Meet Embroid: An AI Method for Stitching Together an LLM with Embedding Information from Multiple Smaller Models Allowing to Automatically Correct LLM Predictions without Supervision
Imagine you programmed a language model (LM) to perform basic data analysis on the drug and medical histories. You would require labeled data for training your machine-learning model, including data from various patient histories. Building a large labeled dataset is quite difficult. It would require manual labeling with domain experts, which is cost-prohibitive. How would you deal with these models?
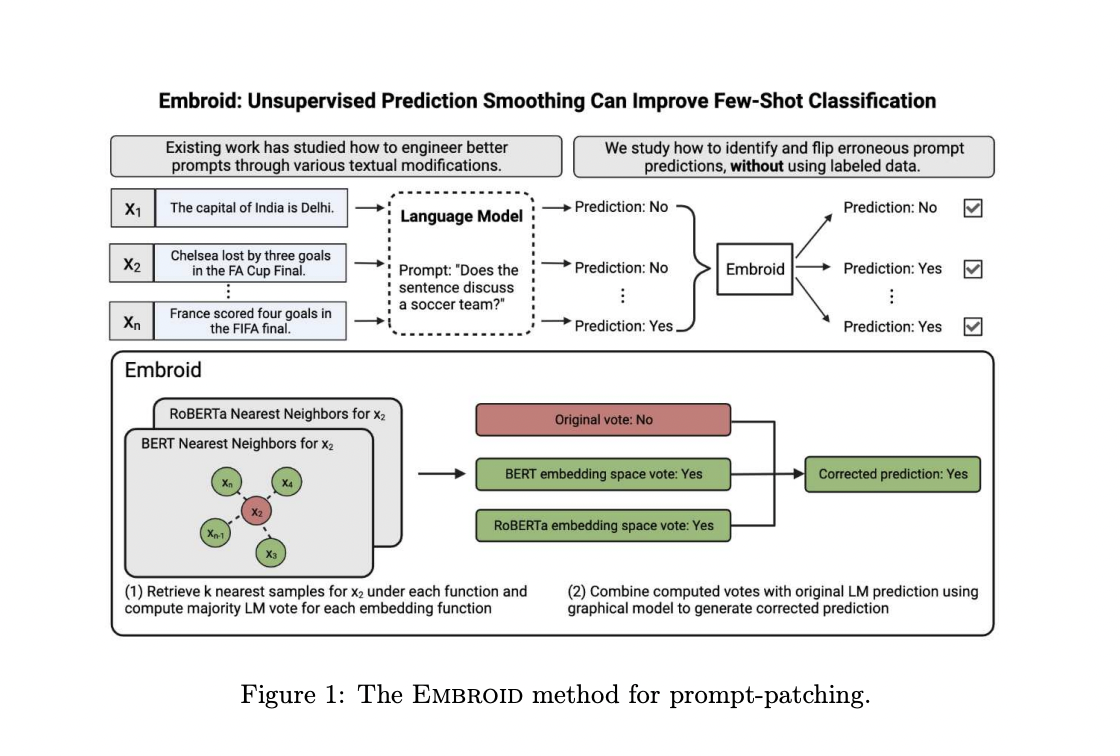
Researchers at Stanford University, Anthropic, and the University of Wisconsin-Madison tackle it by designing language models to learn the annotation tasks in context and replace manual labeling at scale. LMs in-context capabilities enable the model to remember tasks from the description of the prompts. They try to modify the prediction of a prompt rather than the prompt itself because language models are sensitive to even small changes in a prompt language and can produce erroneous predictions.
The researcher’s approach is based on the intuition that accurate predictions should also be consistent. Similar samples under some feature representations would receive the same prompt prediction. They propose a method called “Embroid,” which computes multiple representations of a dataset under different embedding functions and uses the consistency between the LM predictions to identify mispredictions. Using these neighborhoods, Embroid then creates additional predictions for each sample. These are further combined with a simple variable graphical model to determine the final corrected prediction.
One trivial question that can be asked is how the Embroid’s performance improvement will change with the change in the dataset size. Researchers say that the Embroid relies on the nearest neighbors in different embedding spaces, so they might expect the performance to be poor when the annotated dataset is small. Researchers also compared the variation in the performance when the domain specificity of the embedding changed, and the quality of the embedding space changed. They find that in both cases, it outperforms the usual Language models.
Researchers say that Embroid also uses statistical techniques developed with weak supervision. Its objective in weak supervision is to generate probabilistic labels for unlabeled data by combining the predictions of multiple noises. They say that it uses embeddings to construct additional synthetic predictions, which will be combined with the original predictions.
Researchers compare Embroid with six other LMs for up to 95 different tasks. For each LM, they selected three combinations of in-context demonstrations, generated predictions for each prompt, and applied Embroid independently to each prompt’s prediction. They found that this improved the performance over the original prompt by an average of 7.3 points per task on the GPT-JT and 4.9 points per task on GPT-3.5.
Check out the Paper and Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.