Meet Flan-UL2: A Unified Framework For Pre-Training Models That Are Universally Effective Across Datasets And Setups (Now Open-Source)
In Natural Langauge Processing (NLP), there has been tremendous progress in the development of large language models (LLMs). The primary objective of these models is to perform well based on the natural language textual descriptions that are fed as input to them. Their potential is estimated by how well they generalize to unseen tasks. Large Language Models like T5 and BERT have been evolving and improving continuously with a number of their variants.
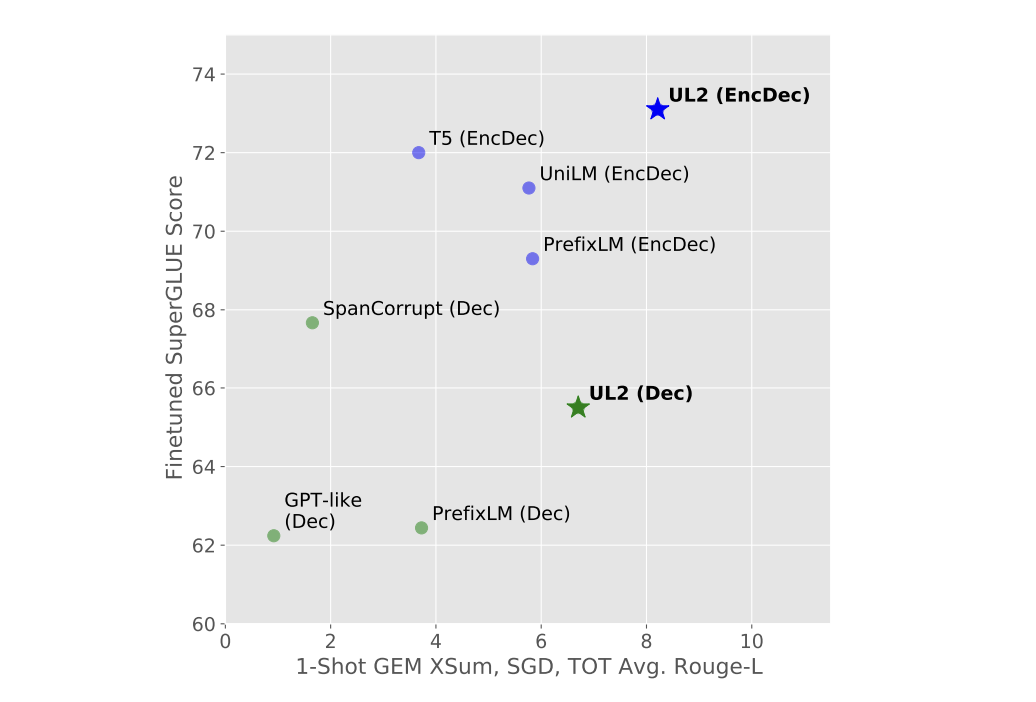
Just like FLAN-T5, the variant of the T5 model, which was appreciated because of its performance, now comes with another model called Flan-UL2. ULT, which stands for Unifying Language Learning Paradigms, was proposed, which develops a pre-training paradigm capable of operating across multiple datasets and setups. Developed by Google, this new framework for the pre-training models used a pre-training objective called Mixture-of-Denoisers (MoD) which blends the functionalities of diverse pre-training paradigms.
Like UL2, which has already been open-sourced, FLAN-UL2 is a new open-source model available on Hugging Face. Released on Apache license, this model is similar to Flan-T5 and the traditional UL2 models but improves the usability of the original UL2 model. The Flan-UL2 model has been trained on top of the existing UL2 20B checkpoint.
Two noteworthy improvements have been made to the UL2 20B model with Flan. Firstly, the original UL2 model had a limited receptive field of 512, making it unsuitable for N-shot prompting, specifically for larger N. With the updated Flan-UL2 checkpoint, the receptive field has been increased to 2048, allowing more efficient few-shot in-context learning. Secondly, the original UL2 model had mode switch tokens which, although they helped achieve good performance, were also difficult to carry. To overcome that, the researchers have trained the UL2 20B model for an additional 100k steps with a smaller batch size to eliminate the reliance on mode tokens. This has resulted in the new Flan-UL2 checkpoint, which no longer requires mode tokens during inference or finetuning.
Compared with other models in the Flan series, Flan-UL2 20B showed improvements and better performance than Flan-T5-XXL. Flan-UL2 20B outperforms Flan-T5 XXL on all four setups, with a performance lift of +3.2% relative improvement. Most of these gains were seen in the CoT setup, while the performance in direct prompting scenarios such as MMLU and BBH showed modest improvement at best. The performance of Flan-UL2 20B is also comparable to FLAN-PaLM 62B, achieving a score of 49.1 compared to 49.9 for FLAN-PaLM 62B.
Some of the key features of this model include – completely open source, the best OS model on MMLU/Big-Bench-Hard, Apache license, better performance than Flan-T5 XXL, and being competitive to Flan-PaLM 62B.
This new model is definitely a big addition to the already established large language models. With the ability to reason for itself and generalize better than the previous models, Flan-UL2 is a great improvement. It can also be run using the transformers or Inference Endpoints from Hugging Face. It is a notable achievement, especially considering that Flan-UL2 20B is approximately 7-8 times faster than FLAN-PaLM 62B, making it a more efficient option for real-world applications.
Check out the Paper, Github and HuggingFace Implementation. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.