Meet Dolma: An Open English Corpus of 3T Tokens for Language Model Pretraining Research
Large Language Models (LLMs) are a recent trend as these models have gained significant importance for handling tasks related to Natural Language Processing (NLP), such as question-answering, text summarization, few-shot learning, etc. But the most powerful language models are released by keeping the important aspects of the model development under wraps. This lack of openness reaches the pretraining data composition of language models, even when the model is released for public use.
Understanding how the makeup of the pretraining corpus affects a model’s capabilities and limitations is complicated by this opacity. It also impedes scientific advancement and impacts the general people who use these models. A team of researchers have discussed transparency and openness in their recent study. In order to promote openness and facilitate studies on language model pretraining, the team has presented Dolma, a large English corpus with three trillion tokens.
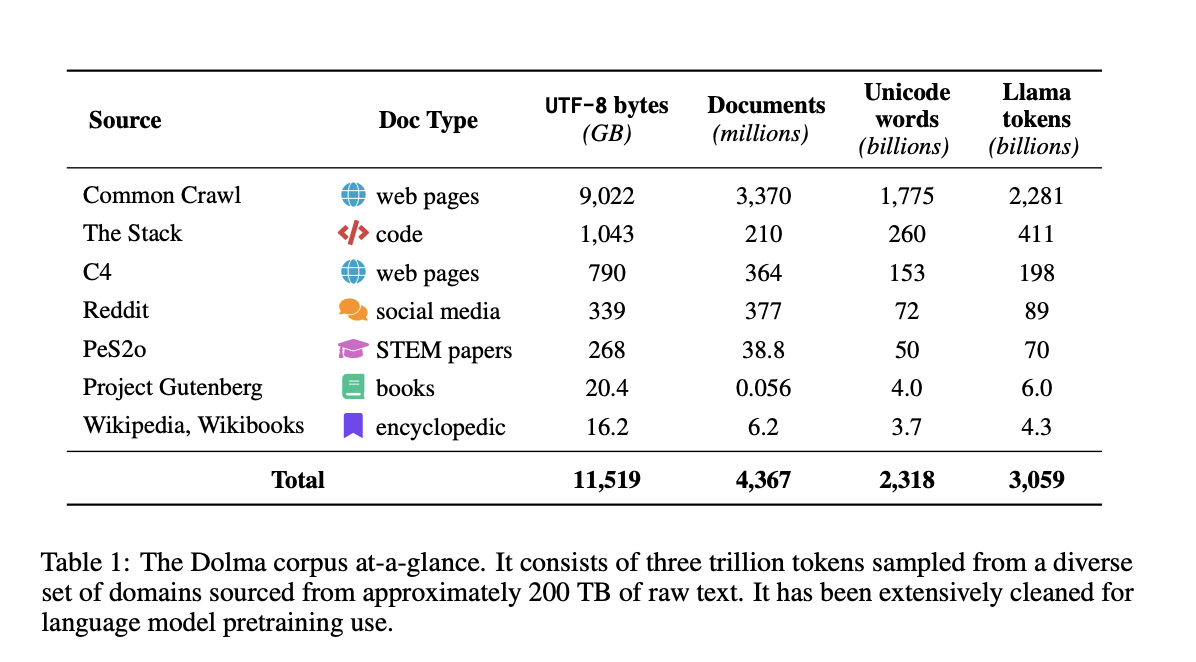
Dolma has been assembled from a wide range of sources, such as encyclopedias, scientific publications, code repositories, public-domain literature, and online information. In order to encourage additional experimentation and the replication of their findings, the team has made their data curation toolkit publicly available.
The team’s primary goal is to make language model research and development more accessible. They have highlighted multiple reasons to promote data transparency and openness, which are as follows.
- Language model application developers and users make better decisions by providing transparent pretraining data. The presence of documents in pretraining data has been associated with improved performance on related tasks, which makes it important to be mindful of social biases in pretraining data.
- Research examining how data composition affects model behavior requires access to open pretraining data. This makes it possible for the modeling community to examine and improve upon the state-of-the-art data curation techniques, addressing issues like training data attribution, adversarial assaults, deduplication, memorization, and contamination from benchmarks.
- The effective creation of open language models depends on data access. The availability of a wide range of large-scale pretraining data is a crucial enabler for the potential functionality that more recent models may offer, such as the ability to attribute generations to pretraining data.
The team has shared a thorough record of Dolma, including a description of its contents, construction details, and architectural principles. They have incorporated analysis and experimental results from training language models at several intermediate levels of Dolma into the research paper. These insights have clarified important data curation techniques, like the effects of content or quality filters, deduplication techniques, and the advantages of using a multi-source mixture in the training data.
OLMo, a state-of-the-art open language model and framework, has been trained using Dolma. OLMo has been developed to advance the field of language modeling by demonstrating the usefulness and importance of the Dolma corpus. The team has summarized their primary contributions as follows.
- The Dolma Corpus, which consists of a multifaceted set of three trillion tokens from seven distinct sources and is frequently utilized for extensive language model pretraining, has been publicly released.
- A high-performing, portable tool called Open Sourcing Dolma Toolkit has been introduced to help with the effective curation of big datasets for language model pretraining. With the help of this toolkit, practitioners can create their own data curation pipelines and duplicate the curation effort.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.