Meet In-N-Out: A Face Video Inversion and Editing Framework with Volumetric Decomposition
Video editing is an essential artificial intelligence (AI) process critical to creating visual content. Video editing involves manipulating, re-arranging, and enhancing video footage to produce a final product with desired characteristics. This process can be time-consuming and labor-intensive, but AI advancements have made editing videos easier and faster.
The use of AI in video editing has revolutionized the way we create and analyze video content. With the help of advanced algorithms and machine learning models, video editors and researchers can now achieve previously unattainable results.
A popular AI technique for video editing relies on GAN inversion, which involves projecting a real image onto the latent space of a pre-trained GAN to obtain a latent code. This way, the input image can be reconstructed by feeding the latent code into the pre-trained GAN. By changing the latent code, one can achieve many creative semantic editing effects for images.
However, these approaches often lack either identity preservation or semantically-accurate reconstructions.
For instance, GAN inversion techniques like IDE-3D or PTI cannot deal with Out-of-Distributions (OOD) elements, which refer to uncommon data distributions like object occlusions in face frames. IDE-3D can produce faithful editing but fails to preserve the identity of the input face. PTI provides higher identity preservation, but semantic accuracy suffers.
To obtain both identity preservation and faithful reconstruction, a GAN-based video editing and inversion framework termed In-N-Out has been proposed.
In this work, the authors rely on composite volume rendering to generate multiple radiance fields during rendering.
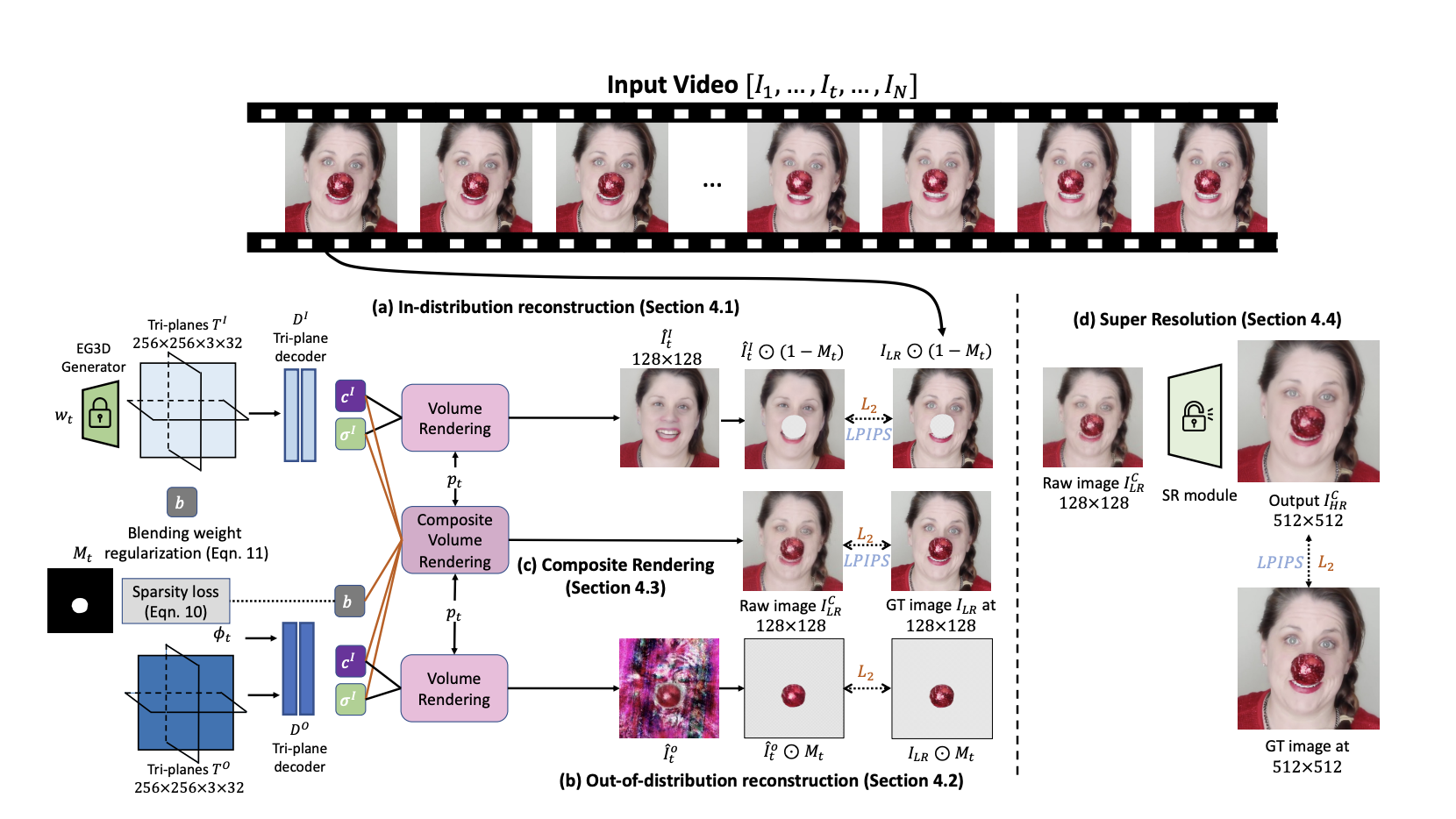
An overview of the architecture is available below.
