Meet LLaMA-Adapter: A Lightweight Adaption Method For Fine-Tuning Instruction-Following LLaMA Models Using 52K Data Provided By Stanford Alpaca
Large-scale corpora and cutting-edge hardware enable LLMs to generate models with extraordinary understanding and generative power, raising the bar for language problems. Recent developments in instruction-following models, such as ChatGPT1 and GPT-3.5, have achieved tremendous progress (text-davinci-003). They may produce professional and conversational responses when given commands or instructions in normal language. However, the closed-source limitation and expensive development costs significantly impede the spread of instruction-following models.
Stanford Alpaca researchers suggested modifying an LLM, or LLaMA, into an accessible and scalable instruction-following model. Alpaca uses GPT-3.5 to self-instruct and increase the training data to 52K from 175 human-written instruction-output pairs. This controls Alpaca to optimize all 7B parameters in LLaMA, resulting in a superb model that performs similarly to GPT-3.5. Despite Alpaca’s efficiency, large-scale LLaMA still requires extensive fine-tuning. This is time-consuming, computationally demanding, multi-modality incompatible, and difficult to adapt to other downstream scenarios.
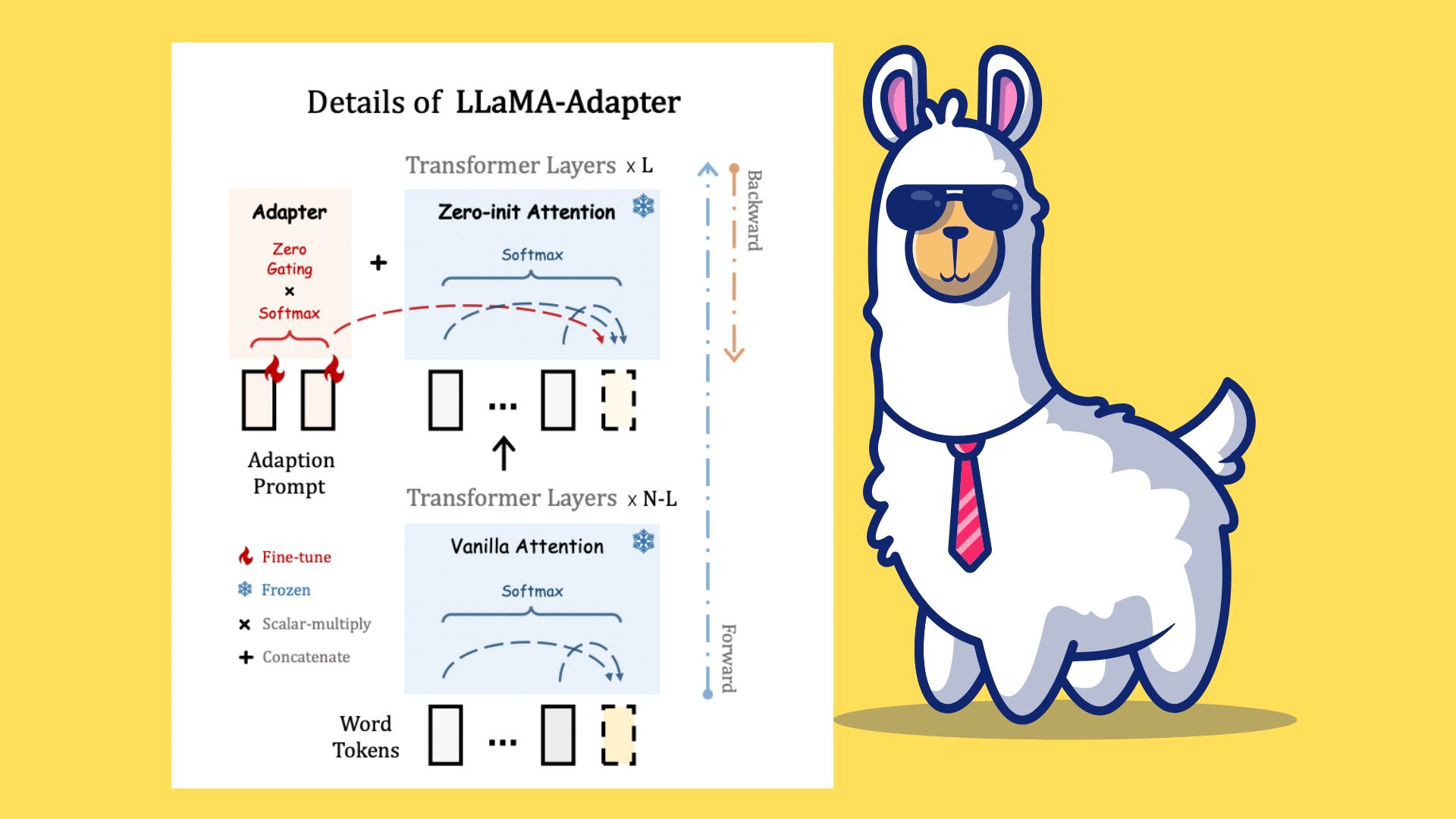
A group of researchers from the Shanghai Artificial Intelligence Laboratory, CUHK MMLab, and the University of California introduced the LLaMA-Adapter. This effective fine-tuning technique transforms LLaMA into a capable instruction-following model. In the higher transformer layers of LLaMA, the researchers prefix the input instruction tokens with a set of learnable adaptation prompts. These instructions are adaptively injected into LLaMA by these prompts.
The team changed the default attention mechanisms at inserted layers to zero-init attention with a trainable gating factor to eliminate noise from adaptation cues during the early training period. Initialized with zero vectors, the gating can maintain initial knowledge in LLaMA and gradually add training signals. This helps the final model better follow instructions and maintain learning stability as it is fine-tuned.
Overall, LLaMA-Adapter exhibits the following four characteristics:
- 1.2 million parameters: The pre-trained LLaMA is frozen and only learns the adaption prompts with 1.2M parameters on top instead of updating the entire set of 7B parameters. This, however, demonstrates comparable instruction after mastery of the 7B Alpaca.
- Fine-tuning for an hour. With eight A100 GPUs, the convergence of the LLaMA-Adapter takes less than an hour, which is three times quicker than Alpaca, thanks to the lightweight parameters and the zero-init gating.
- Plug with Knowledge. It is adaptable to install its appropriate adapters and gives LLaMA diverse expert knowledge for various conditions. Hence saving a 1.2M adapter within each context is sufficient.
- Multimodal State: LLaMA-Adapter can be expanded to accept image input and textual instruction for multimodal reasoning. LLaMA-Adapter achieves competitive performance on the ScienceQA benchmark by including image tokens in adaptation prompts.
The team plans to incorporate more varied multimodal inputs, such as audio and video, into LLaMA-Adapter. They will conduct additional research on larger LLaMA models (33B, 65B parameters) and various benchmarks.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.