Meet DenseDiffusion: A Training-free AI Technique To Address Dense Captions and Layout Manipulation In Text-to-Image Generation

Recent advancements in text-to-image models have led to sophisticated systems capable of generating high-quality images based on brief scene descriptions. Nevertheless, these models encounter difficulties when confronted with intricate captions, often resulting in the omission or blending of visual attributes tied to different objects. The term “dense” in this context is rooted in the concept of dense captioning, where individual phrases are utilized to describe specific regions within an image. Additionally, users face challenges in precisely dictating the arrangement of elements within the generated images using only textual prompts.
Several recent studies have proposed solutions that empower users with spatial control by training or refining text-to-image models conditioned on layouts. While specific approaches like “Make-aScene” and “Latent Diffusion Models” construct models from the ground up with both text and layout conditions, other concurrent methods like “SpaText” and “ControlNet” introduce supplementary spatial controls to existing text-to-image models through fine-tuning. Unfortunately, training or fine-tuning a model can be computationally intensive. Moreover, the model necessitates retraining for every novel user condition, domain, or base text-to-image model.
Based on the abovementioned issues, a novel training-free technique termed DenseDiffusion is proposed to accommodate dense captions and provide layout manipulation.
Before presenting the main idea, let me briefly recap how diffusion models work. Diffusion models generate images through sequential denoising steps, starting from random noise. Noise prediction networks estimate noise added and try to render a sharper image at each step. Recent models reduce the number of denoising steps for faster results without significantly compromising the generated image.
Two essential blocks in state-of-the-art diffusion models are the self-attention and cross-attention layers.
Within a self-attention layer, intermediate features additionally function as contextual features. This enables the creation of globally consistent structures by establishing connections among image tokens spanning various areas. Simultaneously, a cross-attention layer adapts based on textual features obtained from the input text caption, employing a CLIP text encoder for encoding.
Rewinding, the main idea behind DenseDiffusion is the revised attention modulation process, which is presented in the figure below.
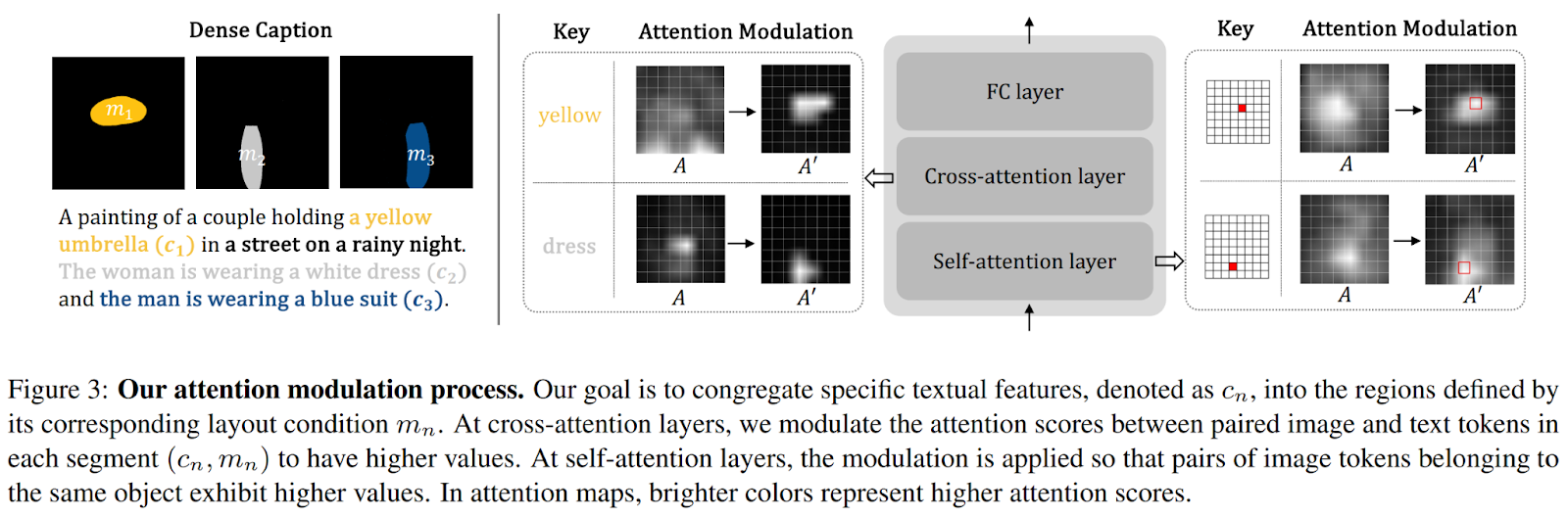
Initially, the intermediary features of a pre-trained text-to-image diffusion model are scrutinized to reveal the substantial correlation between the generated image’s layout and self-attention and cross-attention maps. Drawing from this insight, intermediate attention maps are dynamically adjusted based on the layout conditions. Furthermore, the approach involves considering the original attention score range and fine-tuning the modulation extent based on each segment’s area. In the presented work, the authors demonstrate the capability of DenseDiffusion to enhance the performance of the “Stable Diffusion” model and surpass multiple compositional diffusion models in terms of dense captions, text and layout conditions, and image quality.
Sample outcome results selected from the study are depicted in the image below. These visuals provide a comparative overview between DenseDiffusion and state-of-the-art approaches.

This was the summary of DenseDiffusion, a novel AI training-free technique to accommodate dense captions and provide layout manipulation in text-to-image synthesis.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.