Meet HyDE: An Effective Fully Zero-Shot Dense Retrieval Systems That Require No Relevance Supervision, Works Out-of-Box, And Generalize Across Tasks
Dense retrieval, a technique for finding documents based on similarities in semantic embedding, has been shown effective for tasks including fact-checking, question-answering, and online search. Many methods, including distillation, negative mining, and task-specific pre-training, have been suggested to increase the efficiency of supervised dense retrieval models. However, zero-shot dense retrieval is still challenging. The alternative transfer learning paradigm, where the dense retrievers are trained on a high-resource dataset and then assessed on queries from new jobs, has been considered in several recent publications. Undoubtedly the most popular is the MSMARCO collection, a sizable judged dataset with numerous thought query document pairings.
Izacard contends that although it is sometimes possible to presume the existence of a huge dataset, this is only sometimes the case. Even MS-MARCO has limitations on the commercial application and cannot be used in a range of actual search circumstances. In this study, they develop efficient, completely zero-shot dense retrieval systems that operate automatically, generalize across tasks, and don’t need any relevance monitoring. As no supervision is available, they first look at self-supervised representation learning techniques. Two different learning algorithms are possible with modern deep learning. Strong natural language interpretation and generating skills have been shown by generative big language models at the token level after being pretrained on huge corpora.
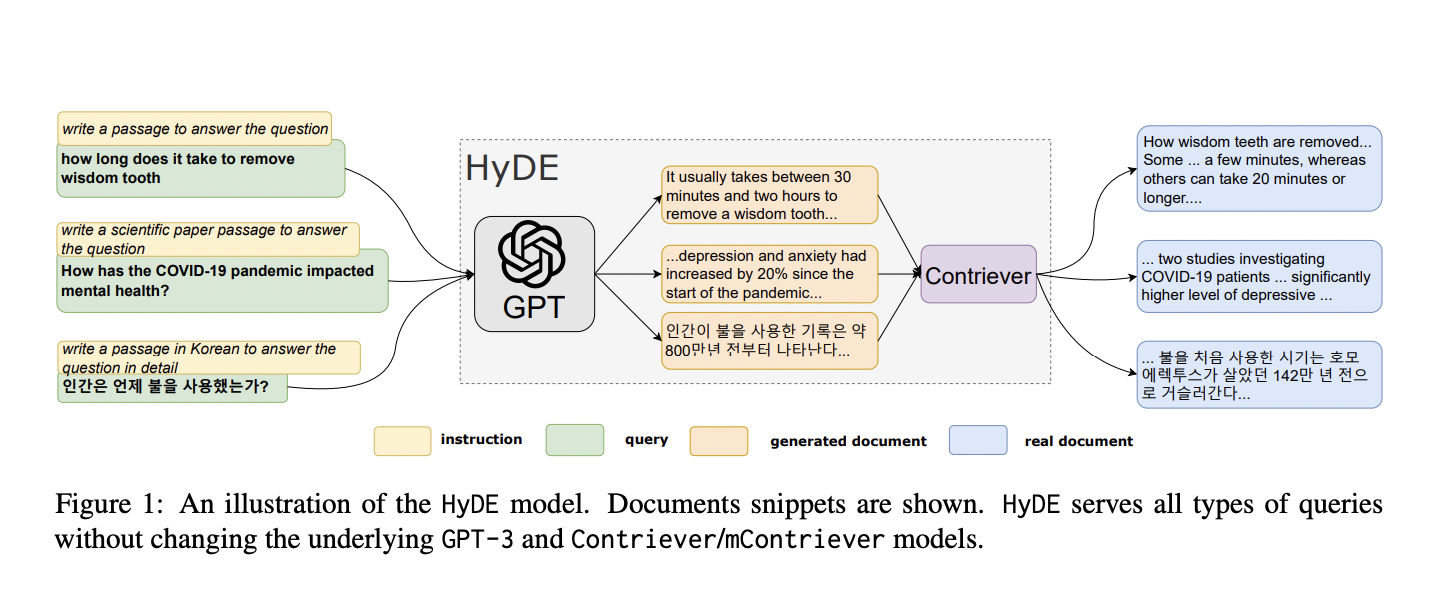
Ouyang demonstrates how GPT-3 models may be adjusted to match human intent to follow instructions with only a tiny quantity of data. Text encoders pre-trained with contrastive aims at the document level are taught to encode document-document similarity into inner-product. In addition, a further insight into LLM is borrowed: LLMs that have been given more training in following directions may zero-shot generalize to other unknown instructions. With these components, they suggest turning to Hypothetical Document Embeddings and splitting up dense retrieval into two tasks: a generative job carried out by an instruction-following language model and a document-to-document similarity task carried out by a contrastive encoder.
The generative model is first fed the question, and they tell it to “create a document that answers the question,” i.e., a fictitious document. By providing an example, they anticipate the generative process to capture “relevance”; the created document is not authentic and may have factual inaccuracies, but it resembles a relevant text. The second stage encodes this material into an embedding vector using an unsupervised contrastive encoder. The lossy compressor, where the additional features are filtered out of the embedding, is what they anticipate the encoder’s dense bottleneck to serve in this case. To search against the corpus embeddings, they employ this vector. The authentic papers that are the most comparable are found and delivered.
Document-document similarity contained in the inner product during contrastive training is used in the retrieval. Interesting to note is that the query-document similarity score is no longer explicitly modeled or generated with HyDE factorization. Instead, two NLU and NLG tasks are split from the retrieval job. HyDE seems to be unsupervised. HyDE does not train any models; rather, it preserves the generative and contrastive encoder.
The only use of supervision signals was for their backbone LLM’s instruction learning. In their experiments, they demonstrate that HyDE significantly outperforms the previous state-of-the-art Contrieveronly zero-shot no-relevance system on 11 query sets, covering tasks like web search, question answering, fact-checking, and languages like Swahili, Korean, and Japanese. HyDE uses InstructGPT and Contriever as their backbone models. Installing the module via pip will allow you to use it right away. It has substantial written documentation.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.