years, the ConvNeXt architecture was introduced. It modernized the traditional convolutional networks and showed us pure convolution models could also be capable of scaling.
Though, we have a minor problem here. All these “advancements” were measured through a single computer vision task, supervised image recognition performance on ImageNet. It is still the most common method for exploring the design space for neural network architectures.
On the other hand, we have researchers looking at a different way of teaching neural networks how to process images. Instead of using labeled images, they’re using a self-supervised approach where the network has to figure out what’s in the image on its own. Masked autoencoders are one of the most popular ways to achieve this. They are based on the masked language modeling technique, which is widely used in natural language processing.
It is possible to mix and match different techniques when training neural networks, but it is tricky. One can combine the ConvNeXt with masked autoencoders. Though, since masked autoencoders are designed to work best with transformers to process sequential data, it may be computationally too expensive to use them with convolutional networks. Also, the design may not be compatible with convolutional networks due to the sliding window mechanism. And previous research has shown that it can be tough to get good results when using self-supervised learning methods like masked autoencoders with convolutional networks. Therefore, it is crucial to keep in mind that different architectures may have different feature learning behaviors that can impact the quality of the final result.
This is where ConvNeXt V2 comes into play. It is a co-design architecture that uses the masked autoencoder in the ConvNeXt framework to achieve results similar to those obtained using transformers. It is a step towards making mask-based self-supervised learning methods effective for ConvNeXt models.
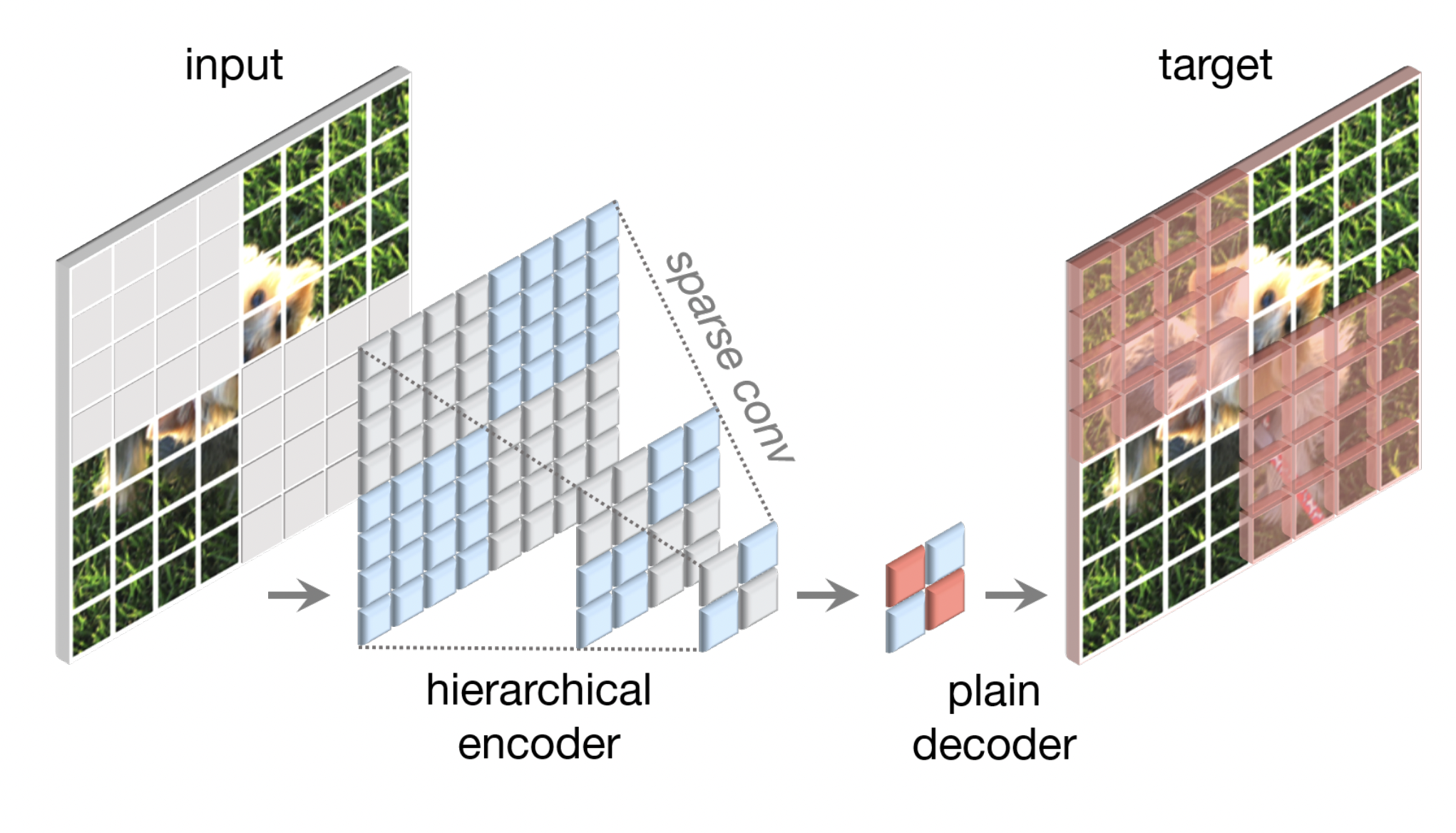
Designing the masked autoencoder for ConvNeXt was the first challenge, and they solved it in a smart way. They treat the masked input as a set of sparse patches and use sparse convolutions to process only the visible parts. Moreover, the transformer decoder part in the masked autoencoder is replaced with a single ConvNeXt block, which makes the entire structure fully convolutional, which in return improves the pre-training efficiency.
Finally, a global response normalization layer is added to the framework to enhance the inter-channel feature competition. Though, this change is effective when the model is pre-trained with masked autoencoders. Therefore, reusing a fixed architecture design from supervised learning may be suboptimal.
ConvNeXt V2 improves the performance when it is used together with masked autoencoders. It is specifically designed for self-supervised learning tasks. Using the fully convolutional masked autoencoder pre-training can significantly improve the performance of pure convolutional networks.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.