Meet ‘Magic3D’: An AI-Based Text-to-3D Content Creation Tool That Creates 3D Mesh Models With Unprecedented Quality
For a wide range of uses, including gaming, entertainment, architecture, and robotics simulation, 3D digital content has been in great demand. It is gradually making its way into almost every conceivable industry, including education, Internet conferencing, shopping, and virtual social presence. But not just anybody can produce great 3D material; it takes extensive training in the arts and aesthetics and 3D modeling skills. These skill sets need considerable time and effort to develop. Using natural language to augment 3D content creation could greatly aid in democratizing 3D content creation for beginners and accelerating professional artists.
With the development of diffusion models for the generative modeling of pictures, there has been a major advancement in the production of visual content from text cues. The main enablers are vast quantities of computing, and large-scale databases made up of billions of samples (pictures with text) taken from the Internet. In comparison, the creation of 3D content has advanced far more slowly. Most 3D object creation models now in use are categorized. A trained model can only synthesize objects for one class, though recent research by Zeng et al. suggests that it may eventually scale to multiple classes. As a result, there are many restrictions on what a user can do with these models, making them unsuitable for artistic creation.
This constraint is mostly brought about by the scarcity of varied, large-scale 3D datasets; 3D content is harder to get online than picture and video content. This naturally prompts the issue of whether utilizing potent text-to-image generating models may be used to obtain 3D generation capacity. In a recent demonstration, DreamFusion used a pre-trained text-to-image diffusion model that creates pictures as strong images before showing off its impressive capacity for text-conditioned 3D content synthesis. The 3D representation underneath is improved with the help of the diffusion model. The optimization procedure makes sure that, given the input word prompt, the distribution of photorealistic pictures across various views matches the produced images from a 3D model represented by Neural Radiance Fields (NeRF).
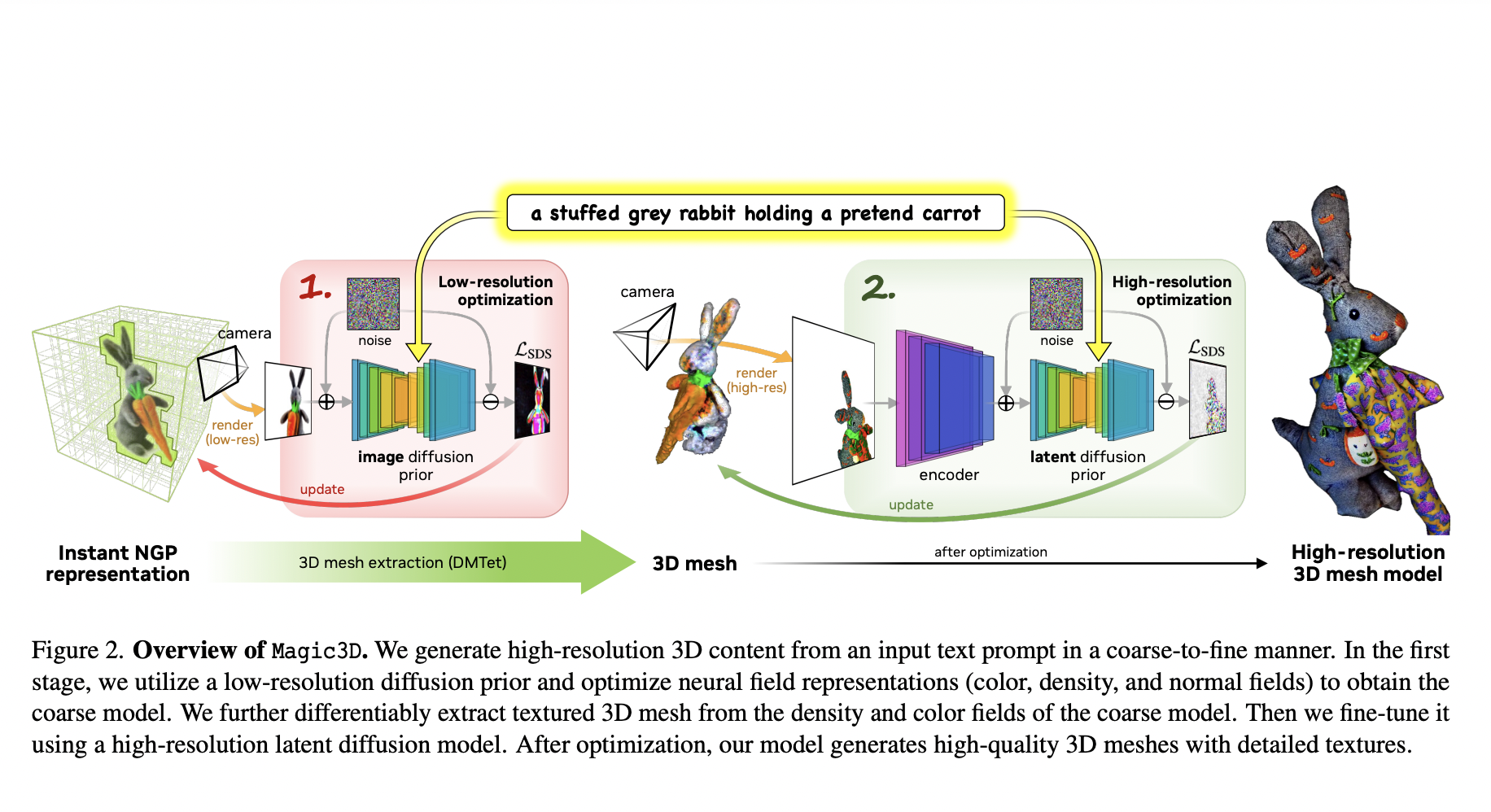
