Meet CT2Hair: A Fully Automatic Framework for Creating High-Fidelity 3D Hair Models that are Suitable for Use in Downstream Graphics Applications
Who doesn’t like gaming? The more natural and fashioned the characters in the game, the more we enjoy it. Is it possible to have graphics that look exactly like natural hair?
Apart from 3D hair authoring tools, the manual creation by artists is both time-consuming and difficult to scale and can also be biased by the limitations of current 3D authoring tools. Creating a large dataset that accurately represents a wide range of real-world hair variations like curly, silky, straight, and wavy is a big challenge. Researchers at State Key Labs and Meta Reality Labs succeeded in reconstructing various hairstyle graphics from real-world hair wigs as input.
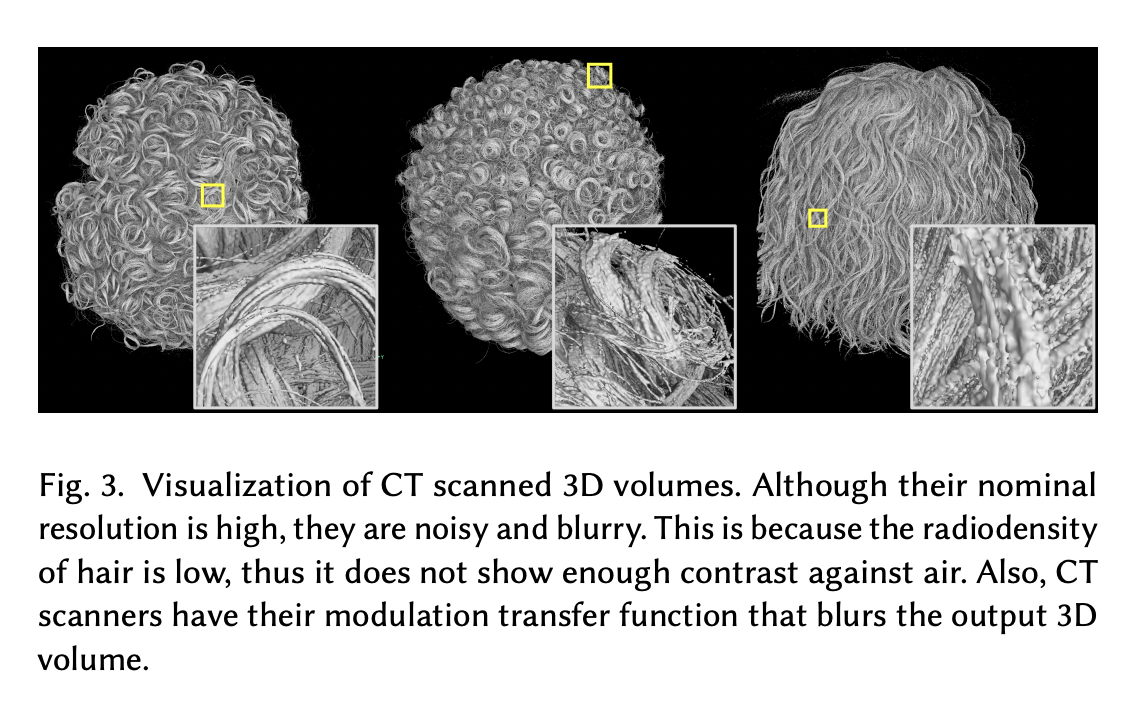
Researchers created density volumes of hair regions, which allows them to see through the hair, unlike the image-based approaches of visible surfaces. The method implemented to create density volumes was computed tomography (CT). They employed CT using X-rays for high resolution and large scan volumes. CT X-rays are usually used to reconstruct human tissues or general objects. Due to the thin structure of the hair strand, recovering a complete human hair strand from CT is a non-trivial task. This will inherit noise in CT imaging and decrease the resolution. To address this issue, they follow a coarse-to-fine approach.
They first estimate a 3D orientation field from a noisy density volume ( a real hair wig ) and extract useful guide strands using the estimated orientation field. They then populate the scalp with strands using a neural interpolation method and finally refine it with optimization such that they accurately conform to the input density volume. The optimization step involves better aligning the reconstructed hair strands with the input volume. Their work doesn’t include hand-crafted priors for particular hair types so that they can recover diverse hairstyles in a single framework.
Researchers compared their methods with the other three image-based methods, which are single-view-based, sparse-view-based and dense-view-based. They found that single-view-based and sparse-view-based methods produced reasonable results for relatively simple hairstyles but failed hugely in curly hair due to a lack of training datasets. The dense-view-based process surpassed those two methods but failed in inferring interior geometry and, as a result, produced incomplete geometry. In contrast, the researcher’s model showed good geometry and contained more details, which made them look realistic.
However, extending this ideology to capture real human heads remains challenging. Industry CT scanners use large exposure of X-rays that exceeds the safety limit for living organisms, so modeling the face’s geometry using this is not feasible. Researchers say that even a subtle motion during the capture will lead to substantial blurriness in the density volume.
By implementing machine learning approaches, future work may generate a large corpus of high-quality 3D hair data, enabling them to infer 3D hair models even from low-resolution density volumes using medical CT scanners.
Check out the Paper, GitHub Page, and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.