Meet LEVER: A Simple AI Approach to Improve Language-to-Code Generation by Learning to Verify the Generated Programs with their Execution Results
Large language models (LLMs) have recently made significant strides. These models have uplifted the domain of Artificial Intelligence significantly and hold tremendous potential for completing various types of tasks. From imitating humans by answering questions and coming up with content to summarizing textual paragraphs and translating languages, LLMs can do everything. Virtual assistants, robotics control, database interfaces, and other AI applications all depend on the capacity to translate natural language descriptions into executable code. Though code LLMs, or basically the models that are pre-trained on code, have shown great performance in using in-context few-shot learning, the performance of these models may be enhanced, though, and optimizing them would be computationally expensive.
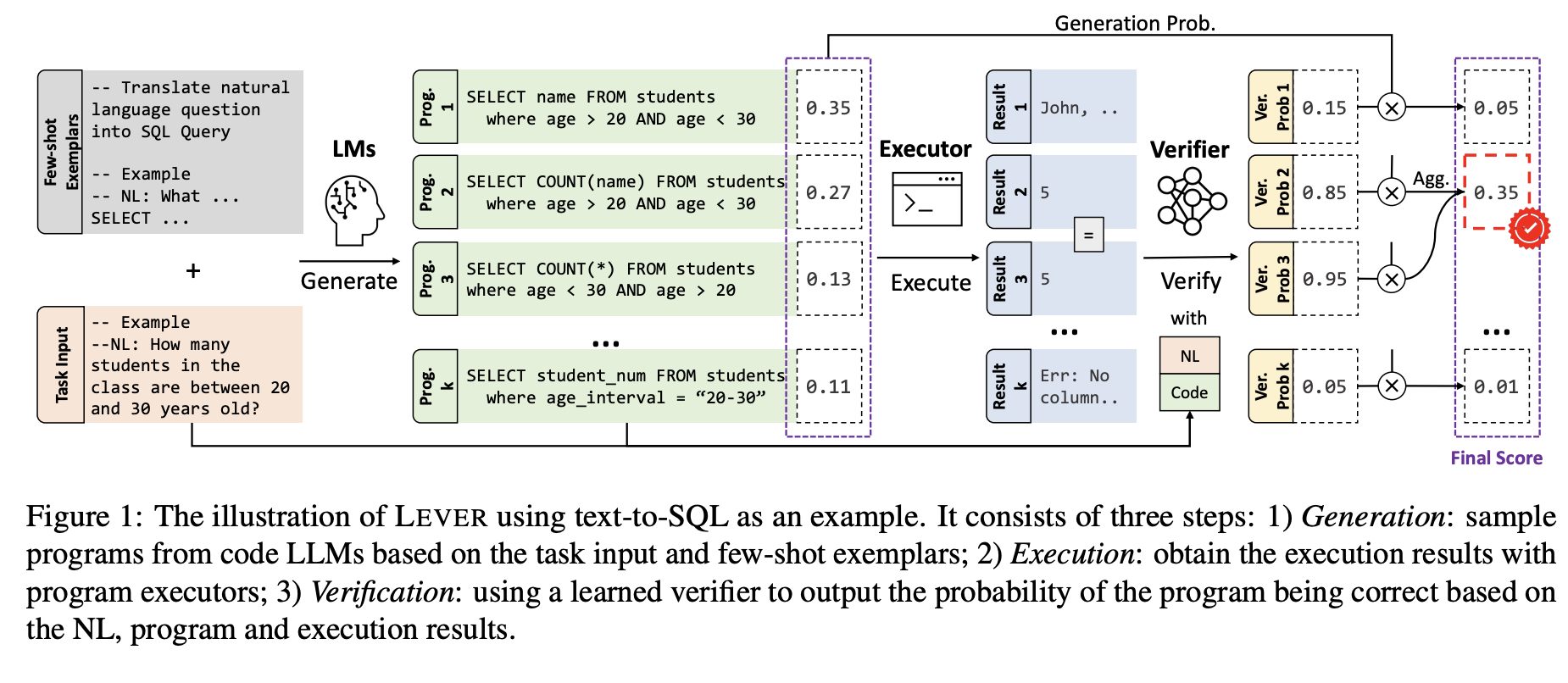
While LLMs may struggle with accuracy in situations with few shots, they frequently offer accurate results when given enough samples, i.e., when samples are drawn at scale, majority voting and filtering by test cases can greatly improve their performance. Data types, value ranges, and variable properties are potent indications of program correctness and are rich semantic elements of model solutions. In a recent study, a team of researchers introduced Learning to Verify (LEVER), an approach for language-to-code generation using code LLMs.
LEVER makes use of a combined representation of the natural language description, the program surface form, and the execution outcome for training the verifier to identify and reject faulty programs. The verification probability and LLM generation probability are combined in order to create an aggregate probability, and programs with identical execution results are marginalized. The programs with the best likelihood of providing the right outcome are chosen as the output using this probability as a reranking score.
LEVER has been proposed to improve language-to-code creation by including a learning-to-verify process and to judge whether a program sampled from the LLMs is accurate. LEVER seeks to improve the output’s precision and correctness by checking the created programs. For evaluation, experiments have been carried out on four datasets representing different domains, including table QA, math QA, and fundamental Python programming, to assess LEVER’s efficacy. The performance benefits utilizing code-davinci-002 ranged from 4.6% to 10.9%, and the results consistently outperformed the base code LLMs. Across all datasets, LEVER has attained brand-new state-of-the-art results, demonstrating its superiority in producing precise and contextually relevant code from natural language descriptions.
In conclusion, the LEVER technique improves code LLMs’ ability to translate natural language descriptions into executable code. This method outperforms more traditional execution error pruning strategies in terms of accuracy by utilizing a verifier that takes execution results into account. The findings demonstrate its efficiency in a range of language-to-code tasks and suggest that it has the potential to enhance a number of AI applications, including database interfaces, robotics control, and virtual assistants.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.