Meet LLMScore: A New LLM-based Instruction-Following Matching Pipeline to Evaluate the Alignment Between Text Prompts and Synthesized Images in Text-to-Image Synthesis
Text-to-image synthesis research has advanced significantly in recent years. However, assessment measures have lagged due to difficulties adapting assessments with different purposes, effectively capturing composite text-image alignment (for example, color, counting, and position) and producing the score understandably. Despite being extensively used and successful, established assessment metrics for text-to-image synthesis like CLIPScore and BLIP have needed help capturing object-level alignment between text and picture.
The text prompt “A red book and a yellow vase” is shown in Figure 1 as an example from the Concept Conjunction dataset. The left vision aligns with the text query. At the same time, the right image fails to provide a red book, the correct color for the vase, and an additional yellow flower. While the existing metrics (CLIP, NegCLIP, BLIP) predict similar scores for both images, failing to distinguish the correct image (on the left) from the incorrect one (on the right), human judges can make the correct and clear assessment (1.00 v.s. 0.45/0.55) of these two images on both overall and error counting objectives.

Additionally, these measures offer a single, opaque score that hides the underlying logic behind how the synthesized pictures were aligned with the provided text prompts. Additionally, these model-based measures are rigid and cannot adhere to diverse standards prioritizing distinct text-to-image assessment objectives. For instance, the evaluation might access semantics at the level of an image (Overall) or more minute information at the level of an item (Error Counting). These problems prevent the current measurements from being in line with subjective assessments. In this study researchers from the University of California, the University of Washington and the University of California uncover the potent reasoning capabilities of large language models (LLMs), introducing LLMScore, a unique framework to evaluate text-image alignment in text-to-image synthesis.
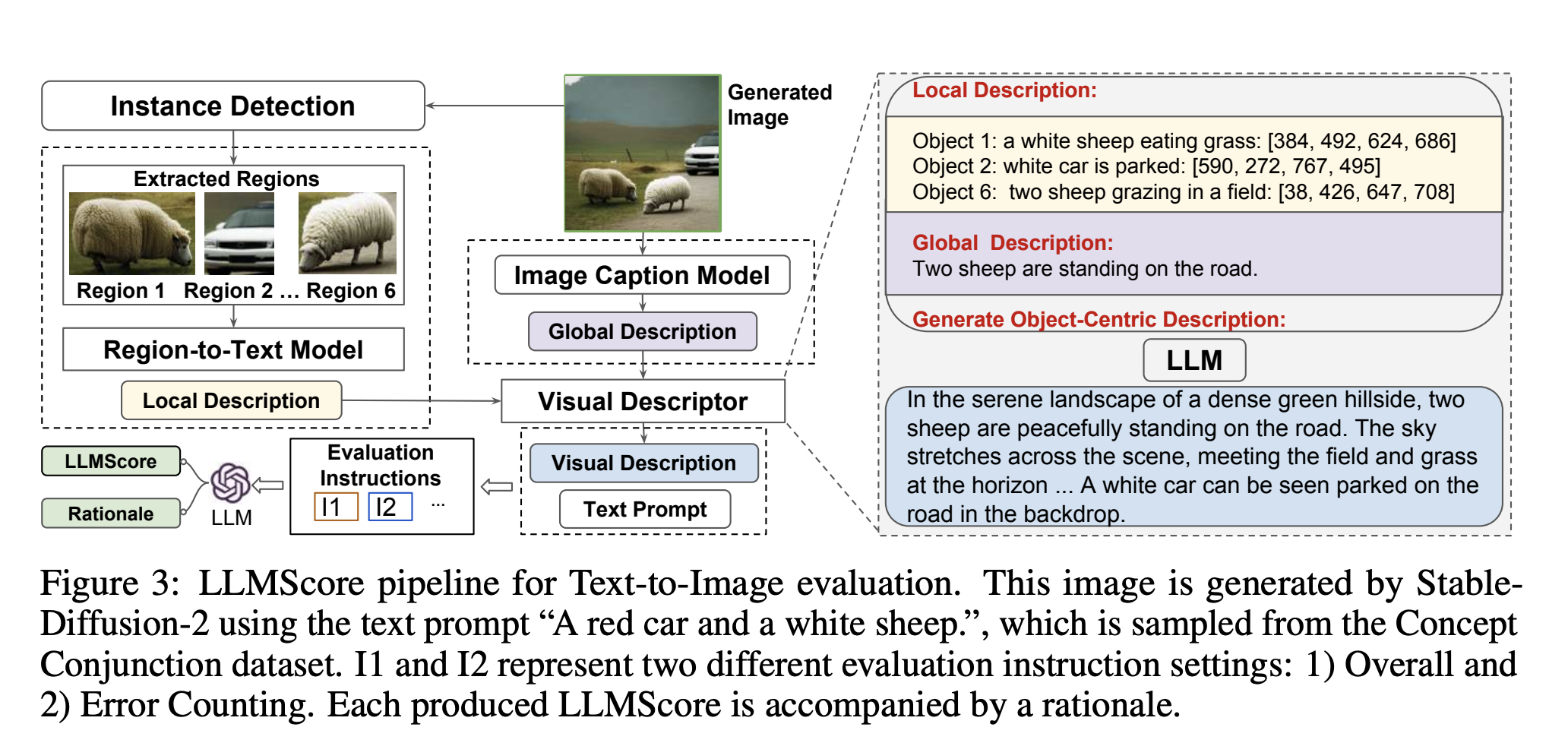
The human method of assessing text-image alignment, which entails verifying the accuracy of the items and characteristics mentioned in the text prompt, served as their model. LLMScore may mimic the human review by accessing compositionality at many granularities and producing alignment scores with justifications. This gives users a deeper understanding of the model’s performance and the motivations behind the results. Their LLMScore collects grounded Visio-linguistic information from vision and language models and LLMs, so capturing multi-granularity compositionality in the text and image to improve the evaluation of composite text-to-image synthesis.
