Meet GPT-NeoX-20B, A 20-Billion Parameter Natural Language Processing AI Model Open-Sourced by EleutherAI
This research summary is based on the paper 'GPT-NeoX-20B: An Open-Source Autoregressive Language Model' Please don't forget to join our ML Subreddit
In the latest AI research breakthrough, researchers from EleutherAI open-sourced GPT-NeoX-20B, a 20-billion parameter natural language processing AI model similar to GPT-3. The model was trained on nearly 825GB of publicly available text data and performed comparably to GPT-3 models of similar size. It’s the world’s largest dense autoregressive model with publicly accessible weights. GPT-NeoX-20B obtained an accuracy similar to a linear interpolation between OpenAI’s Curie and DaVinci models when tested on various typical NLP benchmark tasks and its one-shot performance on the MATH test dataset outperformed GPT-3 175B. GPT-NeoX-20B, according to EleutherAI, is the world’s largest open-source pre-trained autoregressive language model.
OpenAI announced the GPT-3 model with 175B parameters in 2020 but did not provide the trained model files. Instead, OpenAI offered an API that allows developers to use web service calls to integrate the model into their programs. Megatron-11B, Pangu-13B, Meta’s Fairseq 13B, and EleutherAI’s early models, GPT-Neo and GPT-J-6b are among the larger models that have been open-sourced since then.
There are even larger models with hundreds of billions or even trillions of parameters in addition to these open-source models. However, EleutherAI claims that these are “almost universally” either API-gated or not publicly available. EleutherAI’s motivation for publishing their models is based on their opinion that open access to such models is essential for furthering study in the field, given their vast scale.
GPT-NeoX-20B has a similar architecture to GPT-3, with some crucial modifications. The GPT-NeoX-20B encodes token location using rotating positional embeddings rather than learned embeddings. Second, the GPT-NeoX-20B computes the attention and feed-forward layers in parallel rather than serially, resulting in a 15% boost in throughput. Finally, GPT-NeoX-20B uses solely dense layers, whereas GPT-3 alternates sparse and dense layers.
EleutherAI’s software (also known as GPT-NeoX) was used to train GPT-NeoX-20B, built on Megatron and DeepSpeed and implemented in PyTorch. The team used model parallelism and data parallelism during training because the model was too huge to fit on a single GPU. Furthermore, because the team’s compute budget limits made hyperparameter search “intractable,” they elected to re-use the GPT-3 paper’s hyperparameters.
Model Design and Implementation

