Meet MAGVIT: A Novel Masked Generative Video Transformer To Address AI Video Generation Tasks

Artificial intelligence models are recently becoming very powerful due to the increase in the dataset size used for the training process and in computational power necessary to run the models.
This increment in resources and model capabilities usually leads to a higher accuracy than smaller architectures. Small datasets also impact the performance of neural networks similarly, given the small sample size compared to the data variance or unbalanced class samples.
While the model capabilities and accuracy rise, in these cases, the tasks performed are restricted to very few and specific ones (for instance, content generation, image inpainting, image outpainting, or frame interpolation).
A novel framework referred to as MAsked Generative VIdeo Transformer,
MAGVIT (MAGVIT), including ten different generation tasks, has been proposed to overcome this limitation.
As reported by the authors, MAGVIT was developed to address Frame Prediction (FP), Frame Interpolation (FI), Central Outpainting (OPC), Vertical Outpainting (OPV), Horizontal Outpainting (OPH), Dynamic Outpainting (OPD), Central Inpainting (IPC), and Dynamic Inpainting (IPD), Class-conditional Generation (CG), Class-conditional Frame Prediction (CFP).
The overview of the architecture’s pipeline is presented in the figure below.
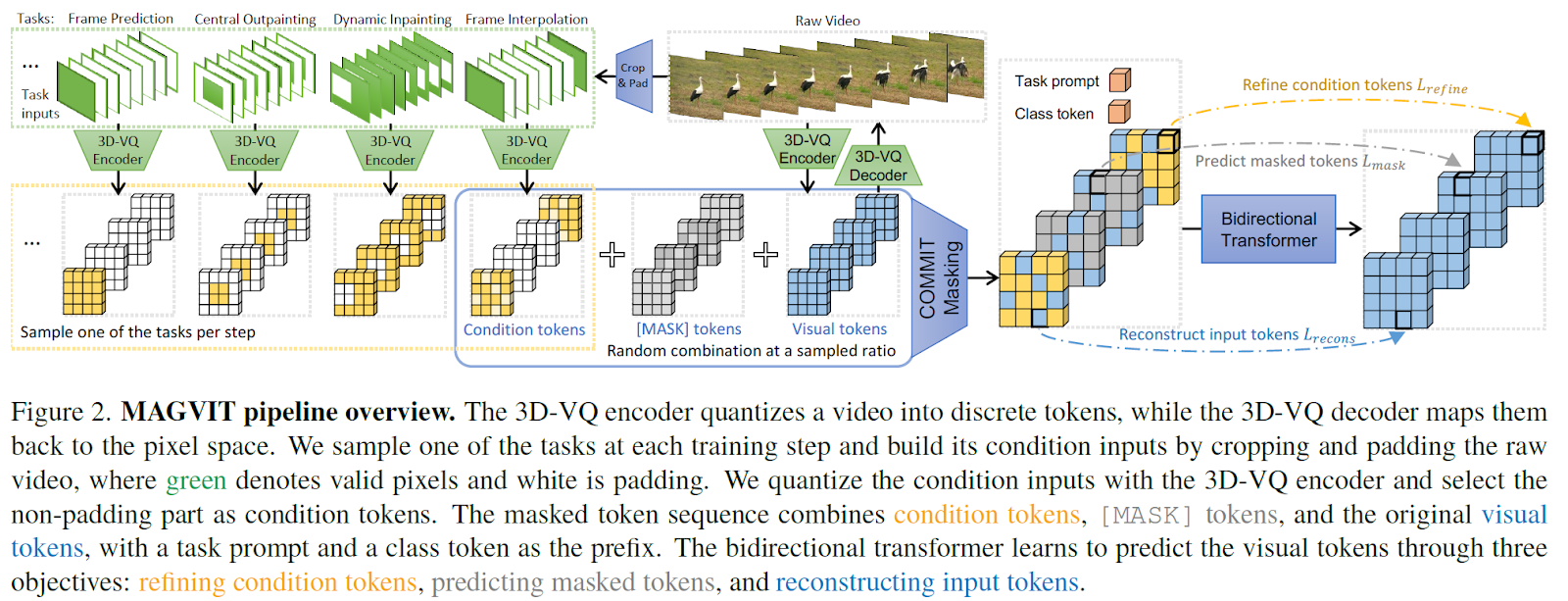
In a nutshell, the idea behind the proposed framework is to train a transformer-based model to retrieve a corrupted image. The corruption is here modeled as masked tokens, which refer to portions of the input frame.
Specifically, MAGVIT models a video as a sequence of visual tokens in the latent space and learns to predict masked tokens with BERT (Bidirectional Encoder Representations from Transformers), a transformer-based machine learning approach originally designed for natural language processing (NLP).
There are two main modules in the proposed framework.
First, vector embeddings (or tokens) are produced by 3D vector-quantized (VQ) encoders, which quantize and flatten the video into a sequence of discrete tokens.
2D and 3D convolutional layers are exploited together with 2D and 3D upsampling or downsampling layers to account for spatial and temporal dependencies efficiently.
The downsampling is performed by the encoder, while the upsampling is implemented in the decoder, whose goal is to reconstruct the image represented by the vector token provided by the encoder.
Second, a masked token modeling (MTM) scheme is exploited for multitask video generation.
Unlike conventional MTM in image/video synthesis, an embedding method is proposed to model a video condition using a multivariate mask.
The multivariate masking scheme facilitates learning for video generation tasks with different conditions.
The conditions can be a spatial region for inpainting/outpainting or a few frames for frame prediction/interpolation.
The output video is generated according to the masked conditioning token, refined at each step after prediction is performed.
Based on reported experiments, the authors of this research claim that the proposed architecture establishes the best-published FVD (Fréchet Video Distance) on three video generation benchmarks.
Furthermore, according to their results, MAGVIT outperforms existing methods in inference time by two orders of magnitude against diffusion models and by 60× against autoregressive models.
Lastly, a single MAGVIT model has been developed to support ten diverse generation tasks and generalize across videos from different visual domains.
In the figure below, some results are reported concerning class-conditioning sample generation compared to state-of-the-art approaches. For the other tasks, please refer to the paper.

This was the summary of MAGVIT, a novel AI framework to address various video generation tasks jointly. If you are interested, you can find more information in the links below.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.