Meet GPT-4V-Act: A Multimodal AI Assistant that Harmoniously Combines GPT-4V(ision) with a Web Browser
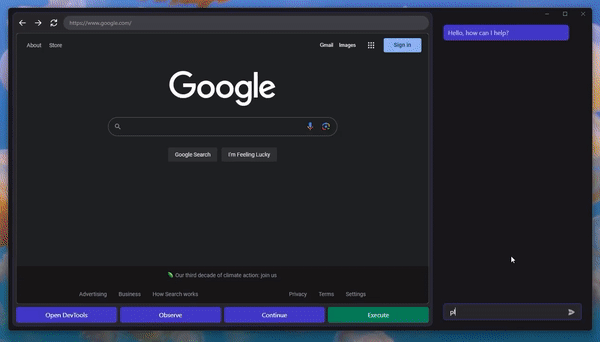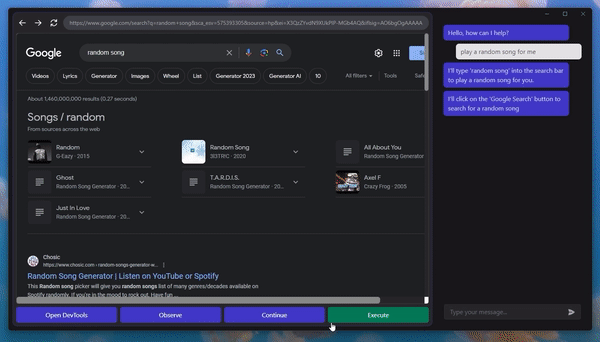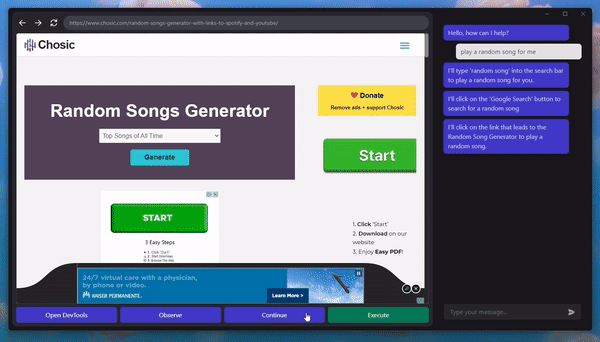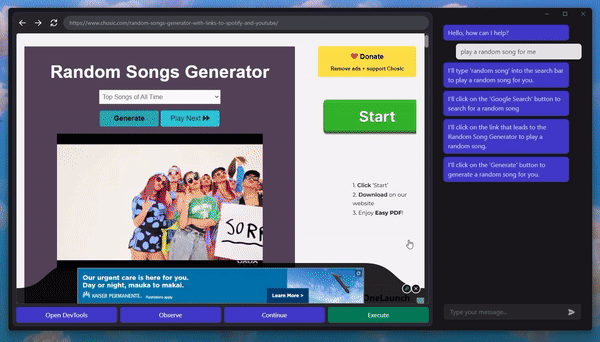
A Machine Learning researcher shared the release of their latest project, GPT-4V-Act, with the Reddit community recently. This idea was sparked by a recent discussion of the visual grounding strategy known as Set-of-Mark in GPT-4V. Intriguingly, tests demonstrated that GPT-4V with this capability could analyze a user interface screenshot and offer the exact pixel coordinates needed for guiding a mouse and keyboard to complete a certain task.
So far, the agent has shown capable of making posts on Reddit, conducting product searches, and starting the checkout process despite only being subjected to limited testing. Interestingly, it also recognized auto-labeler flaws when trying to play a game and sought to correct the activity.
Using GPT-4V(ision) and a web browser in perfect harmony, GPT-4V-Act is an articulate multimodal AI helper. It simulates human control down to low-level mouse and keyboard input and output. The goal is to provide an easy flow of work between humans and computers, leading to the development of technologies that greatly improve the usability of any UI, facilitate the automation of workflows, and make the use of automated UI testing possible.
How it Functions
By combining GPT-4V(ision) and Set-of-Mark Prompting with an individual auto-labeler, we achieve GPT-4V-Act. Each user interface element that can be interacted with is given its numeric ID by this auto-labeler.
GPT-4V-Act can infer the necessary steps for completing a task from a task and a screenshot. The number labels can be used as pointers to precise pixel coordinates when input by a mouse or keyboard.
Crucial note
Since GPT-4V(ision) has not been released to the general public, a current ChatGPT Plus subscription is required for multimodal prompting on this project. It should be noted that this project’s use of an unapproved GPT-4V API may violate the corresponding ChatGPT Term of Service condition.
The use of language models (LMs) that include capabilities like function calls is on the rise. These run mostly on APIs and textual representations of states. Agents with a user interface (UI) may be more useful in general situations where these are impractical. Since the agent’s interaction with the computer is analogous to a human’s, training can be done through expert demonstrations without requiring extensive specialized knowledge.
Check out the Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.