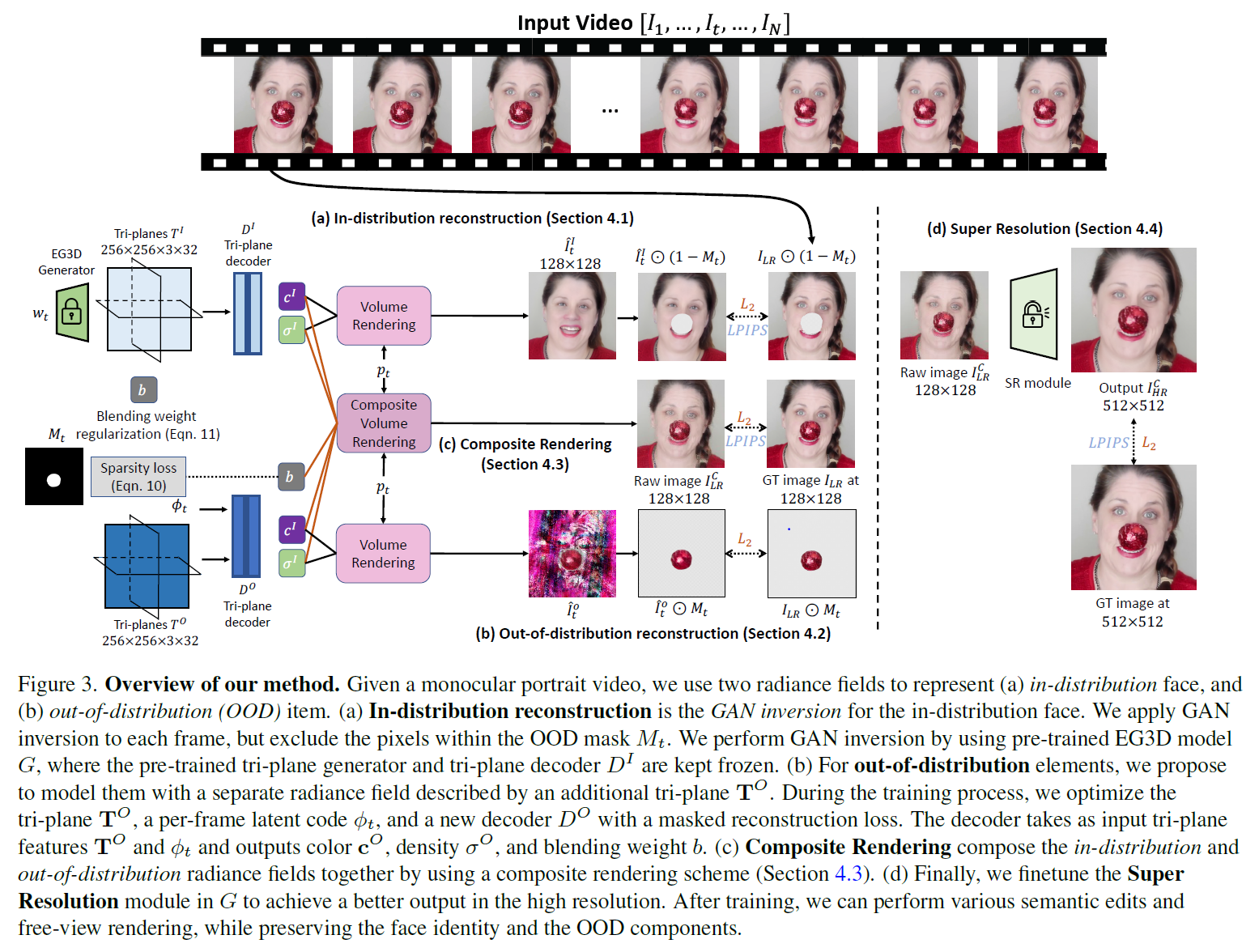
The core idea is to decompose the 3D representation of the video with the OOD object into an in-distribution part and an out-of-distribution part and compose them together to reconstruct the video in a composite volumetric rendering manner. In the two-dimensional case, it would be like sticking one image (representing an occlusion object, such as a ball) onto another (in this case, a face).
The authors exploit EG3D as the 3D-aware GAN backbone and leverage its tri-plane representation to model this composed rendering pipeline. For the in-distribution element (i.e., natural face), pixels are projected into EG3D’s latent space. For the out-of-distribution part, the authors use an additional tri-plane to represent it. Later, these two radiance fields are combined in a composite volumetric rendering to reconstruct the input. During the editing stage, the in-distribution part, i.e., the latent code, is independent of the OOD part and separately edited. Furthermore, the reconstructed pixels related to the masked OOD part are not considered in the process.
According to the authors, this proposed approach brings three main advantages. First, by composing in-distribution and out-distribution together, the model achieves a higher fidelity reconstruction. Second, by editing only the in-distribution part, editability is maintained. Third, by leveraging 3D-aware GANs, the input face video can be rendered from novel viewpoints.
A comparison of the mentioned method and other state-of-the-art approaches is reported below.

This was the summary of In-N-Out, a novel AI framework for face video inversion and editing with volumetric decomposition.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.