Meet MathPile: A Diverse and High-Quality Math-Centric Corpus Comprising About 9.5 Billion Tokens
Advanced conversational models like ChatGPT and Claude are causing significant shifts in various products and everyday life. The key factor contributing to their success lies in the robustness of the foundational language model. Cutting-edge foundational models are typically pre-trained using extensive, diverse, and high-quality datasets encompassing various sources such as Wikipedia, scientific papers, community forums, Github repositories, web pages, and more. These foundational language models are expected to possess well-rounded capabilities, including language understanding, common-sense reasoning, mathematical reasoning, language generation, and more.
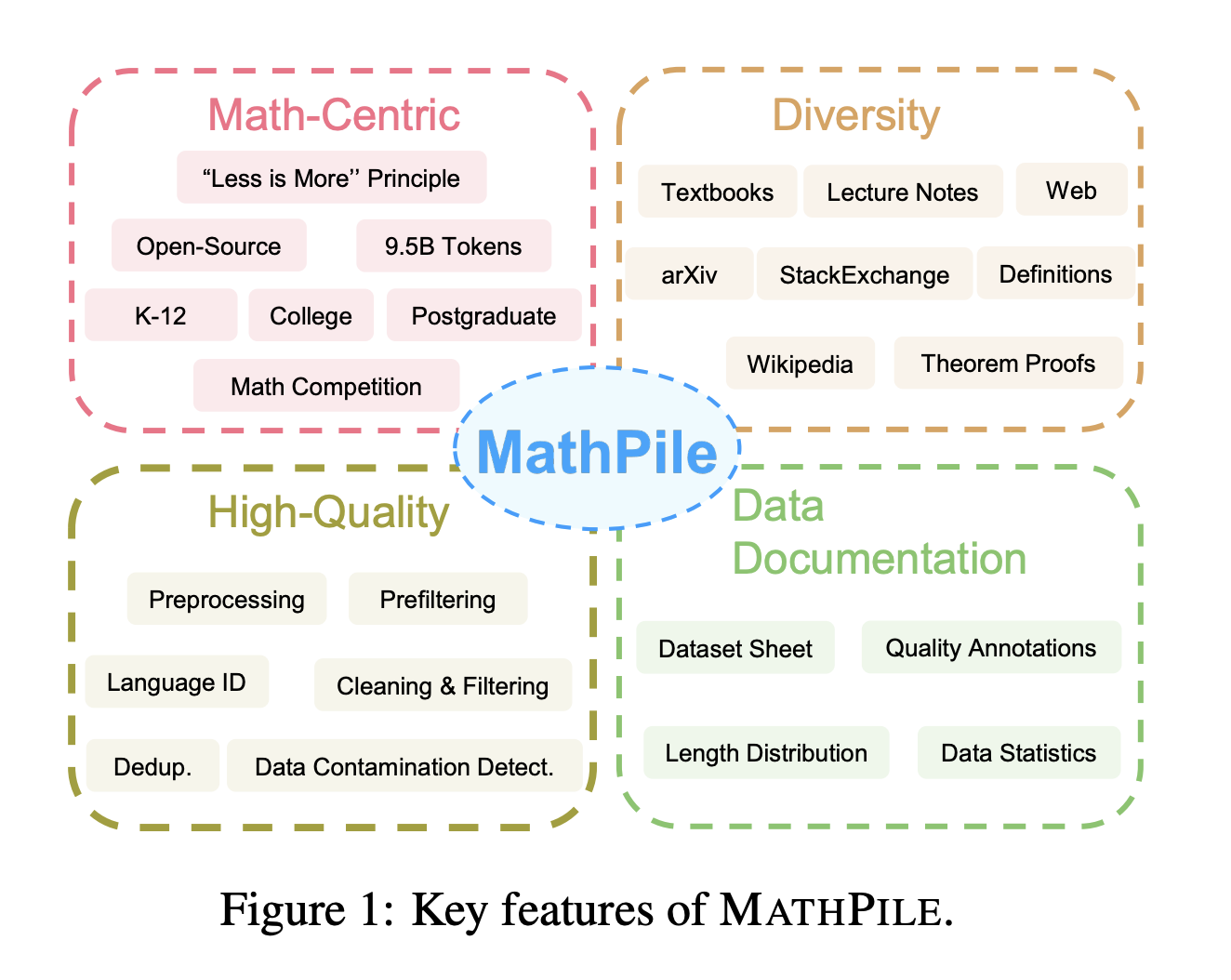
A new study by Shanghai Jiao Tong University, Shanghai Artificial Intelligence Laboratory, Nanjing University of Science and Technology, and Generative AI Research Lab (GAIR) focuses on enhancing the mathematical reasoning capabilities within foundational language models, which could potentially enhance applications in education tools, automated problem-solving, data analysis, code programming, and ultimately enhance user experience. Instead of directly constructing a model, the focus is creating a high-quality and diverse pre-training dataset specifically tailored for the math domain, MATHPILE.
This approach stands out from previous work in several aspects. Prior open-source pre-training datasets have typically centered on general domains (e.g., Pile, RedPajama, Dolma), multilingual aspects, or programming languages (e.g., ROOTS and The Stack), lacking a corpus specifically tailored for mathematics. Although some datasets are designed for training math-specific language models (e.g., Minerva’s mathematical training dataset and OpenAI’s MathMix), these are not available openly.
Acknowledging this gap, this work aims to bridge this divide by developing an open-sourced mathematical corpus, democratizing access to high-quality mathematical data. This initiative enables researchers and developers to effectively and inclusively advance the capabilities of language models in mathematical reasoning. Regarding diversity, the corpus goes beyond web pages, integrating top-notch mathematics textbooks, lecture notes, scientific papers from arXiv, and carefully selected content from authoritative platforms like StackExchange, ProofWiki, and Wikipedia. This positions the corpus as a richer and more varied mathematical resource for language models.
The researchers emphasize high quality due to recent studies highlighting the adverse effects of low-quality and repetitive content in pre-training datasets on model training. For instance, creating a 1.3 billion-parameter code-focused model was achieved by pre-training on carefully curated web pages and synthetic textbooks. It’s underscored that the quality of the corpus is more crucial than its quantity. To achieve this, the researchers undertook extensive preprocessing, cleaning, filtering, and deduplication efforts, committed to continuous refinement and optimization to contribute distinctively to mathematics.
The team highlights that transparency and documentation are key aspects. Thoroughly documenting large-scale pre-training datasets is crucial to identifying biases or problematic content. MATHPILE provides comprehensive documentation, including characteristics, intended uses, and efforts to eliminate biases or unwanted content to enhance trust and usability among practitioners.
This initiative aims to foster AI growth in mathematics by offering a specialized, high-quality, and diverse corpus tailored for the mathematical domain while maintaining absolute transparency in data for practitioners. The team hopes that their work helps lay the foundation for training more powerful mathematical problem-solving models in the future.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.