Meet DeepCache: A Simple and Effective Acceleration Algorithm for Dynamically Compressing Diffusion Models during Runtime
Advancements in Artificial Intelligence (AI) and Deep Learning have brought a great transformation in the way humans interact with computers. With the introduction of diffusion models, generative modeling has shown remarkable capabilities in various applications, including text generation, picture generation, audio synthesis, and video production.
Though diffusion models have been showing superior performance, these models frequently have high computational costs, which are mostly related to the cumbersome model size and the sequential denoising procedure. These models have a very slow inference speed, to address which a number of efforts have been made by researchers, including reducing the number of sample steps and lowering the model inference overhead per step using techniques like model pruning, distillation, and quantization.
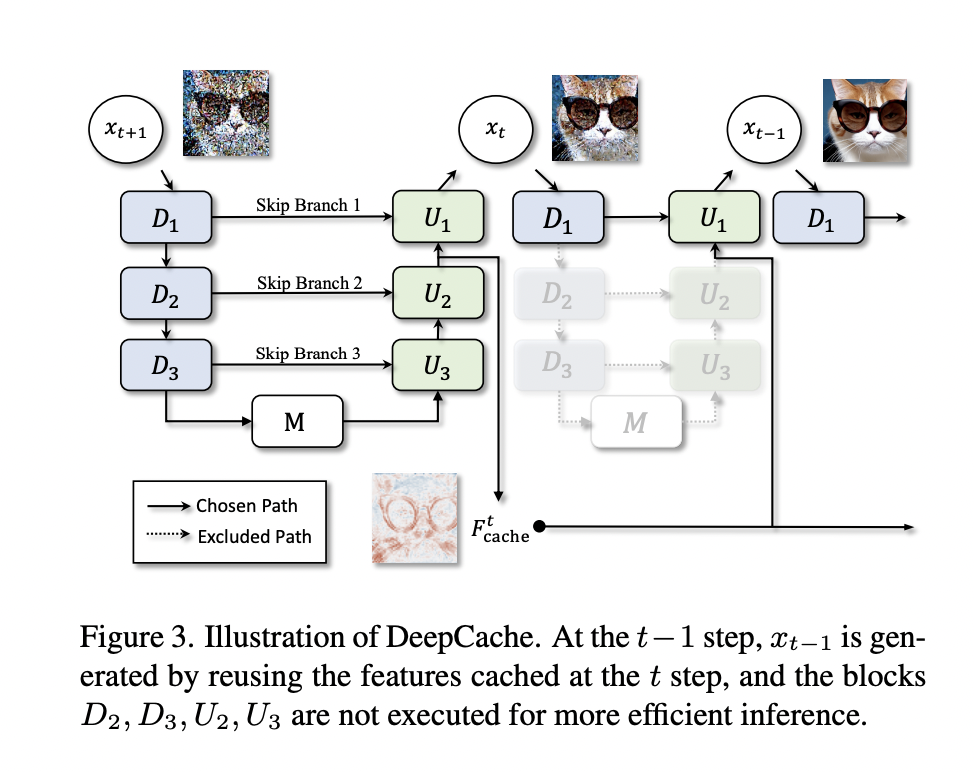
Conventional methods for compressing diffusion models usually need a large amount of retraining, which poses practical and financial difficulties. To overcome these problems, a team of researchers has introduced DeepCache, a new and unique training-free paradigm that optimizes the architecture of diffusion models to accelerate diffusion.
DeepCache takes advantage of the temporal redundancy that is intrinsic to the successive denoising stages of diffusion models. The reason for this redundancy is that some features are repeated in successive denoising steps. It substantially reduces duplicate computations by introducing a caching and retrieval method for these properties. The team has shared that this approach is based on the U-Net property, which permits high-level features to be reused while effectively and economically updating low-level features.
DeepCache’s creative approach yields a significant speedup factor of 2.3× for Stable Diffusion v1.5 with only a slight CLIP Score drop of 0.05. It has also demonstrated an impressive speedup of 4.1× for LDM-4-G, albeit with a 0.22 loss in FID on ImageNet.
The team has evaluated DeepCache, and the experimental comparisons have shown that DeepCache performs better than current pruning and distillation techniques, which usually call for retraining. It has even been shown to be compatible with existing sampling methods. It has shown similar, or slightly better, performance with DDIM or PLMS at the same throughput and thus maximizes efficiency without sacrificing the caliber of produced outputs.
The researchers have summarized the primary contributions as follows.
- DeepCache works well with current fast samplers, demonstrating the possibility of achieving similar or even better-generating capabilities.
- It improves image generation speed without the need for extra training by dynamically compressing diffusion models during runtime.
- By using cacheable features, DeepCache reduces duplicate calculations by using temporal consistency in high-level features.
- DeepCache improves feature caching flexibility by introducing a customized technique for extended caching intervals.
- DeepCache exhibits greater efficacy under DDPM, LDM, and Stable Diffusion models when tested on CIFAR, LSUN-Bedroom/Churches, ImageNet, COCO2017, and PartiPrompt.
- DeepCache performs better than retraining-required pruning and distillation algorithms, sustaining its higher efficacy under the
In conclusion, DeepCache definitely shows great promise as a diffusion model accelerator, providing a useful and affordable substitute for conventional compression techniques.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.