Meet DreamTeacher: A Self-Supervised Feature Representation Learning AI Framework that Utilizes Generative Networks for Pre-Training Downstream Image Backbones
Self-supervised representation learning is a successful method for developing the foundational skills of vision. This line of research is based on the idea that using big unlabeled datasets as supplementary sources of training data would improve downstream network performance and lessen the requirement for large labeled target datasets. Recent studies have demonstrated that self-supervised pre-training on ImageNet may now match or surpass supervised pre-training on several downstream datasets and tasks, including pixel-wise semantic and instance segmentation.
Variants of contrastive learning, where the target backbone is trained to map modified views of an image closer in latent space than pictures randomly selected from the dataset, are among the most popular methods for self-supervised representation learning. This paradigm may be improved by adding spatial losses and strengthening training stability with fewer or no negative instances. Another area of research focuses on reconstruction losses for supervision, or Masked picture Modelling (MIM), which involves masking certain regions from an input picture and training backbones to rebuild those parts. This work is usually considered deterministic, which means it oversees a single theory for the hidden region.
Typically, this work area looks at architectural design, training recipes, and masking tactics to train better backbones. When used with Vision Transformer-based backbones, these techniques have attained state-of-the-art (SoTA) performance; however, sparse CNN-based image backbones have recently been demonstrated to be just as effective. In this study, the authors make a case for generative models as representation learners, citing the simplicity of the goal—to produce data—and intuitive representational power—producing high-quality samples as a sign of learning semantically adequate internal representations.
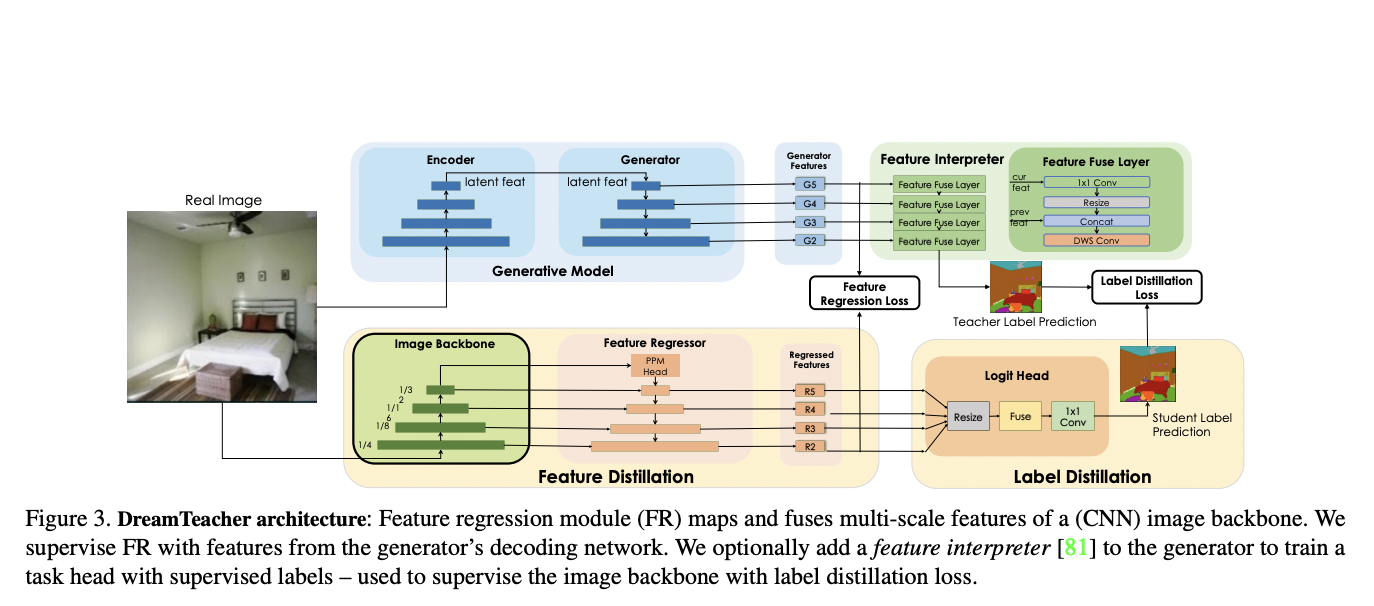
It is a familiar idea to use generative networks as representation learners. StyleGAN or a diffusion model’s features were suggested to be supplemented with task-dependent heads in DatasetGAN and its derivatives, which then employed these enhanced networks as sources of labelled data to train subsequent networks. By encoding pictures into the latent space of the generative model and using the task head for creating perceptual output, SemanticGAN instead employed StyleGAN with an extra task decoder as the task network itself. Researchers from NVIDIA, University of Toronto, Vector Institute, MIT in this study introduce DreamTeacher, a framework for representation learning that uses generative models to pre-train distillation-based downstream perception models.
They look into two different distillation processes: 1) As a universal pre-training procedure without labels, they provide techniques for feature distillation, which involves reducing generating features to target backbones. 2) Label distillation: In a semi-supervised environment, knowledge from a labelled dataset is distilled onto target backbones using task heads on top of generative networks. Diffusion models and GANs are the generative models of choice in their work.
They concentrate on CNNs for target backbones for two main reasons. 1) It has been demonstrated that CNN-based backbones can conduct SoTA representation learning for contrastive and MIM techniques, and 2) SoTA generative models (such as GANs and diffusion models) still heavily rely on CNNs. They also investigated the backbones of vision transformers in early trials but found it difficult to extract features from CNN-based generative models into vision transformers. Because generative models created using vision transformer architectures are still in their infancy, further research on DreamTeacher using these designs is still needed.
They empirically demonstrate that DreamTeacher outperforms the currently available self-supervised learning systems on numerous benchmarks and conditions. On several dense prediction benchmarks and tasks, including semantic segmentation on ADE20K, instance segmentation on MSCOCO, and the autonomous driving dataset BDD100K, their method significantly outperforms methods that are pre-trained on ImageNet with full supervision when pre-trained on ImageNet without any labels. When trained only on the target domain, their technique significantly outperforms variations pre-trained on ImageNet with label supervision. It reaches new SoTA performances on object-focused datasets with millions of unlabeled pictures. These findings demonstrate the potency of generative models, particularly diffusion-based generative models, as representation learners that efficiently exploit a wide range of unlabeled information.
Check out the Paper and Project Page. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.