Meet InstantAvatar: An Artificial Intelligence (AI) System That Can Reconstruct Human Avatars From A Monocular Video In 60 Seconds
It is crucial to produce high-fidelity digital humans for numerous applications, including immersive telepresence, AR/VR, 3D graphics, and the developing metaverse. Getting customized avatars is a complicated process that frequently needs to be calibrated by multi-camera systems and costs a lot of processing power. The development of strong neural fields has enabled various techniques to recreate animated avatars from monocular footage of moving people. They develop a lightweight, broadly deployable, and quick enough plan for learning 3D virtual people from monocular video alone.
Particular techniques using neural radiance fields (NeRFs) as the fundamental model have produced very accurate avatar reconstruction outcomes. These techniques often represent human form and appearance in a canonical space independent of poses. Such methods must employ animation (such as skinning) and rendering algorithms to deform and render the model into posed space differently to rebuild the model from photos of individuals in various postures. By reducing the discrepancy between produced pixel values and actual pictures, this mapping between posed and canonical space enables the optimization of network weights.
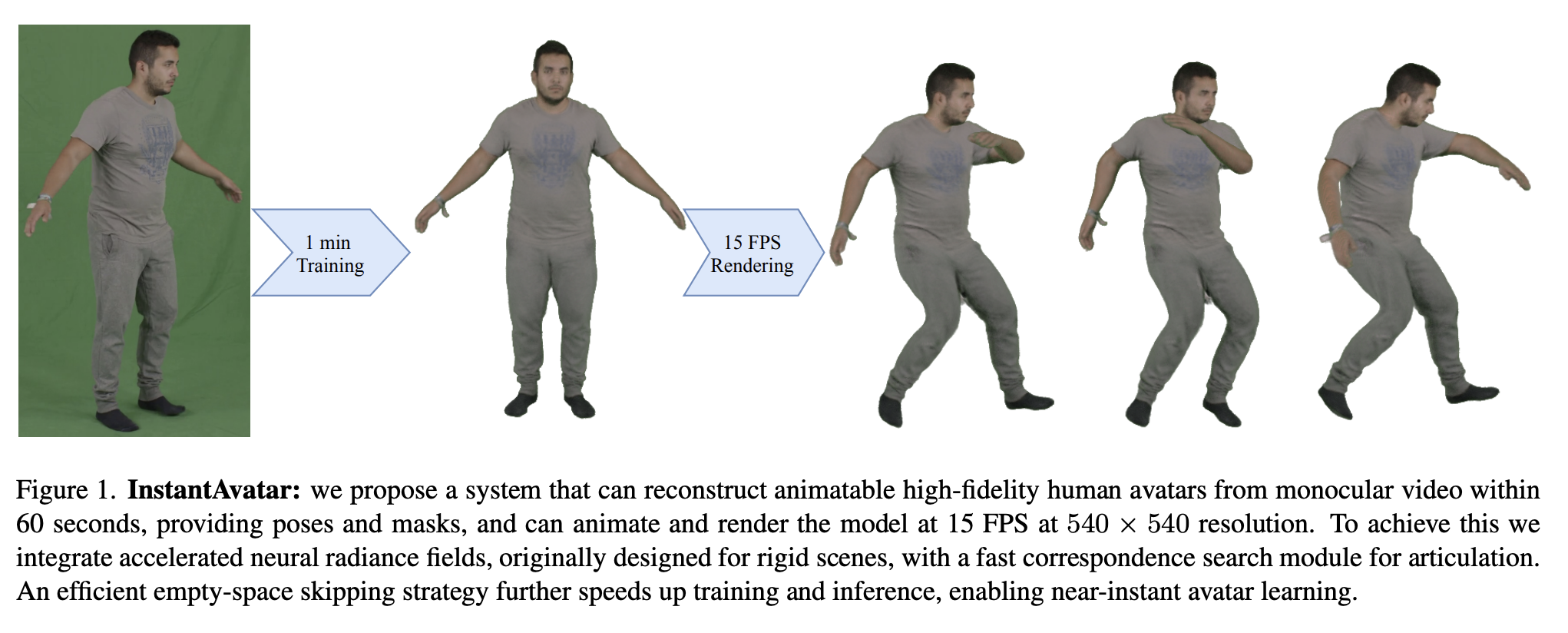
These models can’t be drawn at interactive rates and need hours of training time due to the combined requirement for differentiable deformation modules and for volume rendering, which prevents their wider deployment. With this research, they hope to make a substantial contribution toward the practical implementation of monocular neural avatar reconstruction by presenting a technique that requires no more time for reconstruction than it does for input video capture. To do this, they suggest InstantAvatar, a system that, given a monocular video, posture parameters, and masks, reconstructs high-fidelity avatars in 60 seconds instead of hours. The avatar may be animated and generated at interactive speeds after mastering it.
Achieving such a speedup is a difficult endeavor that calls for careful method design, quick differentiable rendering and articulation algorithms, and effective implementation. Their short yet incredibly effective pipeline includes several crucial elements. First, they use a recently suggested effective neural radiance field variation to learn the canonical form and appearance. By substituting a more effective hash table for multi-layer perceptrons (MLP) as the data structure, Instant-NGP speeds up the rendering of neural volume. However, Instant-NGP can only handle rigid objects since the spatial properties are explicitly specified.
Second, they connect the classical NeRF with an effective articulation module, Fast-SNARF, which effectively generates a continuous deformation field to distort the canonical radiance field into the posed space. This enables learning from posed observations and allows us to animate the avatar. Comparing Fast-SNARF to its considerably slower predecessor, the former is orders of magnitude quicker. Lastly, merely merging current acceleration techniques does not produce the needed efficiency. Once the short articulation module and acceleration mechanisms for the canonical space are in place, rendering the real volume becomes the computational bottleneck.
Standard volume rendering requires querying and accumulating densities of hundreds of locations along the ray to determine the color of a pixel. Keeping an occupancy grid to skip samples in the vacant space is a frequent way to speed up this process. Such a method, however, is predicated on stiff situations and cannot be used for dynamic settings, such as those including moving people. With established articulation patterns for dynamic scenarios, they suggest a space-skipping strategy. They sample points on a regular grid in the posed area for each input body pose at inference time and translate those samples back to the canonical model to query densities.
They keep an occupancy grid shared across all training frames for training, tracking the union of occupied areas across individual boundaries. Every few training rounds, this occupancy grid is updated with the densities of randomly sampled points in the posed space of randomly selected frames. While these densities are thresholded, a canonical space occupancy grid may pass over vacant space when drawing volumes. This plan strikes a compromise between rendering quality and computing efficiency. They test their approach using artificial and actual monocular movies of moving people, comparing it to cutting-edge techniques for monocular avatar reconstruction.
Compared to SoTA approaches, their approach achieves comparable reconstruction quality and superior animation quality while needing less than 10 minutes of training time. Their technique performs noticeably better than SoTA methods when given the same time budget. To show how the parts of their system affect speed and accuracy, they also provide an ablation study. The code will soon release on GitHub.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.