Meet DALL-E-Bot: An Artificial Intelligence (AI) Based Robotics System That Gives Web-Scale Diffusion Models An Embodiment To Realise The Scenes That They Imagine
Nowadays, it is difficult to pass a day without reading/hearing about a new application of diffusion models if you are following the news about artificial intelligence/machine learning. The massive success of diffusion models like DALL-E and Stable Diffusion has attracted enormous attention to these applications.
Diffusion models excel at text-to-X generation. They use the Web as the source of data. The Internet, specifically the Web, is a very rich dataset if you know how to collect the data. There are millions of data pairs available for any application you can think of, from image-caption pairs to text conversations. Web-based diffusion models collect this information, and they are trained on them. Given a text prompt, these models develop a language-conditioned distribution across natural images from which unique images can be created.
If you are following the domain, you have already seen the impressive images or videos generated by diffusion models. They can produce visually pleasing images that sometimes push our imaginations to their limits.
What if we could go deeper? What if we use these generated images to train another AI model to achieve a task? How about teaching a robot to do something? That’s the question DALL-E-Bot tries to answer.
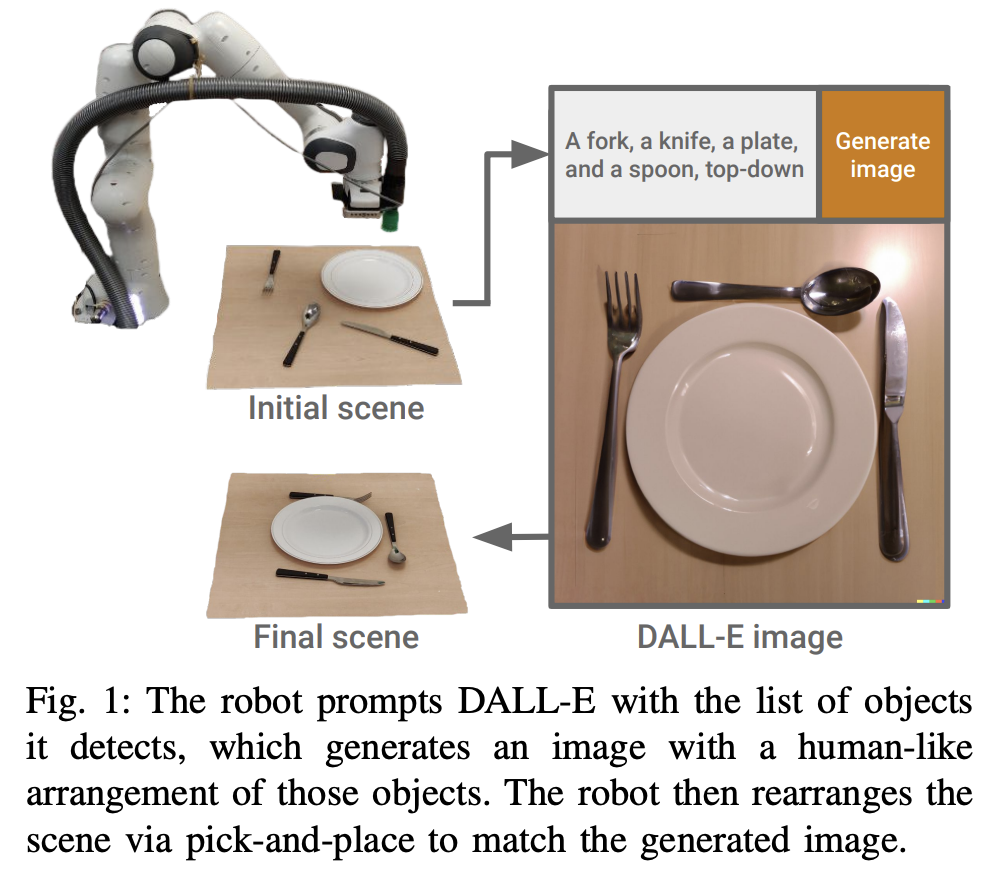
DALL-E-Bot tries to tackle the object rearrangement problem. Since diffusion models can generate realistic images, the authors wanted to examine their capabilities of arranging objects in the scene in a natural way. For example, “kitchen tabletop with utensils” prompt will generate a realistic-looking image where the utensils and the plate are neatly placed if you pass it to DALL-E. Based on this observation, DALL-E-Bot uses a diffusion model to generate the goal for the robot. Once the robot sees this image, it will know what the final object arrangement should look like.
Automating the goal states eliminates the cumbersome process of aligning them manually with human values. So, this is where web-scale diffusion is a powerful solution: natural distributions of objects can be modeled in a scalable, unsupervised manner.
We understood what the goal is, but how does DALL-E-Bot achieve it? Let us try to answer this question.
DALL-E-Bot uses a diffusion model to generate the goal state and how the objects should look at the end for the robot. Since diffusion models are text-to-image models, the first step is to capture the initial scene and somehow convert it to text. They found a clever way to do this conversion using an image captioning model.
This conversion starts with finding the object segmentations in the input image using Mask R-CNN. Once the segmentation masks for each object are obtained, they are passed to the CLIP model to get the image captions. CLIP will explain what is in the image, converting the input image into a text representation.
Now we have our text prompt to generate the goal image. They use the publicly available DALL-E model without any fine-tuning. So, DALL-E-Bot is actually a zero-shot autonomous rearrangement model. The text prompt obtained in the previous step is passed to the DALL-E model and the goal image is generated.
At this step, the model knows how objects should be arranged at the end. To pass this information to the robot, the goal image generated by DALL-E is passed through the Mask R-CNN and CLIP models again. These extracted visual semantic features are matched with the input image ones, and the final position information is obtained by aligning segmentation masks of the objects. Therefore, the robot knows how and where to move each object in the input image. Finally, the robot performs these modifications by employing a suction gripper to perform a series of pick-and-place operations.
In the end, DALL-E-Bot achieved impressive results in everyday object rearrangement. The results were found satisfactory by human users. DALL-E-Bot provides an embodiment for web-scale diffusion models to realize the sceneries they envision.
This was a brief summary of DALL-E-Bot. You can find more information in the links below if you are interested in learning more.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'DALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and project.
Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.