Meet InternLM-20B: An Open-Sourced 20B Parameter Pretrained Artificial Intelligence AI Framework
Researchers continually strive to build models that can understand, reason, and generate text like humans in the rapidly evolving field of natural language processing. These models must grapple with complex linguistic nuances, bridge language gaps, and adapt to diverse tasks. However, traditional language models with limited depth and training data have often exceeded these expectations. The research community has introduced InternLM-20B, a groundbreaking 20 billion parameter pretrained model to address these challenges.
InternLM-20B represents a significant leap forward in language model architecture and training data quality. Unlike its predecessors, which typically employ shallower architectures, this model opts for a profound 60-layer structure. The rationale behind this choice is simple: deeper architectures can enhance overall performance as model parameters increase.
What truly sets InternLM-20B apart is its meticulous approach to training data. The research team performed rigorous data cleansing and introduced knowledge-rich datasets during pretraining. This meticulous preparation significantly boosted the model’s capabilities, excelling in language understanding, reasoning, and knowledge retention. The result is an exceptional model that performs exceptionally well across various language-related tasks, heralding a new era in natural language processing.
InternLM-20B’s method effectively utilizes vast amounts of high-quality data during the pretraining phase. Its architecture, featuring a whopping 60 layers, accommodates an enormous number of parameters, enabling it to capture intricate patterns in text. This depth empowers the model to excel in language understanding, a crucial aspect of NLP.
What truly sets InternLM-20B apart is its training data. The research team meticulously curated this data, ensuring it was vast and exceptionally high quality. This included rigorous data cleansing and the inclusion of knowledge-rich datasets, which enabled the model to perform exceptionally well across multiple dimensions.
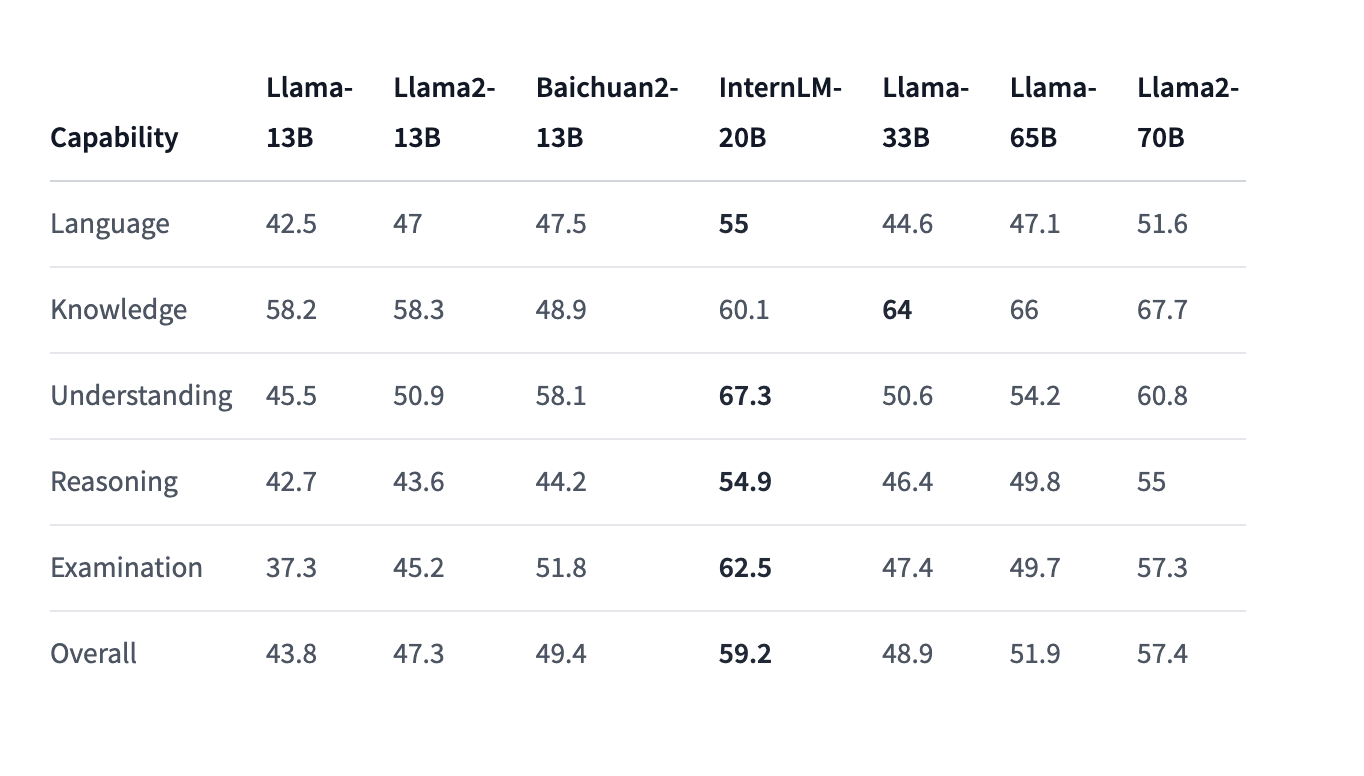
InternLM-20B shines in various evaluation benchmarks. Notably, it outperforms existing language understanding, reasoning, and knowledge retention models. It supports an impressive 16k context length, a substantial advantage in tasks requiring a more extensive textual context. This makes it a versatile tool for various NLP applications, from chatbots to language translation and document summarization.

In conclusion, the introduction of InternLM-20B represents a groundbreaking advancement in natural language processing. Researchers have effectively addressed the longstanding challenges of language model depth and data quality, resulting in a model that excels across multiple dimensions. With its impressive capabilities, InternLM-20B holds immense potential to revolutionize numerous NLP applications, marking a significant milestone in the journey towards more human-like language understanding and generation.
In a world where communication and text-based AI systems continue to play an increasingly vital role, InternLM-20B stands as a testament to the relentless pursuit of excellence in natural language processing.
Check out the Project and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.