DreamFusion cannot synthesize high-frequency 3D geometric and textural features since its supervision signal only work with pictures with a resolution of 64 x 64. Practical high-resolution synthesis may not even be viable due to the NeRF representation’s usage of inefficient MLP topologies since the necessary memory footprint and the compute budget increase rapidly with resolution. Even at 64 x 64, optimization times are measured in hours (1.5 hours per prompt on average using TPUv4). In this study, they offer a method for quickly creating 3D models from text prompts that are extremely precise. To improve the 3D representation, they specifically provide a coarse-to-fine optimization technique that uses several diffusion priors at various resolutions. This approach enables the production of both view-consistent geometry and high-resolution features.
Using a memory- and compute-efficient scene representation based on a hash grid, they first optimize a coarse neural field representation similar to DreamFusion. The second stage involves switching to mesh optimization, which is essential since it enables us to use diffusion priors at resolutions as high as 512 512. They employ an effective differentiable rasterizer and camera close-ups to recover high-frequency features in geometry and texture because 3D models are suitable for fast graphics renderers that can produce high-resolution pictures in real-time. As a result, their method generates high-fidelity 3D material at double the speed of DreamFusion, which can easily be imported and viewed in common graphics applications.

They also demonstrate a variety of creative controls over the 3D synthesis process by utilizing innovations created for text-to-image editing software. By giving people unprecedented power over creating their desired 3D objects via text prompts and reference photos, their method, nicknamed Magic3D, moves this technology one step closer to democratizing the creation of 3D content. In conclusion, their study contributes the following:
• They improve numerous key DreamFusion design decisions to present Magic3D, a framework for high-quality 3D content creation via text prompts. The 3D representation of the target material is learned using a coarse-to-fine technique that uses both low- and high-resolution diffusion priors. DreamFusion is two times slower than Magic3D, which creates 3D material with an eight higher resolution supervision. Users greatly prefer the 3D content created by their method (61.7%).
• They expand several picture editing methods created for text-to-image models to 3D object editing and demonstrate their use in the suggested framework.
Demonstrations can be seen on their website.
Check out the Paper and Project Page. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.