Meet LoraHub: A Strategic AI Framework for Composing LoRA (Low-Rank Adaptations) Modules Trained on Diverse Tasks in Order to Achieve Adaptable Performance on New Tasks
Large-scale pretrained language models (LLMs) like OpenAI GPT, Flan-T5, and LLaMA have been substantially responsible for the rapid advancement of NLP. These models perform exceptionally well in a variety of NLP applications. However, problems with computational efficiency and memory utilization arise during fine-tuning due to their massive parameter size.
Recent years have seen the rise of Low-Rank Adaptation (LoRA) as a powerful tool for tuning. It speeds up LLM training by decreasing the amount of memory and computation required. LoRA does this by fixing the parameters of the main model (an LLM) and learning a small, complementary module that reliably performs well on the designated tasks.
The efficiency gains made possible by LoRA have been the focus of previous research, but the modularity and composability of LoRA modules have received very little attention. There has to be research on whether or not LoRA modules can be written to efficiently generalize towards unknown problems.
A group of researchers from Sea AI Lab, Washington University, and Allen Institute for AI decided to use LoRA’s modularity to enable flexible performance on novel challenges instead of limiting themselves to training on a particular task. The key benefit of their approach is that it allows LoRA modules to be assembled automatically without human intervention or specialized knowledge.
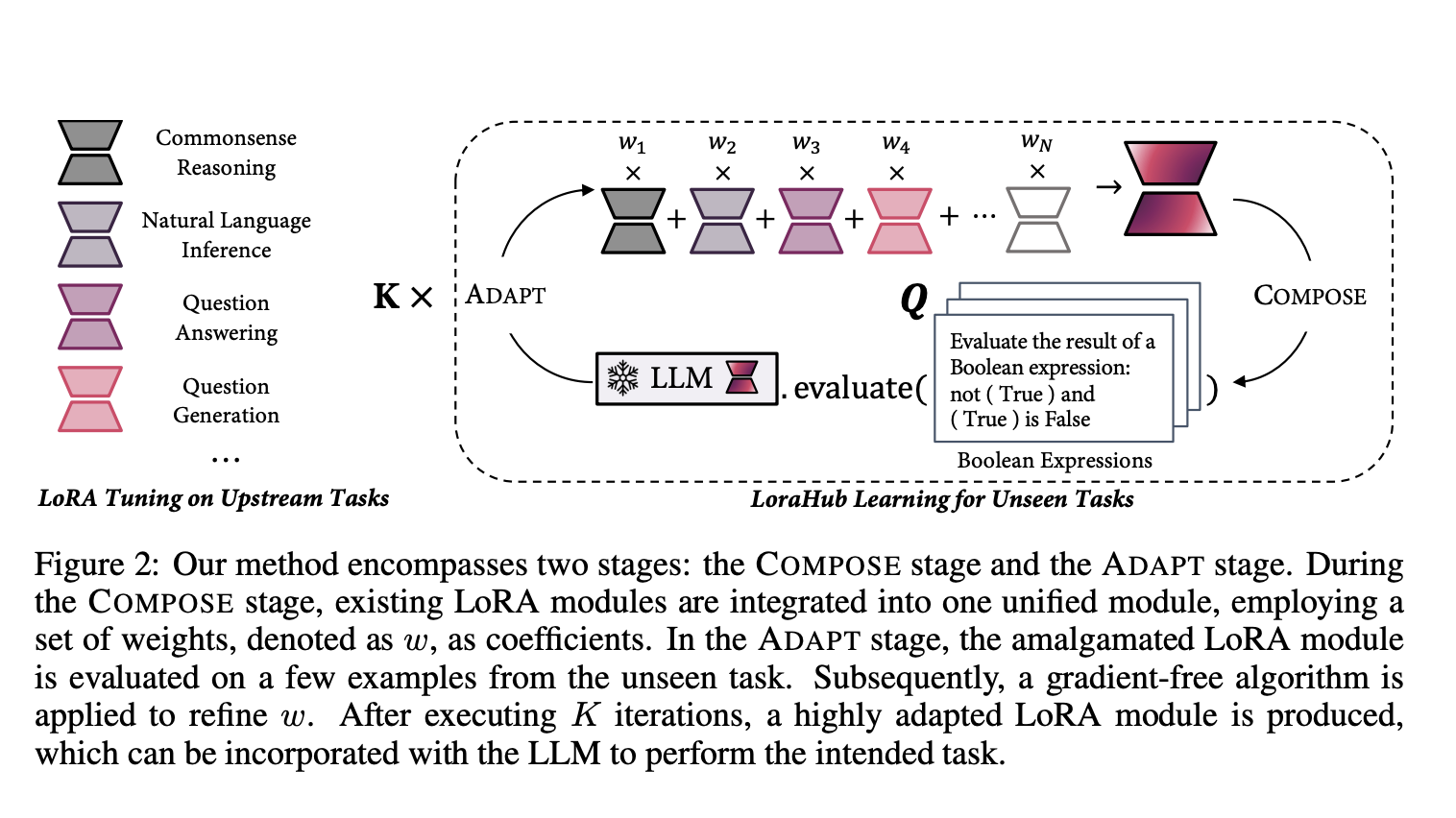
The method can automatically arrange suitable LoRA modules with just a few samples from previously unrecognized tasks. Because the researchers make no assumptions about which LoRA modules trained on which tasks can be integrated, all modules that meet the requirements (e.g., by utilizing the same LLM) are fair game for a merger. They call this technique of learning LoraHub learning since it uses several different LoRA modules already out there.
To ensure their efficacy, the team evaluated their methodologies using the industry-standard BBH benchmark and Flan-T5 as the underlying LLM. The outcomes demonstrate the value of a few-shot LoraHub learning process to compose LoRA modules for novel tasks. Surprisingly, the strategy gets results quite close to few-shot, in-context learning. Eliminating the need for instances as inputs for the LLM also significantly reduces inference costs compared to in-context learning. The learning technique takes a gradient-free approach to generate the coefficients of LoRA modules and only requires a small number of inference steps. In less than a minute, with a single A100, for instance, the approach can achieve top-tier performance on the BBH.
Learning on the LoraHub just needs the knowledge of how to process LLM inference. Therefore, it can be done on a CPU-only computer. This work’s flexibility and high performance pave the way for creating a platform where trained LoRA modules may be easily shared, accessed, and applied to new jobs in this domain. The team hopes that such a system will allow for the development of a library of reusable LoRA modules with a wide range of features. The group is working on dynamically composing LoRA nodes to improve the LLM’s capabilities for everyone.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.