Their method uses language and vision models to convert a picture into multi-granularity (image- and object-level) visual descriptions, enabling us to express the compositional characteristics of numerous objects in language. When reasoning the alignment between text prompts and visuals, they combine these descriptions with text prompts and input them into large language models (LLMs), like GPT-4. Existing metrics struggle to capture compositionality, but their LLMScore does so by detecting the object-level alignment of text and picture (Figure 1). This results in scores that are well associated with human evaluation and have logical justifications (Figure 1).
Additionally, by tailoring the evaluation instruction for LLMs, their LLMScore can adaptively follow different standards (overall or mistake counting). For instance, they may ask the LLMs to rate the overall alignment of the text prompt and the picture to assess the overall objective. Alternatively, they could ask them to confirm the error counting objective by asking, “How many compositional errors are in the image?” To maintain the determinism of the LLM’s conclusion, they also explicitly provide information on the different forms of text-to-image model errors in the assessment instruction. Because of its adaptability, their system may be used for various text-to-image jobs and assessment criteria.
Modern text-to-image models like Stable Diffusion and DALLE are tested in their experimental setup using a variety of datasets, including prompt datasets for general use (MSCOCO, DrawBench, PaintSkills), as well as for compositional purposes (Abstract Concept Conjunction, Attribute Binding Contrast). They conducted numerous trials to confirm using LLMScore and show that it is aligned with human judgments without needing extra training. Across all datasets, their LLMS score had the strongest human correlation. On compositional datasets, they outperform the commonly used metrics CLIP and BLIP, respectively, by 58.8% and 31.27% Kendall’s.
In conclusion, they provide LLMScore, the first effort to demonstrate the effectiveness of large language models for text-to-image assessment. Specifically, their article contributes the following:
• They suggest the LLMScore. This brand-new framework provides scores that precisely express multi-granularity compositionality (image-level and object-level) for evaluating the alignment between text prompts and synthesized pictures in text-to-image synthesis.
• Their LLMScore generates precise alignment scores with justifications following several evaluation directives (overall and mistake counting).
• They use a variety of datasets (both compositional and general purpose) to verify the LLMScore. Among the widely utilized measures (CLIP, BLIP), their suggested LLMScore gets the strongest human correlation.
Check out the Paper and Github Link. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.