Software Libraries
GPT-NeoX is a custom codebase that is used to train the model. GPT-NeoX draws on Megatron and DeepSpeed to make huge language models with tens of billions of efficient and straightforward parameters to train. The PyTorch v1.10.0 release binary package, compiled with CUDA 11.1, is used. For distributed communications, this package is included with NCCL 2.10.3.
Hardware
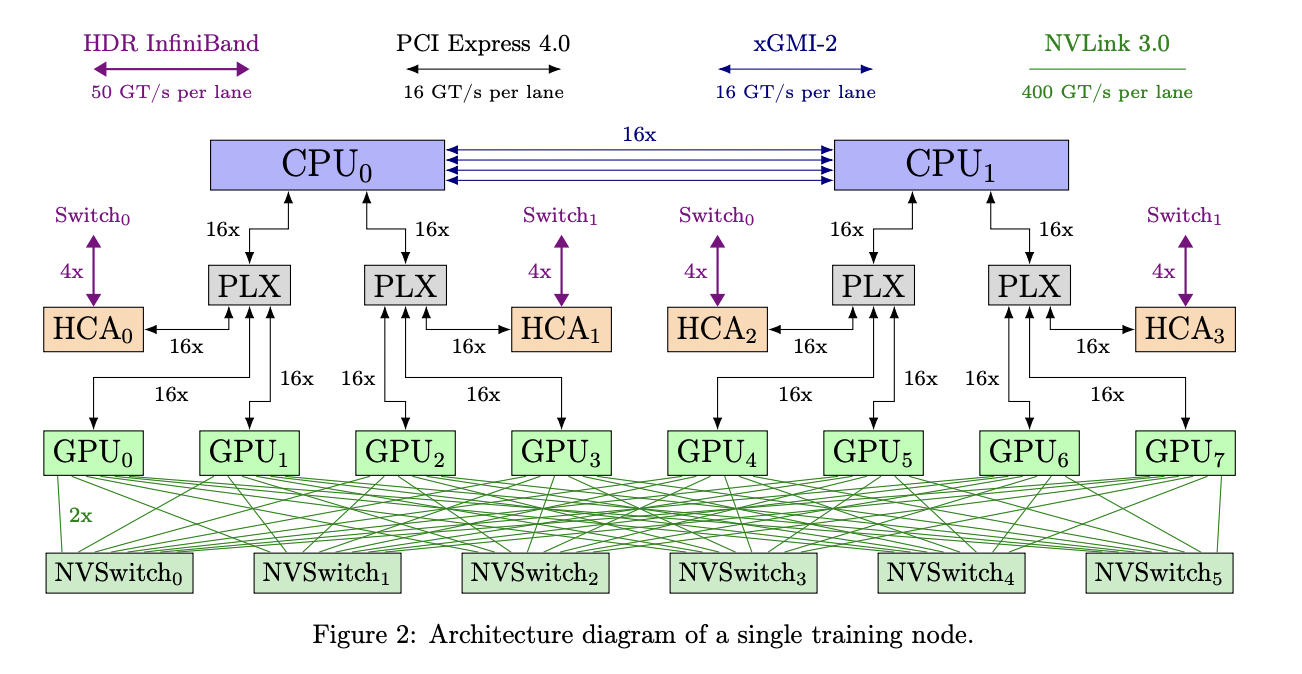
GPT-NeoX-20B was trained on twelve Supermicro AS-4124GO-NART servers, each equipped with eight NVIDIA A100-SXM4-40GB GPUs and two AMD EPYC 7532 CPUs. All GPUs can directly access the InfiniBand switched fabric through one of four ConnectX-6 HCAs for GPUDirect RDMA. The spine of this InfiniBand network is made up of two NVIDIA MQM8700-HS2R switches connected by 16 links, with one connection per node CPU socket connected to each switch. Figure 2 depicts a simplified image of a node that has been set up for training.

Environmental Impact
The energy consumption and carbon emissions involved with training big language models have been a significant source of concern in recent research. Strubell et al. [2019] estimate that a manuscript published by the authors at the time released 626,155 lbs or 284.01 metric tons14 of CO2 (tCO2 ). With the help of CoreWeave, energy usage and carbon emissions were measured during the creation and training of the model. It was discovered that the process of generating and training GPT-NeoX-20B emitted almost precisely 10% of the CO2 estimated by Strubell et al. [2019], totaling 69957 lbs or 31.73 metric tonnes. This is nearly the same as the average American’s annual emissions or 35 round-trip flights between New York and San Francisco.

A power of 43.92MWh was used throughout 1830 hours of training, and this mixture creates an average of 0.47905 tCO2 /MWh. Scaling, testing, and assessment consumed an additional 920 hours on our systems, resulting in total energy usage of 66.24MWh and the emission of just under 35 metric tonnes of CO2.
Conclusion
GPT-NeoX-20B was tested on a “wide range” of NLP benchmarks, including LAMBADA and WinoGrande, the HendrycksTest knowledge benchmark, and the MATH dataset. They compared its performance to their prior GPT-J-6B model, Meta’s FairSeq 13B, and various GPT-3 sizes. The researchers claim that GPT-performance NeoX-20B’s on NLP tasks “might be enhanced,” but it “excels” on science and maths tests.
Paper: http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf
Github: https://github.com/EleutherAI/gpt-neox
Reference:
- https://blog.eleuther.ai/announcing-20b/
- https://www.infoq.com/news/2022/04/eleutherai-gpt-neox/
Suggested
Credit: Source link
Comments are closed.