Meet LP-MusicCaps: A Tag-to-Pseudo Caption Generation Approach with Large Language Models to Address the Data Scarcity Issue in Automatic Music Captioning
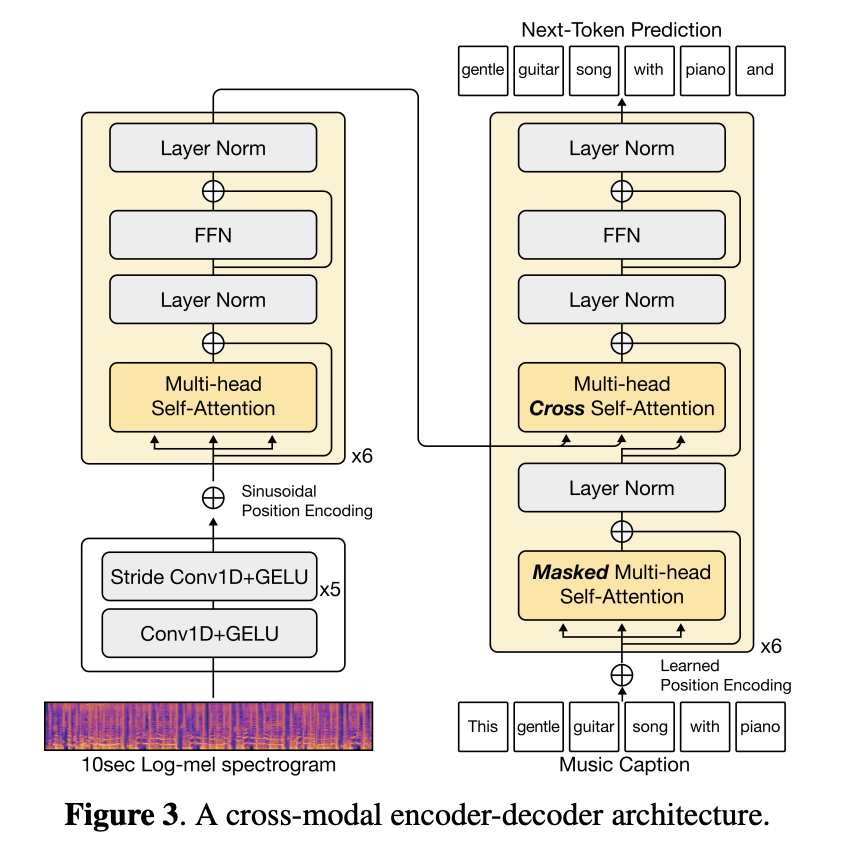
Music caption generation involves music information retrieval by generating natural language descriptions of a given music track. The captions generated are textual descriptions of sentences, distinguishing the task from other music semantic understanding tasks such as music tagging. These models generally use an encoder-decoder framework.
There has been a significant increase in research on music caption generation. But despite its importance, the researchers studying these techniques face hurdles due to dataset collection’s costly and cumbersome task. Also, the limited number of available music-language datasets poses a challenge. With the scarcity of datasets, training a music captioning model successfully doesn’t remain easy. Large language models (LLMs) could be a potential solution for music caption generation. LLMs are cutting-edge models with over a billion parameters and show impressive abilities in handling tasks with few or zero examples. These models are trained on vast amounts of text data from diverse sources like Wikipedia, GitHub, chat logs, medical articles, law articles, books, and web pages crawled from the internet. The extensive training enables them to understand and interpret words in various contexts and domains.
Subsequently, a team of researchers from South Korea has developed a method called LP-MusicCaps (Large language-based Pseudo music caption dataset), creating a music captioning dataset by applying LLMs carefully to tagging datasets. They conducted a systemic evaluation of the large-scale music captioning dataset with various quantitative evaluation metrics used in the field of natural language processing as well as human evaluation. This resulted in the generation of approximately 2.2M captions paired with 0.5M audio clips. First, they proposed an LLM-based approach to generate a music captioning dataset, LP-MusicCaps. Second, they proposed a systemic evaluation scheme for music captions generated by LLMs. Third, they demonstrated that models trained on LP-MusicCaps perform well in both zero-shot and transfer learning scenarios, justifying the use of LLM-based pseudo-music captions.
The researchers started by collecting multi-label tags from existing music tagging datasets. These tags encompass various aspects of music, such as genre, mood, instruments, and more. They carefully constructed task instructions to generate descriptive sentences for the music tracks, which served as inputs (prompts) for a large language model. They opted for the powerful GPT-3.5 Turbo language model to perform music caption generation due to its exceptional performance across various tasks. The training process of GPT-3.5 Turbo involved an initial phase with a vast corpus of data, and it benefited from immense computing power. Subsequently, they did fine-tune using reinforcement learning with human feedback. This fine-tuning process aimed to enhance the model’s ability to interact effectively with instructions.
The researchers compared this LLM-based caption generator with template-based methods (tag concatenation, prompt template ) and K2C augmentation. In the case of K2C Augmentation, when the instruction is absent, the input tag is omitted from the generated caption, resulting in a sentence that may be unrelated to the song description. On the other hand, the template-based model exhibits improved performance because it benefits from the musical context present in the template.
They used the BERT-Score metric to evaluate the diversity of the generated captions. This framework demonstrated higher BERT-Score values, generating captions with more diverse vocabularies. This means that the captions produced by this method give a wider range of language expressions and variations, making them more engaging and contextually rich.
As the researchers continue to refine and enhance their approach, they also look forward to harnessing the power of language models to advance music caption generation and contribute to music information retrieval.
Check out the Paper, Github, and Tweet. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.